- 판다스 불러오기
import pandas as pd | cs |
- 데이터 파일 불러오기
emp = pd.read_csv('C:\폴더\파일이름.csv') | cs |
- 데이터 헤드 보기
emp.head(10) | cs |
- 특정 기준으로 조회
# 샐러리가 10000 초과
emp[emp['SALARY'] > 10000]- 컬럼 만들기
# 연봉 컬럼 만들기: 샐러리 * 12 emp['연봉'] = emp['SALARY'] * 12 | cs |
다시 데이터프레임 확인하기
emp.head(10) | cs |
- 특정 기준으로 특정 테이블 출력
#문제. 연봉이 200000 이상인 대상 중 사원번호, 연봉, 이름을 출력하는 코드 작성 emp[['EMPLOYEE_ID', '연봉', 'FIRST_NAME', 'LAST_NAME']] | cs |
emp[emp['연봉'] >= 200000][['EMPLOYEE_ID', '연봉', 'FIRST_NAME', 'LAST_NAME']] | cs |
- 복합조건
*주의사항: 괄호를 잘 넣었는지 확인해야 한다.
# 복합조건: 괄호 넣기! emp[(emp['연봉'] >= 200000) & (emp['연봉'] <= 250000) ][['EMPLOYEE_ID', '연봉', 'FIRST_NAME', 'LAST_NAME']] | cs |
e1 = emp[emp['연봉'] >= 200000] | cs |
e1[['EMPLOYEE_ID', '연봉', 'FIRST_NAME', 'LAST_NAME']] | cs |
- 부서번호가 10번이거나 20번에 해당하는 데이터만 출력
#디파트먼트아이디(부서번호)가 10번 이거나 20번에 해당하는 데이터만 출력 emp.head(2) | cs |
#하나의 조건으로만 출력하기 e2 = emp[emp['DEPARTMENT_ID'] == 10.0] e2 | cs |
- 연산자를 활용하여 복합조건 출력
# | : 시프트+ 1 (또는) & (그리고) : 시프트 + 7 emp[(emp['DEPARTMENT_ID'] == 10.0) | (emp['DEPARTMENT_ID'] == 20.0) | (emp['DEPARTMENT_ID'] == 50.0) | (emp['DEPARTMENT_ID'] == 80.0)] | cs |
isin을 활용한 데이터 출력
# isin 을 활용해서 부서번호 10번만 출력하기 emp.loc[emp['DEPARTMENT_ID'].isin([10.0])] | cs |
10-1. job_id 중 특정 이름만 출력
emp.loc[emp['DEPARTMENT_ID'].isin([10.0, 20.0, 50.0, 80.0])] | cs |
- 비교 연산자를 사용한 데이터 추출
#비트윈: 샐러리 15000 이상 ~ 20000 이하 #비교 연산자 사용 emp[(emp['SALARY'] >= 15000) & (emp['SALARY'] <= 20000)] | cs |
11-1. 기본적으로 both 조건으로 구성됨
# between 함수: 기본적으로 both(이상, 이하)로 구성됨. 조건 변경 가능 inclusive='both' 써도 되고 안써도 됨 emp[emp['SALARY'].between(10000, 14000)] | cs |
11-2. 조건에 따라 결과값이 달라짐
## 10000 초과 11000 이하 emp[emp['SALARY'].between(10000,11000, inclusive = 'right')] ## 10000 이상 11000 미만 emp[emp['SALARY'].between(10000,11000, inclusive = 'left')] ## 10000 이상 11000 이하 emp[emp['SALARY'].between(10000,11000, inclusive = 'both')] ## 10000 초과 11000 미만 emp[emp['SALARY'].between(10000,11000, inclusive = 'neither')] | cs |
loc을 통한 특정 열 데이터프레임 추출
# 특정 열 데이터프레임 추출 emp.loc[emp['SALARY'].between(10000,11000, inclusive = 'neither'), ['SALARY']] | cs |
집계하기
- 합계, 평균, 최소, 최대, 개수 구하기
#집계 #컬럼 전체의 합계 emp['SALARY'].sum() #컬럼 전체의 평균 emp['SALARY'].mean() #컬럼 전체의 최소 emp['SALARY'].min() #컬럼 전체의 최대 emp['SALARY'].max() emp['SALARY'].count() | cs |
groupby를 통한 기준별 집계
#기준별 집계: 특정 기준으로 집계할 때 사용 emp.groupby('DEPARTMENT_ID')['DEPARTMENT_ID'].count() emp.groupby('DEPARTMENT_ID')[['SALARY']].sum() emp.groupby('DEPARTMENT_ID')[['DEPARTMENT_ID']].count() | cs |
2-2. emp에 JOB_ID 별 평균 샐러리를 구하는 코드 구하기
emp.groupby('JOB_ID')[['SALARY']].mean() | cs |
2-3. 인덱스 번호 부여
# as_index: 인덱스 번호 보여주기 # 인덱스 번호 부여 'JOB_ID' 는 컬럼으로 변경 emp.groupby('JOB_ID', as_index = False)[['SALARY']].sum() | cs |
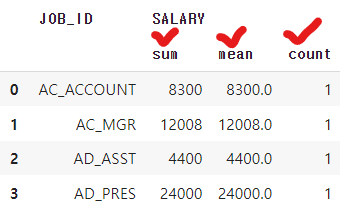
agg를 통한 집계 한꺼번에 하기
# 건수, 합계, 평균 동시에 구하기: agg(['리스트']) emp.groupby('JOB_ID', as_index = False)[['SALARY']].agg(['sum', 'mean', 'count']) | cs |

관심분야: 추천시스템, 자연어처리, 머신러닝, 딥러닝