정렬 및 순위(Sorting and Ranking)
데이터프레임 만들기
np.arange(3 * 4)는 0 ~ 11 까지의 숫자를 생성한다.
.reshape(3, 4)는 이 숫자들을 3x4 형태의 배열로 변환한다.
pd.DataFrame()을 사용하여 데이터프레임을 생성하며,
열 이름(columns)은 'ㄴ', 'ㄱ', 'ㄹ', 'ㄷ',
행 이름(index)은 'd', 'a', 'b'로 지정한다.
프 = pd.DataFrame(np.arange(3 * 4).reshape(3, 4), columns=list('ㄴㄱㄹㄷ'), index=list('dab'))
프
자료 정렬: sort_index
행 또는 열이름에 대해서 자료를 정렬하려면 sort_index 메소드를 사용하면 된다.
sort_index 는 기본적으로 행 이름 에 대해서 정렬을 한다.
프.sort_index()
프.sort_index()는 데이터프레임 프의 인덱스를 기준으로 오름차순 으로 정렬된다.
프.sort_index(axis='columns')열 이름으로 정렬하기
열 이름에 대해서 정렬을 하고 싶으면 axis='columns'를 사용한다.

자료는 기본적으로 오름차순 으로 정렬이 된다.
내림차순 으로 정렬을 하고 싶으면 ascending=False 인자를 사용한다.
프.sort_index(axis=1, ascending=False)
시리즈 값에 의한 정렬
시리즈 값에 의한 정렬을 원하면 sort_values 메소드를 사용한다.
시 = pd.Series([12, -2, 0, -9])
시
시.sort_values()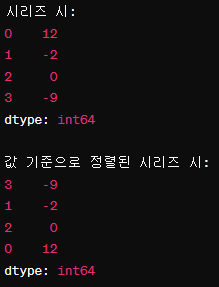
시리즈 값인 [12, -2, 0, -9] 순서로 정렬된 것을 확인할 수 있다.
소실값이 포함되어 있을 경우 정렬
만약소실값이 포함되어 있으면 자료의 맨 나중에 정렬된다.
시1 = pd.Series([10, np.nan, -2, np.nan, -3])
시1.sort_values()
데이터프레임에서 열 이름 정렬
데이터프레임의 경우, 특정한 열에 대한 정렬을 원하면 by=열 이름 인자를 사용하면 된다.
프1 = pd.DataFrame({'a': [-2, 3, -5, 1], 'b': [20, -29, 40, 20]})
프1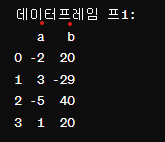
pd.DataFrame()을 사용하여 데이터프레임을 생성한다.
딕셔너리를 사용하여 각 열의 이름과 데이터를 지정한다.
열 'a': [-2, 3, -5, 1]
열 'b': [20, -29, 40, 20]
프1.sort_values(by='a')
두 개 이상의 열 이름으로 정렬을 할 수 있다.
정렬 순서에 차이가 있다.
순위: .rank()
순위(ranking)는 자료의 순서대로 순위를 표시한다.
같은 순위가 있을 경우 method= 인자에 적용되는 방법에 의해 순위를 정한다.
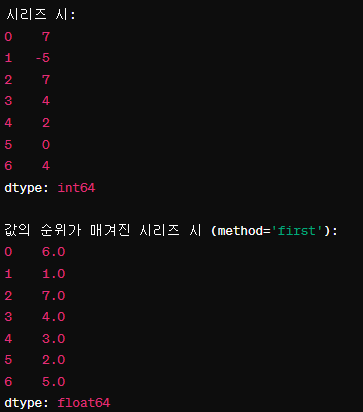
시 = pd.Series([7, -5, 7, 4, 2, 0, 4])
시.rank()
기본값은 평균
method 기본값은 average이다.
같은 숫자들의 순위의 평균을 구하는 것이다.
위에서 4는 순위가 4위와 5위이므로 평균은 4.5가 되는 것이다.
method=first 값을 사용하면 자료의 위치가 앞 에 있는 것이 앞 순위 가 된다.
시.rank(method='first')method='first' 옵션
method='first' 옵션을 사용하여
동일한 값을 가지는 항목에 대해 최초로 나타나는 순서대로 순위를 매긴다.
데이터프레임에서 순위 구하기 (행/열)
데이터프레임도 열 또는 행에 대해서 순위를 구할 수 있다.
먼저 데이터프레임을 만든다.
프 = pd.DataFrame({'b': [4.3, 7, -3, 2], 'a': [0, 1, 0, 1], 'c': [-2, 5, 8, -2.5]})
프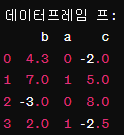
다음은 주어진 데이터프레임 프의 각 행(row) 에 대해 값의 순위를 계산하는 코드이다.
여기서 axis='columns' 를 사용하여 행 단위로 순위를 계산한다.
프.rank(axis='columns')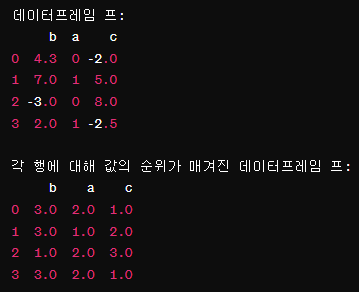
프.rank(axis='columns')는 데이터프레임 프의 각 행 에 대해 값의 순위를 계산한다.
각 행(row) 단위로 순위를 매기며, 값이 작은 것부터 큰 것까지 오름차순 으로 순위를 매긴다.
순위를 매기는 과정
(예) 첫 번째 행 (인덱스 0):
값: [4.3, 0, -2.0]
-2.0 -> 1.0 (가장 작음) 1순위
0 -> 2.0 (중간) 2순위
4.3 -> 3.0 (가장 큼) 3순위
