중복된 이름을 가진 인덱스
reindex와 같이 대부분의 메소드들은 열, 행이름들이 유일해야하지만 필수는 아니다.
다음과 같이 시리즈의 인덱스 이름으로 중복된 이름 a를 가질 수 있다.
시 = pd.Series(np.arange(5), index=list('abcda'))
시a 0
b 1
c 2
d 3
a 4
dtype: int32중복된 이름에 대한 반환값은 다음과 같이 시리즈 형이고
중복되지 않은 인덱스 이름의 반환값은 스칼라 임을 알 수 있다.
시['a']a 0
a 4
dtype: int32시['b']1인덱스가 유일한지 판단하기: is_unique
인덱스가 유일한지 아닌지를 판단할 수 있는 방법 중의 하나로 인덱스의 속성인 is_unique를 이용할 수 있다.
시.index.is_uniqueFalse데이터프레임
데 = pd.DataFrame(np.arange(3 * 4).reshape(3, 4), index=list('aba'))
데 0 1 2 3
a 0 1 2 3
b 4 5 6 7
a 8 9 10 11데.loc['a'] 0 1 2 3
a 0 1 2 3
a 8 9 10 11기술통계량 계산, 요약
판다스 객체는 공통적으로 사용되는 수학 또는 통계 메소드들을 갖추고 있다.
대부분은 시리즈 또는 데이터프레임의 행, 열로부터 평균 또는
합과 같은 스칼라 값을 뽑아 내는 요약 통계의 범주에 해당한다.
데 = pd.DataFrame([[1.5, np.nan], [7.1, -4.5], [np.nan, np.nan], [0.75, -1.3]], index=list('abcd'), columns=['하나','둘'])
데 하나 둘
a 1.50 NaN
b 7.10 -4.5
c NaN NaN
d 0.75 -1.3합계.sum()
데이터프레임의 sum 메소드는 열에 대한 합을 시리즈로 반환한다.
데.sum()하나 9.35
둘 -5.80
dtype: float64행에 대한 합계 반환
axis='columns' 또는 axis=1 인자를 추가하면
행에 대한 합을 반환한다.
데.sum(axis='columns')
a 1.50
b 2.60
c 0.00
d -0.55
dtype: float64NA 값 계산: skipna= (스킵엔에이)
NA 값들은 계산할 때 기본적으로 제외된다.
skipna= 인자를 추가함으로 계산 시 적용할 수 있다.
데.sum(axis='columns', skipna=False)a NaN
b 2.60
c NaN
d -0.55
dtype: float64가장 큰 값과 작은 값: idxmin, idxmax
idxmin 또는 idxmax 메소드는
주어진 축의 값중 가장 큰 값 또는 가장 작은 값을 포함하는 인덱스 이름을 반환한다.
데.idxmax()하나 b
둘 d
dtype: object각각의 열 중에서 가장 큰 값을 포함하고 있는 행 이름을 각각 반환한 것을 볼 수 있다.
누적 통계량: cumsum()
누적 통계량 메소드로는 cumsum() 가 있다.
데.cumsum() 하나 둘
a 1.50 NaN
b 8.60 -4.5
c NaN NaN
d 9.35 -5.8각 열에 대해서 각 행까지 누적해서 더한 값들을 적고 있다.
또 한번에 여러 개의 통계량을 보여주는 describe() 메소드가 있다.
데.describe() 하나 둘
count 3.000000 2.000000
mean 3.116667 -2.900000
std 3.469990 2.262742
min 0.750000 -4.500000
25% 1.125000 -3.700000
50% 1.500000 -2.900000
75% 4.300000 -2.100000
max 7.100000 -1.300000요약 통계 관련 메소드
count: NA가 아닌 값의 개수
describe: 시리즈나 각 데이터프레임 열에 대한 요약 통계량 계산
min, max: 최소값 및 최대값 계산
argmin, argmax: 최소값 또는 최대값이 발생하는 인덱스 위치(정수) 계산. 정수로 반환함
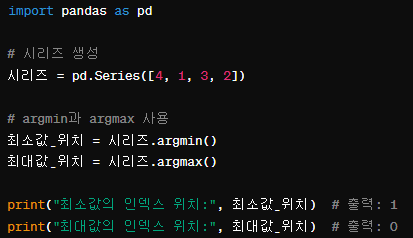
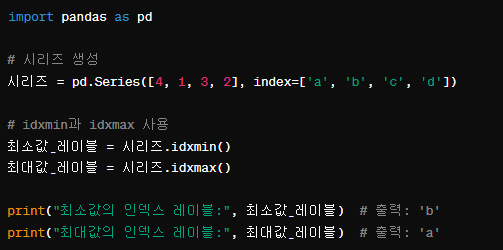
idxmin, idxmax: 최소값 또는 최대값이 발생하는 인덱스 레이블 계산. 레이블로 반환함
quantile: 0에서 1까지의 샘플 분위수 계산
sum: 값들의 합계
mean: 값들의 평균
median: 값들의 중앙값 (50% 분위수)
mad: 평균값으로부터의 절대 편차
prod: 모든 값들의 곱
var: 값들의 표본 분산
std: 값들의 표본 표준 편차
skew: 값들의 표본 왜도 (세 번째 모멘트)
kurt: 값들의 표본 첨도 (네 번째 모멘트)
diff: 첫 번째 산술 차이 계산 (시계열에 유용)
pct_change: 백분율 변화 계산
누적 관련 메소드
cumsum: 값들의 누적 합계
cummin, cummax: 값들의 누적 최소값 또는 최대값
cumprod: 값들의 누적 곱
