
📝 앙상블 분석(Ensemble Analysis)
여러 개의 분류기를 생성하고, 그 예측을 결합함으로써 보다 정확한 예측을 도출한다. 강력한 하나의 모델이 아닌 약한 모델 여러개를 조합하여 최적화된 예측에 도움을 준다.
# 랜덤포레스트(Random Forests)
# Gradint Boosted Trees
1) 배깅(Bagging)
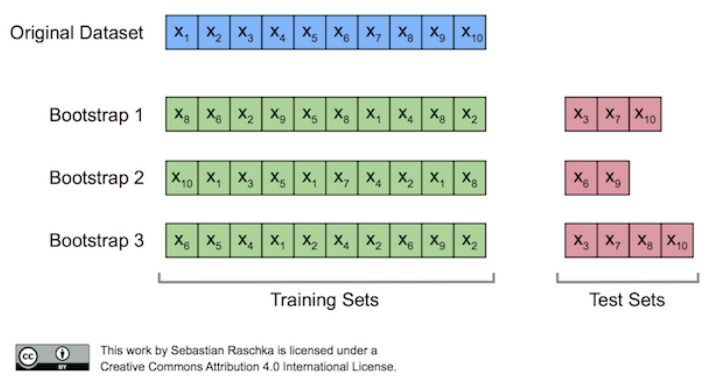
bootstrap aggregating의 줄임말로 원본 데이터를 복원 추출로 샘플링한 부트스트랩 세트를 여러개 뽑은 후, 각 모델을 학습시켜 결과물을 집계하는 방법이다.
회귀문제일 경우 기본모델 결과들의 평균으로 결과를 내고,
분류문제일 경우 다수결로 가장 많은 모델들이 선택한 범주로 예측한다.
대표적인 배깅을 이용한 앙상블 모델로는 'Random Forest'가 있다.
# Random Forest 모델 학습
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(X_train, y_train)2) 부스팅(Boosting)
이전 분류기의 학습 결과를 토대로 다음 분류기의 학습 데이터의 샘플 가중치를 조정하여 약 분류기를 강 분류기로 만드는 학습 방법이다.
대표적인 부스팅 기반 모델은 'AdaBoost', 'CatBoost', 'Gradient Boost', 'XGBoost' 등이 있다.
# XGBoost 모델 학습
from xgboost import XGBClassifier
model = XGBClassifier()
model.fit(X_train, y_train)
