1. 범용함수 연산
판다스는 넘파이 범용함수(ufunc; 성분끼리 연산)를 사용할 수 있다.
rng = np.random.RandomState(1234)
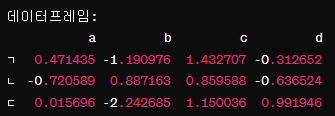
데 = pd.DataFrame(rng.randn(3 * 4).reshape(3, 4), columns=list('abcd'), index=list('ㄱㄴㄷ'))
데이런 출력이 나온다.
np.random.RandomState(n)
시드 값 1234를 사용하여 랜덤 상태 객체 rng를 생성해보자.
이 객체를 사용하면 재현 가능한 랜덤 숫자 생성을 할 수 있다.
rng.randn(n * m)
표준 정규분포에서 n*m개의 랜덤 숫자를 생성한다.
.reshape(3, 4): 이 숫자들을 3x4 형태의 배열로 변환한다.
pd.DataFrame()을 사용하여 데이터프레임을 생성한다.
열 이름(columns)은 'a', 'b', 'c', 'd' 으로,
행 이름(index)은 'ㄱ', 'ㄴ', 'ㄷ'으로 지정한다.
절대값 변환: np.abs(이름)
이 값들을 절대값으로 변환해보자.
np.abs(데)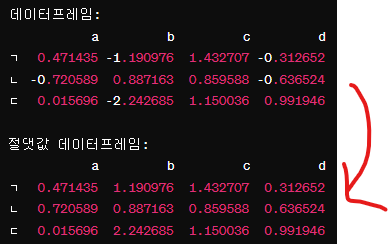
랜덤 상태 객체 rng를 사용하여 3x4 크기의 랜덤 값을 가지는 데이터프레임 데를 생성한다.
np.abs(데)를 통해
데이터프레임 데의 모든 요소에 대해 절댓값을 계산한다.
각 요소가 음수이면 양수로 변환되고, 양수는 그대로 유지된다.
apply(이름)
데이터프레임의 행 또는 열 벡터에 적용할 수 있는 apply 메소드가 있다.
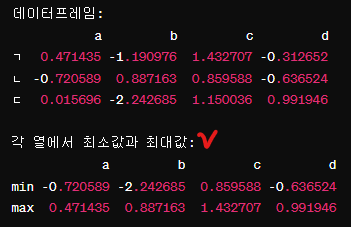
각 열에서 최대값과 최소값의 차이 구하기
f = lambda x : x.max() - x.min()
데.apply(f)주어진 데이터프레임 데에 대해 각 열(column)마다 최대값과 최소값의 차이를 계산하는 람다 함수 f를 적용한다.
람다 함수 f는 입력된 시리즈 x에 대해 최대값과 최소값의 차이를 반환한다.
이 코드를 실행하면 다음과 같은 출력이 나온다.

apply 메서드는 기본적으로 열 단위로 함수를 적용하므로, 각 열에서 최대값과 최소값의 차이가 계산된다.
결과는 시리즈 형태로 반환되며,
각 열의 이름과 최대값과 최소값의 차이를 포함한다.
각 행에서 최대값과 최소값의 차이 구하기
데.apply(f, axis='columns')함수 f는 배열 x의 최대값에서 최소값을 뺀 값을 반환한다.
기본적으로 데이터프레임.apply(함수) 하면
데이터프레임의 열 벡터에 함수를 적용한다.
만약 axis='columns'을 입력하면
각 행에 대해서 함수를 적용할 수 있다.

각 행에서 최대값과 최소값의 차이 구하기
sum, mean 과 같은 데이터프레임 메소드들은 apply를 사용할 필요가 없다.
함수의 반환값으로 스칼라뿐 아니라 여러 값을 갖는 시리즈도 될 수 있다.
# 함수 정의: 각 열에서 최소값과 최대값을 시리즈로 반환
def g(x):
return pd.Series([x.min(), x.max()], index=['min', 'max'])
# 데이터프레임의 각 열에 함수 적용
데.apply(g)
함수 정의
함수 g는 입력된 시리즈 x에 대해 최소값과 최대값을 계산하여 시리즈 형태로 반환한다.
반환된 시리즈는 'min'과 'max'라는 인덱스를 가진다.
데이터프레임의 각 열에 함수 적용
데.apply(g)는 데이터프레임 데의 각 열에 대해 함수 g를 적용한다.
결과는 각 열의 최소값과 최대값을 포함하는 새로운 데이터프레임이 된다.
새로운 데이터프레임의 인덱스는 'min'과 'max'이며, 각 열에는 해당 열의 최소값과 최대값이 포함된다.
applymap(이름)과 람다 함수 포맷
applymap 메소드를 이용하면 성분에 대한 연산을 하는 함수를 사용할 수 있다.
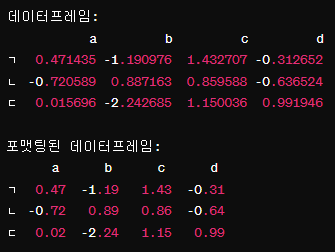
다음과 같이 각 성분 숫자를 소수점 2자리만 표시되는 함수를 만들어 보자.
다음은 주어진 데이터프레임 데의 모든 요소에 대해 포맷팅을 적용하는 람다 함수 포맷을 사용하는 코드이다.
포맷 = lambda x : '{:.2f}'.format(x)
데.applymap(포맷)람다 함수 포맷
입력된 숫자 x를 소수점 둘째 자리까지 문자열로 포맷팅한다.
각 요소가 포맷팅되어 소수점 둘째 자리까지 문자열로 변환된다.
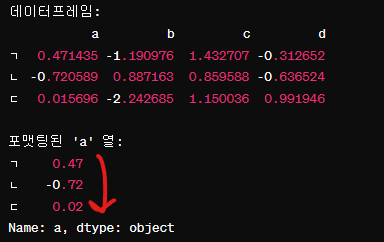
map 메소드
데['a'].map(포맷)applymap는 시리즈에 map 메소드가 있어서
각 성분에 대해서 함수를 적용할 수 있다.
각 열에 대해서 map을 적용한다.
map 메서드를 사용하여 특정 열의 모든 요소에 함수를 적용한다.
데['a'].map(포맷)은 데이터프레임 데의 'a' 열의 모든 요소에 대해 포맷팅 함수를 적용한다.
각 요소가 포맷팅되어 소수점 둘째 자리까지 문자열로 변환된다.