패키지를 통해 자료 불러오기
상관계수 및 공분산
증권 자료를 pandas-datareader 패키지를 이용해서 내려받을 수 있다.
conda install pandas-datareaderpandas_datareader 모듈을 이용해서 4개 회사 거래 자료를 내려받는다.
import pandas_datareader as web
import pickle
all_data = {ticker: web.get_data_quandl(ticker) for ticker in ['AAPL', 'IBM', 'MSFT', 'GOOG']}미리 저장된 파일을 다음 사이트에서 내려받아 사용한다.
import pickle
from urllib import request
url = "http://compmath.korea.ac.kr/appmath/data/stock_example.dat"
with request.urlopen(url) as f:
all_data = pickle.loads(f.read())자료 구조 살피기
내려받은 자료 구조를 살펴보자.
all_data의 자료형은 사전임을 알 수 있다.
type(all_data)dictall_data의 열쇠(key)를 살펴보면 다음과 같다.
all_data.keys()dict_keys(['AAPL', 'IBM', 'MSFT', 'GOOG'])첫번째 열쇠에 대응되는 값을 살펴보자.
다음에서 보는 바와 같이 판다스 데이터프레임임을 알 수 있다.
aapl = all_data['AAPL']
type(aapl)pandas.core.frame.DataFrame데이터프레임의 구조를 보자.
pd.set_option('display.max_rows', 10)
aapl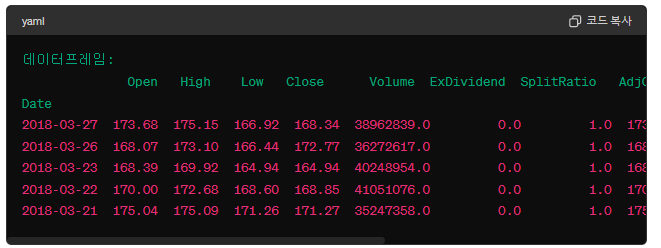
수정 종가(AdjClose)와 거래량(Volume) 자료를 추출하자.
import pandas as pd
adj_close = pd.DataFrame({ticker: data['AdjClose'] for ticker, data in all_data.items()})
volume = pd.DataFrame({ticker: data['Volume'] for ticker, data in all_data.items()})adj_closevolume백분율
General Motors(GM), Coca Cola(KO), AT & T(T), Intel(INTC) 주식 자료를 다운받아 data 변수에 저장
(만일 다운이 안되면 ‘http://compmath.korea.ac.kr/appmath/data/stock_GM_KO_T_INTC.dat’를 이용)
data로부터 Open과 Close 값을 각각 st_open, st_close 변수에 저장
시계열 부분에서 자세히 살펴볼 차의 백분율(percent change)을 계산하면 다음과 같다.
pct_ch = adj_close.pct_change()
pct_ch.tail() AAPL GOOG IBM MSFT
Date
2018-03-21 -0.022655 -0.006222 0.003137 -0.006979
2018-03-22 -0.014159 -0.038318 -0.029357 -0.029087
2018-03-23 -0.023128 -0.026223 -0.021040 -0.029068
2018-03-26 0.047472 0.030972 0.030089 0.075705
2018-03-27 -0.025641 -0.045679 -0.009519 -0.045959상관계수: corr, cov
시리즈 메소드 corr을 통하여
NA가 아닌 자료들에 대한 상관계수를 구할 수 있다.
pct_ch['MSFT'].corr(pct_ch['IBM'])0.47906169687685296마찬가지로 cov 메소드를 이용해서 공분산을 구한다.
pct_ch['MSFT'].cov(pct_ch['IBM'])8.141169232110642e-05열에 대한 상관계수 전체 계산
데이터프레임의 corr, cov 메소드는 각 열에 대한 상관계수 전체를 계산한다.
pct_ch.corr() AAPL GOOG IBM MSFT
AAPL 1.000000 0.433070 0.365634 0.410778
GOOG 0.433070 1.000000 0.374787 0.599392
IBM 0.365634 0.374787 1.000000 0.479062
MSFT 0.410778 0.599392 0.479062 1.000000주의사항
pct_ch.cov() 입력하면 오류가 난다.
pct_ch.cov()---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-157-de587e26bcb4> in <module>()
----> 1 pct_ch.cov()
NameError: name 'pct_ch' is not defined다른 데이터프레임 상관관계 계산: corrwith
데이터프레임의 corrwith 메소드를 이용하면
데이터프레임의 열 또는 행을
다른 데이터프레임(또는 시리즈)의 짝을 찾아
상관관계를 계산할 수 있다.
인자로 시리즈를 건네면 데이터프레임의 각 열과 상관관계를 계산하여 시리즈 형으로 반환한다.
pct_ch.corrwith(pct_ch.IBM)AAPL 0.365634
GOOG 0.374787
IBM 1.000000
MSFT 0.479062
dtype: float64행에 대한 상관관계 계산: axis='columns
선택인자 axis='columns'를 사용하여 행 에 대해서 상관관계를 계산한다.
pct_ch.corrwith(volume, axis='columns')Date
2010-01-04 NaN
2010-01-05 0.698721
2010-01-06 0.289461
2010-01-07 -0.911877
2010-01-08 -0.658798
...
2018-03-21 -0.843804
2018-03-22 0.758479
2018-03-23 -0.403013
2018-03-26 0.963553
2018-03-27 -0.362487
Length: 2071, dtype: float64