
📝 분류 분석(Classification Analysis)
범주형 변수 혹은 이산형 변수 등의 범주를 예측하는 모델이다.
1) 의사결정나무(Decision Tree)
데이터들이 가진 특성들을 기준으로 트리 형태로 모델링하는 예측 모델이다. 트리모델 학습 알고리즘은 결정트리의 비용함수를 정의하고, 그것을 최소화 하도록 분할하는 것이다.
분류와 회귀문제 모두 적용 가능하다.
# Decision Tree 모델 학습
# Classification
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
# Regression
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor()
model.fit(X_train, y_train)2) 랜덤포레스트(Random Forest)
의사결정나무의 특징인 분산이 크다는 점을 고려하여 배깅과 부스팅보다 더 많은 무작위성을 주어 약한 학습기들을 생성한 후 이를 선형 결합하여 최종 학습기를 만든다.
# Random Forest 모델 학습
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(X_train, y_train)3) AdaBoost
# AdaBoost 모델 학습
from sklearn.ensemble import AdaBoostClassifier
model = AdaBoostClassifier()
model.fit(X_train, y_train)4) K-Nearest Neighbor
# K Neighbors 모델 학습
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier()
model.fit(X_train, y_train)5) Naive Bayes
# Naive Bayes 모델 학습
from sklearn.naive_bayes import GaussianNB
model = GaussianNB(),
model.fit(X_train, y_train)6) SVM(Support Vector Machine)
# SVM 모델 학습
from sklearn.svm import SVC
model = SVC(gamma=2, C=1),
model.fit(X_train, y_train)📝 용어정리
1. CART 알고리즘
각 독립변수를 이분화하는 과정을 반복하여 이진트리 형태를 형성하여 분류와 예측을 수행하는 알고리즘이다.
2. 지니불순도(Gini Impurity or Gini Index)
여러 범주가 섞여 있는 정도이며, 지니불순도 수치가 0에 가까울 경우 불순도가 낮다는 것을 의미한다.
3. 엔트로피(Entropy)
확률 변수의 불확실성을 수치로 나타낸 것이며, 엔트로피 수치가 0에 가까울 경우 불순도가 낮다는 것을 의미한다.
4. ROC Curve
여러 임계값에 대해 FPR(False Positive Rate)와 TPR(True Positive Rate, recall)를 각각 x, y의 축으로 놓고 그래프를 보여준다.
FPR은 실제 False인 데이터 중에서 모델이 True로 분류한 비율을 나타낸 지표이고, TPR은 실제 True인 데이터 중에서 모델이 True로 분류한 비율을 나타낸 지표이다.
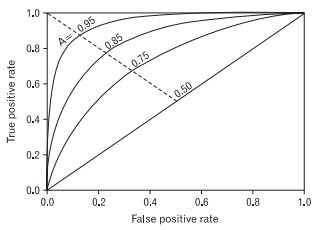
✍🏻 그래프 해석
TPR(Recall)이 크고 FPR(Fall-out)이 작은 형태가 성능이 좋다고 평가하는데, 이는 curve가 왼쪽 위 모서리에 가까운 형태를 보인다.
또한 y=x 그래프보다 상단에 위치해야 어느정도 성능이 있다고 말할 수 있다.5. AUC
ROC curve의 아래 면적을 의미하며, 1에 가까울수록 예측 정확도가 높은 모델이다.
이진분류문제에서 예측 정확도를 확인하기 위해 ROC curve와 AUC 점수를 활용하면 좋다.
6. 교차검증(Cross-validation)
데이터를 k개로 등분하여, k-1개의 부분집합을 train에 사용하고 나머지를 test로 사용하여 검증한다.
7. 특성상호작용
특성들끼리 서로 상관성이 있는 경우를 의미한다.
회귀(regression) 분석은 서로 상호작용이 높은 특성들끼리 있을 경우, 개별 계수를 해석하는데 어려움이 있고, 올바르게 학습이 되지 않을 수도 있다. 트리모델은 이런 상호작용을 자동으로 걸러낸다.
📝 Code Review
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# 데이터셋 불러오기
iris = load_iris()
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target
# train/test 데이터셋 분리
train, test = train_test_split(df, test_size=0.2, random_state=2)
# feature 분리
target = 'target'
features = train.columns.drop([target])
X_train = train[features]
y_train = train[target]
X_test = test[features]
y_test = test[target]
# 모델 학습
tree = DecisionTreeClassifier()
tree.fit(X_train, y_train)
# 교차 검증
scores = cross_val_score(tree, X_train, y_train, cv=5, scoring='neg_mean_absolute_error')
# 모델 평가
score_train = tree.score(X_train, y_train)
score_test = tree.score(X_test, y_test)
print('train 점수: {:.4f}'.format(score_train))
print('test 점수: {:.4f}'.format(score_test))
