VGG와 ResNet을 다루다가 갑자기 Transformer에 대해 다루게 되었다....
이 Transformer는 요즘 아주아주 뜨거운 감자인 ChatGPT에 핵심 구조라고 볼 수 있다.
당연히 자연어 처리(NLP)쪽 모델이고, Transformer를 이해하기 위해서는 RNN, LSTM, Encoder-Decoder, Attention 정도만 이해하고 있으면 된다.
사실 다 나열해서 그렇지, RNN-LSTM은 거의 하나로 보면 되고, Encoder-Decoder는 아직 나도 공부를 안해서 모르겠다.... 관련 논문을 읽는대로 정리해보도록 하겠다.
근데 무엇보다 Attention이 이 Transformer를 이해하는데 가장 중요하다.
Transformer를 소개한 논문 제목조차 Attention is all you need일 정도로....
그렇기에 이 포스트에서는 RNN과 LSTM이 어떻게 생기고 어떻게 작동하는지, 그리고 Attention에 대해 간단히 이해하고 Transformer의 구조를 살펴보도록 할 것이다.
Encoder-Decoder는 추후에 정리해서 올려야겠다.
1. RNN, LSTM
RNN, LSTM이 뭘까. 일단 RNN은 Recurrent Neural Network, LSTM은 Long Short Term Memory의 약어이다.
"RNN에서 R이 Recurrent인걸 보니, 뭔가 반복되는 구조인가?"라는 생각이 직관적으로 들 것이다.
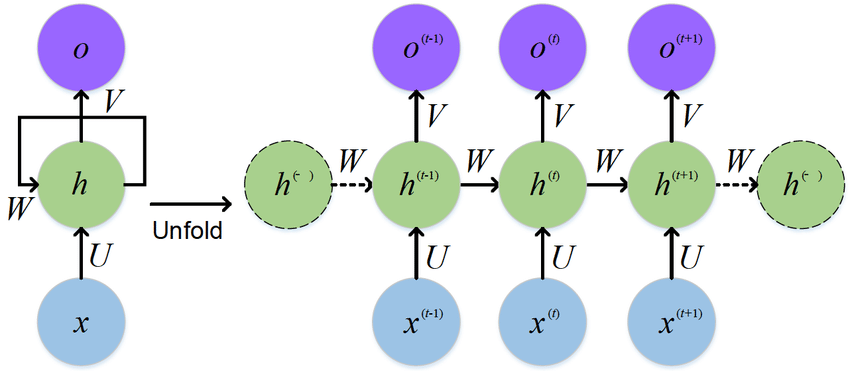
이 그림이 RNN 구조에 대한 그림이다. 쉽게 생각하면 입력에 대한 출력이 결정될 때, 입력에만 영향을 받는것이 아닌 바로 전 단계의 출력과 입력에 동시에 영향을 받는다고 생각하면 된다.
이런 RNN구조는 인풋이 순서대로 주어지고, 아웃풋도 순서대로 나온다는 점 때문에 squential한 데이터를 처리하는데 적합하다.
Sequential 데이터란 순서가 있는 데이터를 의미하며, 시간의 흐름에 따라 변하는 주식 정보라던지, 날씨, 등 여러가지가 있지만 그 중 언어 데이터에 사용할 수 있다는 것이 컸다.
그런데 이 RNN은 데이터의 길이가 길어지면 앞쪽에 나온 데이터가 다음 출력을 결정하는데 끼치는 영향력이 거의 사라지다시피 하는 Gradient Vanishing문제가 또 발생한다.
그래서 그걸 해결하기 위해 나온 것이 LSTM이다. 이 구조가 사실 Residual Link의 시초라고 봐도 무방하다.
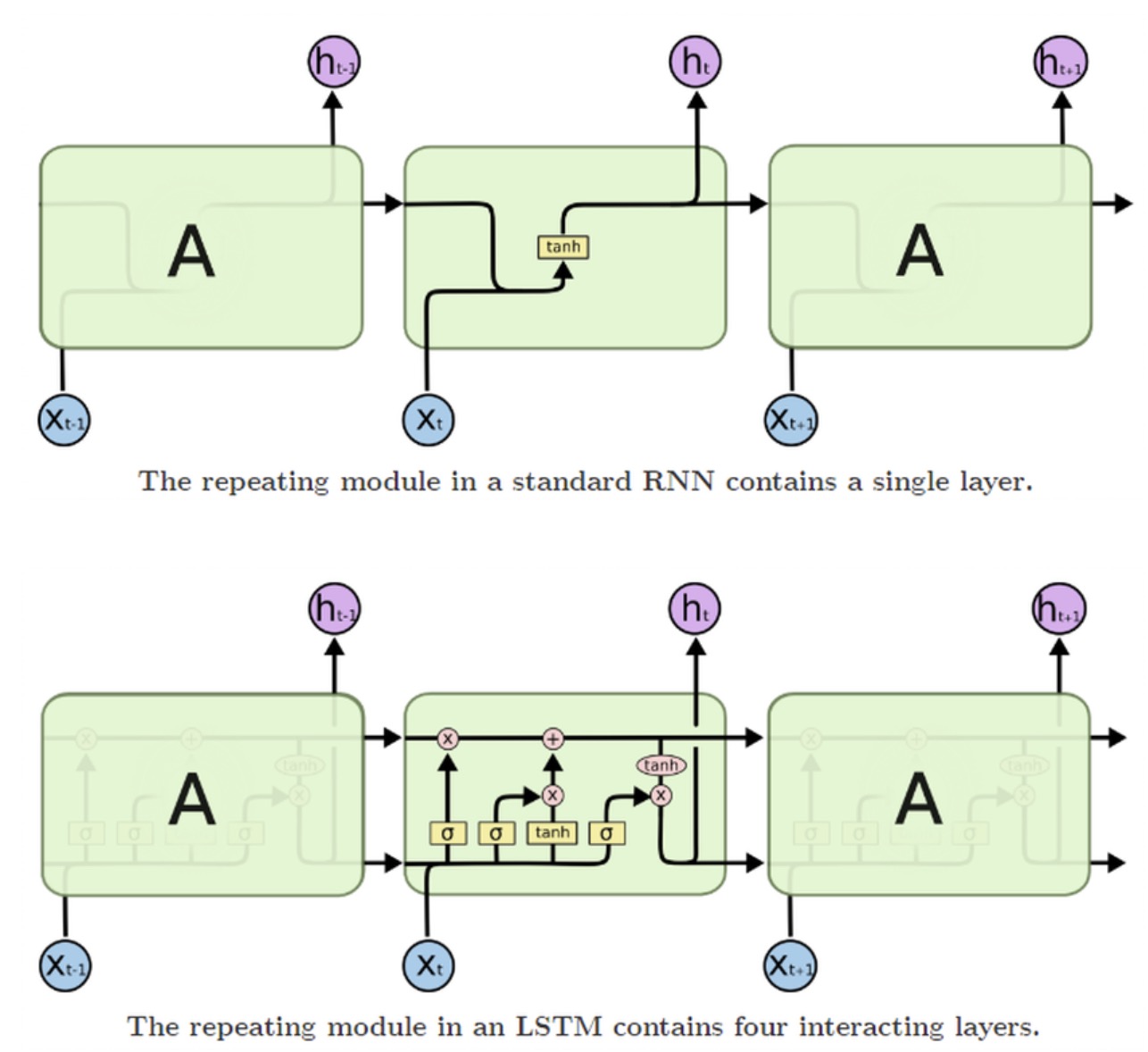
이 그림이 RNN과 LSTM을 나타낸 사진이다. 아래가 LSTM.
안에 구조가 상당히 복잡하게 되어있는데, 아무튼 RNN과는 다르게 과거의 h값을 동시에 전달한다는 것만 기억하면 된다.
2. Attention
LSTM으로 한계점이 해결되었다면 얼마나 좋았을까....
당연히 LSTM도 입력 데이터의 길이가 길어지면 앞쪽의 정보가 소실되는 문제점은 여전히 완벽하게 해결하지 못했고, 이는 자연어처리에 있어 큰 걸림돌이 되었다.
왜냐면 자연어 처리의 경우 Training Data로 엄청난 길이의 word vector가 주어지기 때문에, 정보 소실의 문제가 큰 해결 과제가 되었다.
이 문제를 해결하기 위해 나온 것이 attention이다.
https://arxiv.org/abs/1409.0473
이게 attention에 대해 처음 다룬 논문이고, 읽어보면 context 정보를 전달하기 위해 기존에 사용하던 encoder-decoder구조는 그대로 가져갔지만, encoder의 출력으로 fixed-length vector가 출력되는 부분을 지적했다.
기존에는 input문장들의 필수적인 정보를 요약한 source-sentence를 fixed-length vector로 변환했다. 이 부분은 enc-dec부분 논문을 읽어보거나 서칭을 해봐야 정확히 이해가 될 것 같다.
그것을 attention에서는 input sentence를 sequence of vectors로 바꿔서 출력하도록 바꾸고, decoding을 진행하면서 subset of sequence vectors를 선택하여 decode한다고 한다.
즉, encode를 진행하면서 다음에는 어떤 단어에 집중해서 decode를 해야하는지 알려주는 것이 attention의 핵심 개념이다.
결론적으로 Attention에서 학습하는 것은 주변의 input들이 에 매칭 될 확률들에 대한 행렬이다.
3. Transformer
트랜스포머 구조에 대해 적기 전에 건너뛴 부분이 상당히 많다.
기본적으로 텍스트가 어떻게 벡터로 표현되는지부터 단어의 embedding, 그리고 attention의 연산과정들까지 다루지 않았다.
하지만 이건 어차피 내가 기억하려고 적는 포스트니까 상관없지만....!
3.1 Preprocessing
그래도 간단히 적고 넘어가자.
텍스트는 다음과 같이 one-hot encoding을 진행해서 사용한다.

각 단어가 문장의 어디에 위치하는지 정보를 포함한다.
이걸 document단위로 확대하면, 어떤 문장은 단어들의 one-hot vector들의 vector로 표현이 가능해진다. (이 때는 단어들의 위치를 bag_of_words에서 가져온다.)
말이 너무 어렵다. 실습 때 진행했던 파일로 예시를 들어보자

이런 형태의 document가 존재한다고 하자.
그럼 이 문장들을 모두 단어 단위로 쪼개고, 중복되는건 없애고, 적절한 전처리를 해줘서 이 document를 구성하는 단어가 어떤 것이 있는지를 알아내서, 각각에 고유 index를 부여한다고 생각하면 된다.

윗줄의 출력은 각 문장마다 단어 단위로 쪼갠 것이고, 아래줄 출력은 그 단어들을 중복되는건 빼고 모두 모은 것이다.
그 후, 각 단어들에 index를 부여하면

이 그림의 윗줄 출력같은 모양이 완성된다.
그럼 처음에 document의 첫 문장 'I love to read books and watch movies'을 vector로 표현하면 [28, 34, 49, ..., 35] 이런 vector가 된다.
그 후 one-hot encoding을 진행해서 입력으로 사용하는데, 단어의 수가 많을수록 입력 vector가 sparse해질 것임을 예측할 수 있다. 당장 예시로 든 위 사례만 보더라도, 총 54개의 단어들로 이루어졌고, 'I'를 표현하려면 54차원의 0벡터 중 28번째 값만 1인 벡터를 입력으로 주는 것이다.
그래서 이걸 그대로 사용하면 학습이 안될것이 뻔하니까 dense하게 바꿔주는 작업을 한다.
그게 바로 embedding이다.
한 10만 단어로 이루어진 문서에 대해 학습을 진행한다고 생각하면, 10만차원의 sparse vector가 input으로 주어지는데, embedding layer를 통과하면 이게 256차원(수치는 예시) 정도로 줄어든다.
근데 신기한건, 이렇게 embedding을 진행하고 나면 유사한 단어들끼리는 벡터의 유사도가 높게 설정이 된다. 그 이유는....
 이렇습니다
이렇습니다
3.2 Attention
Attention에 대한 이야기는 2번에서 조금 다루긴 했지만, 어떻게 작동하는지는 그림도 없고 글만 써놨기에 직관적이지 못할 것이다. 그래서 가져왔다 그림!
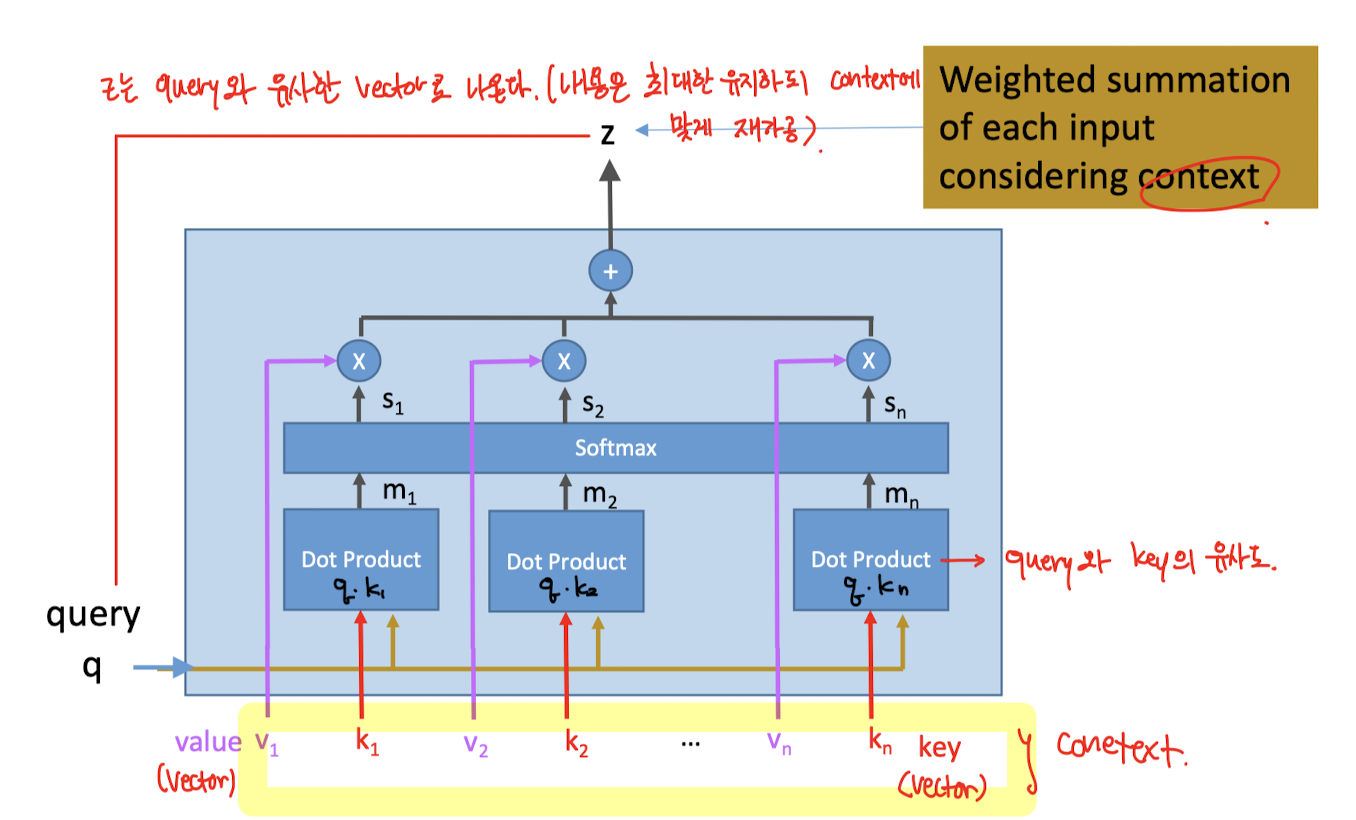
attention은... 입력q(query)를 context(v, k)에 맞게 재가공하여 출력 z를 반환한다! 가 위 그림의 요약이다.
그림을 자세히 보면 v값은 residual link로, q와k는 dot product후 소프트맥스를 해서 서로 더해지는 것을 확인 할 수 있다.
결과적으로 나오는 z에 대한 의미적 해석은 "원본 q와 비슷하긴 한데, context냄새가 나는 q"라고 할 수 있다.
K와 V 매트릭스를 어떻게 형성하는지는 아마 Attention is all you need 논문에 나왔있을 것이라 생각한다.(아직 논문도 안봄) 아니면 구글링을 통해 정리를 한 번 해야지
그렇다면, 문장 내 한 단어가 어떤 문맥을 갖는지를 알고싶다면 어떻게 할까?
해당 단어가 있는 문장을 context정보로 주면 된다.
이걸 Self-Attention이라 하고, 그림으로 그리면 다음과 같다.
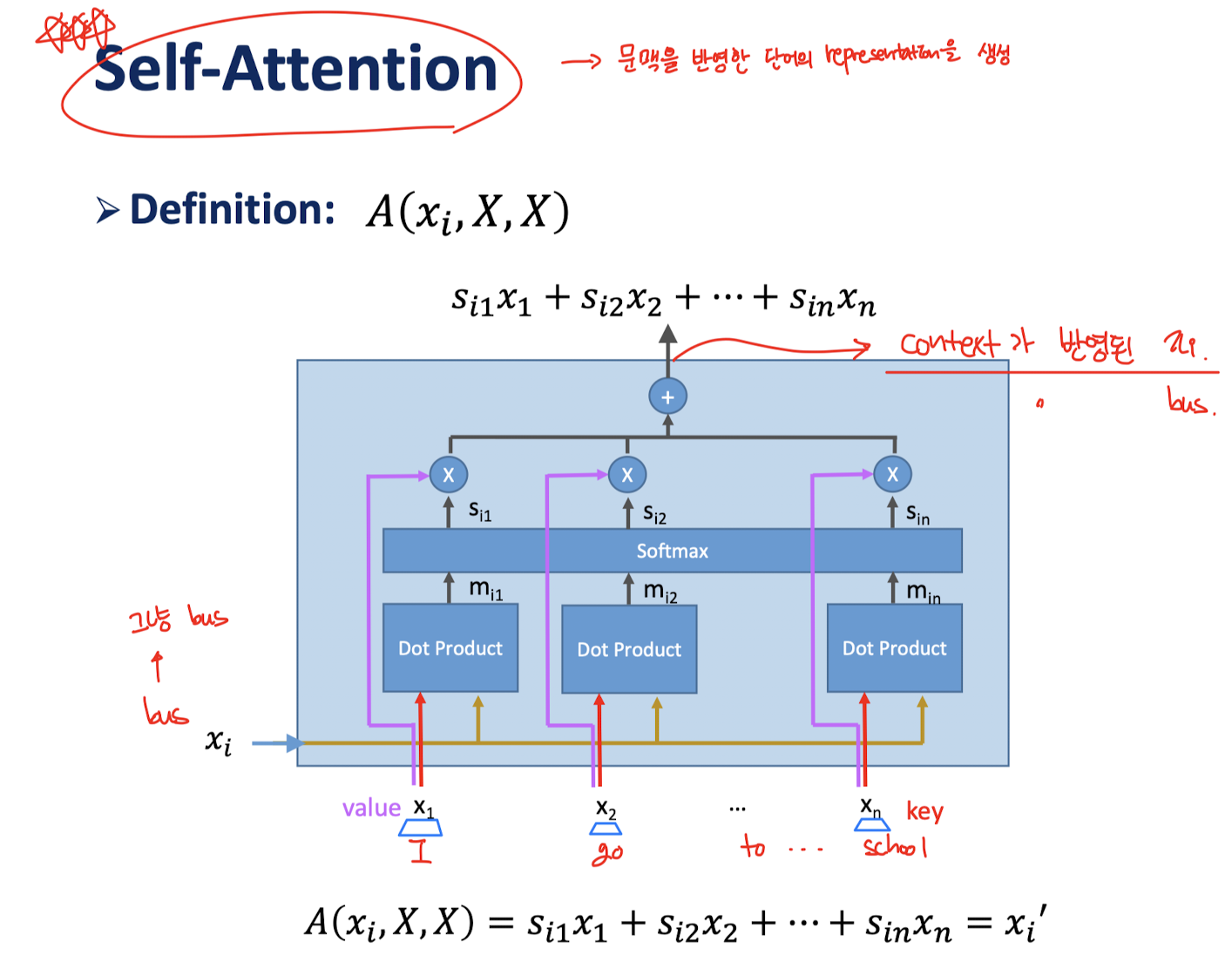
3.3 Encoder-Decoder
Transformer는 Encoder와 Decoder로 구성되어있다.
그렇다면 Encoder, Decoder는 어떤 식으로 작동하는지 간략하게 알아야 transformer가 어떻게 작동하는지 이해하기 편할 것이다.
구글링 하다가 아주 찰떡으로 이해하기 쉬운 움짤을 발견했다.
디코더가 어떻게 작동하는지에 대해 1번 스텝부터 마지막 스텝까지 보여준다.
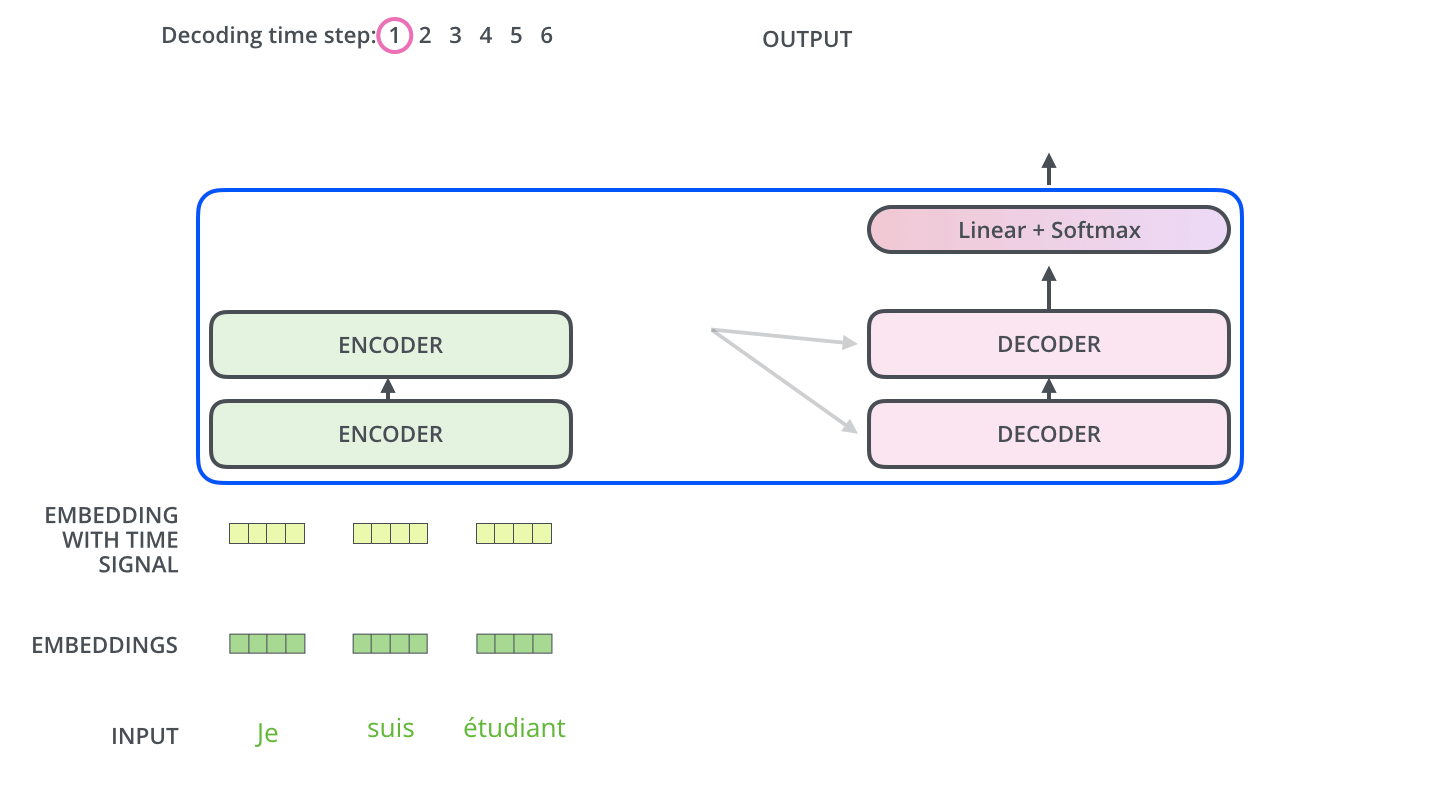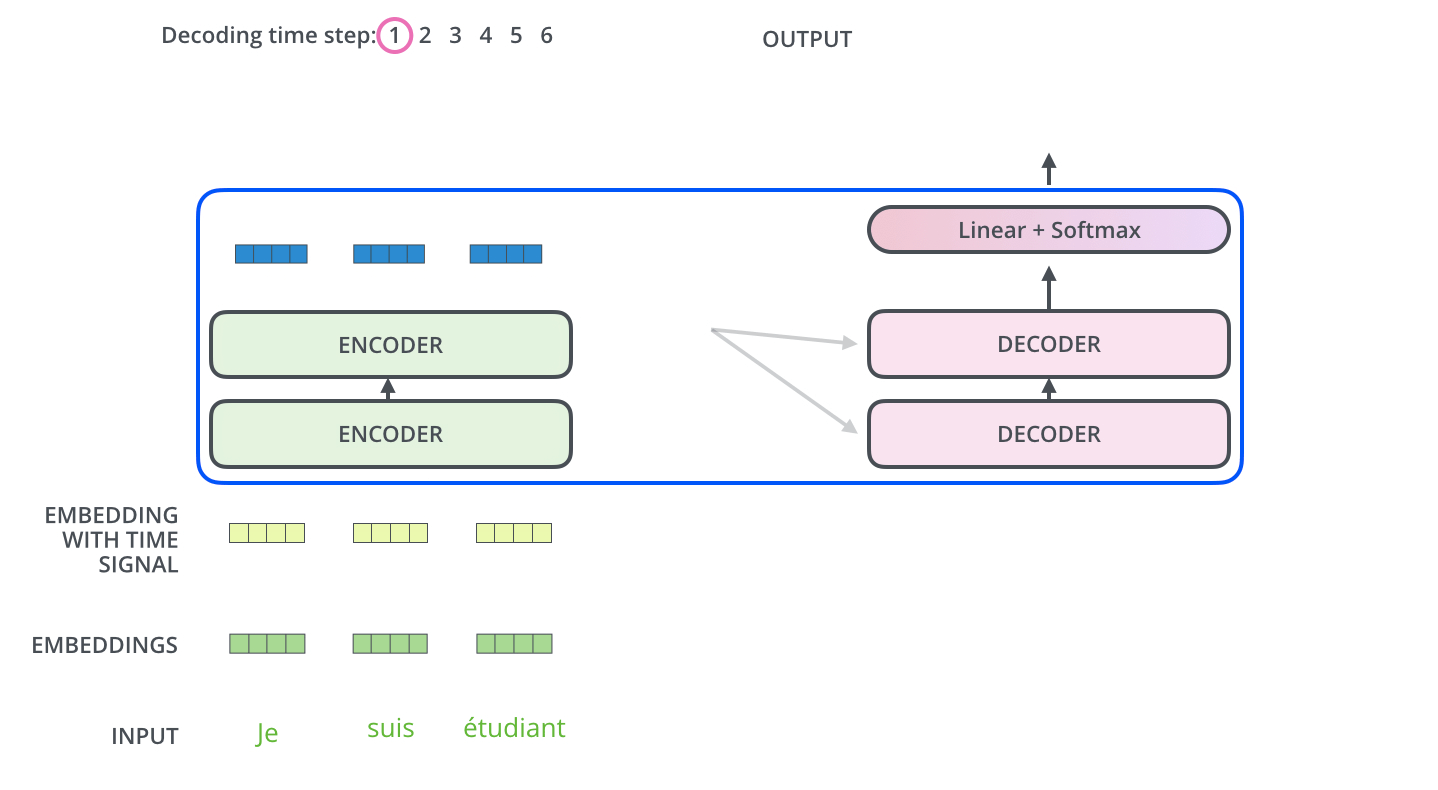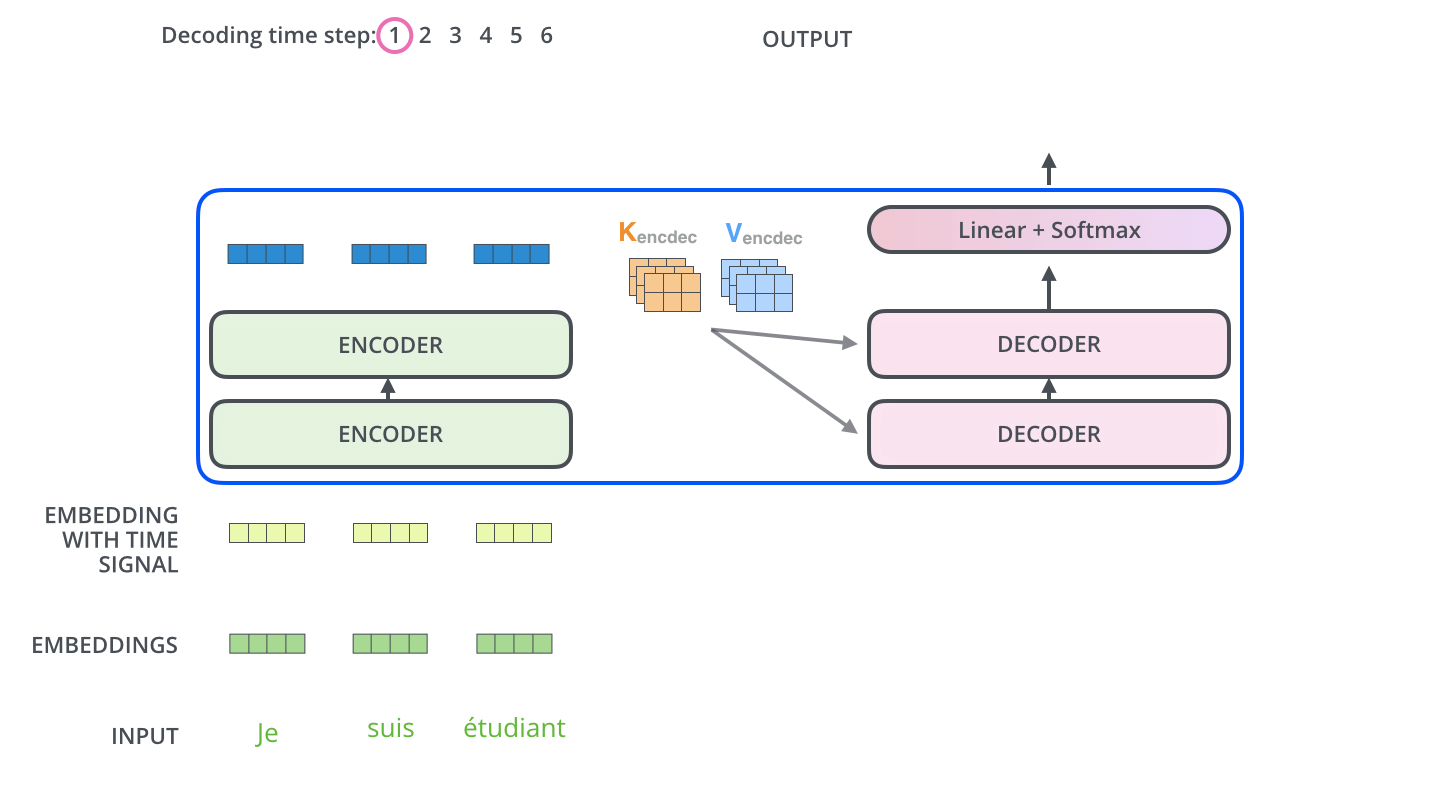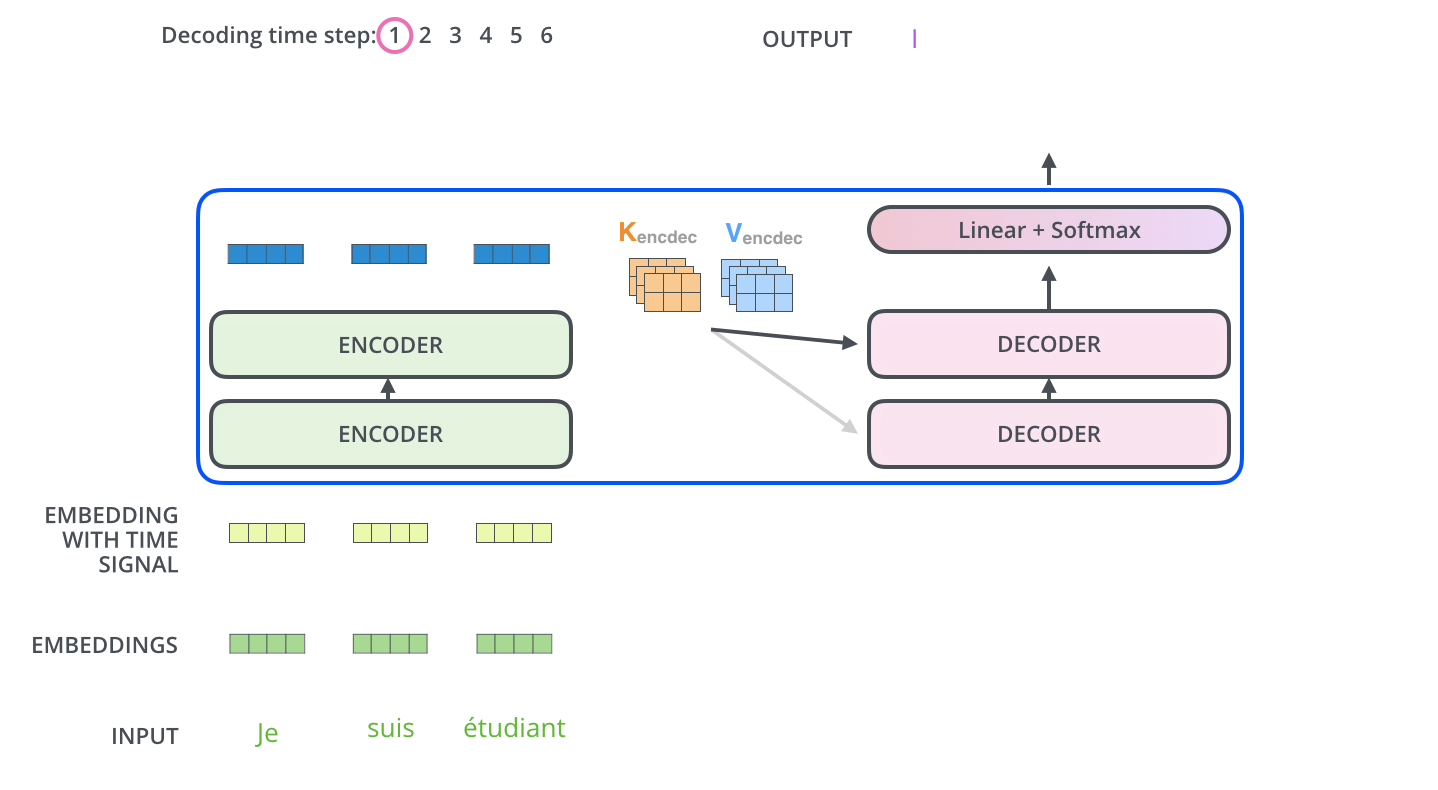 이게 첫 스텝
이게 첫 스텝
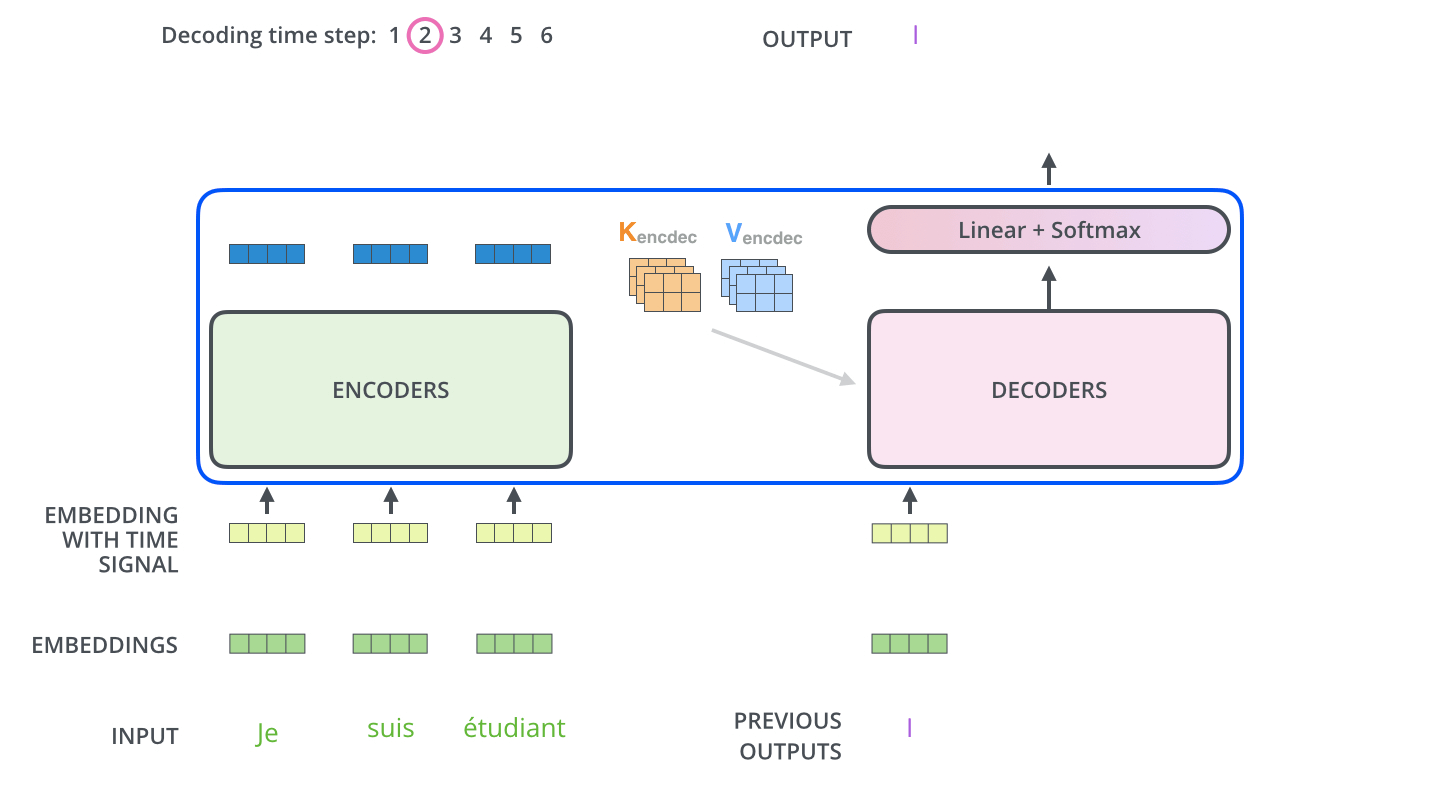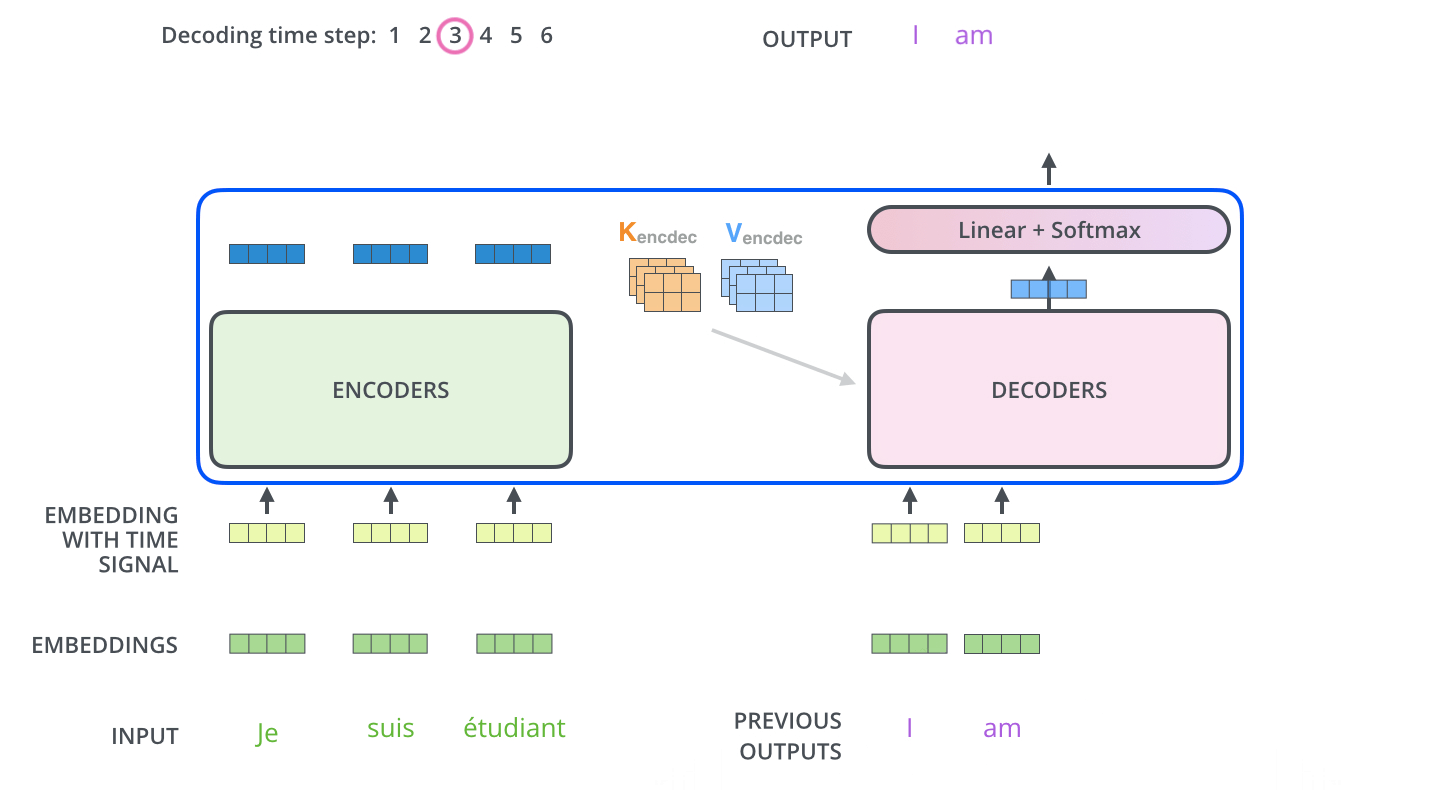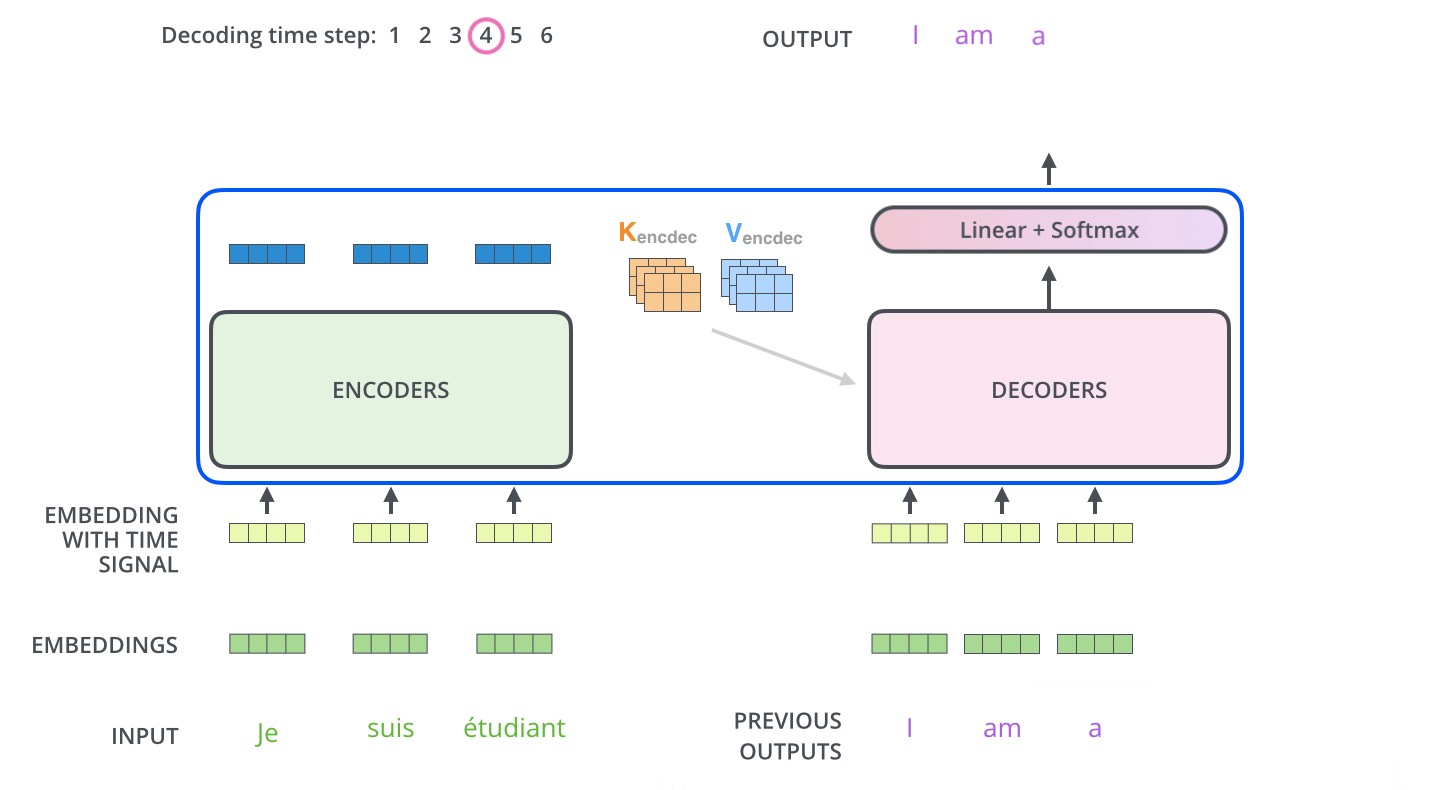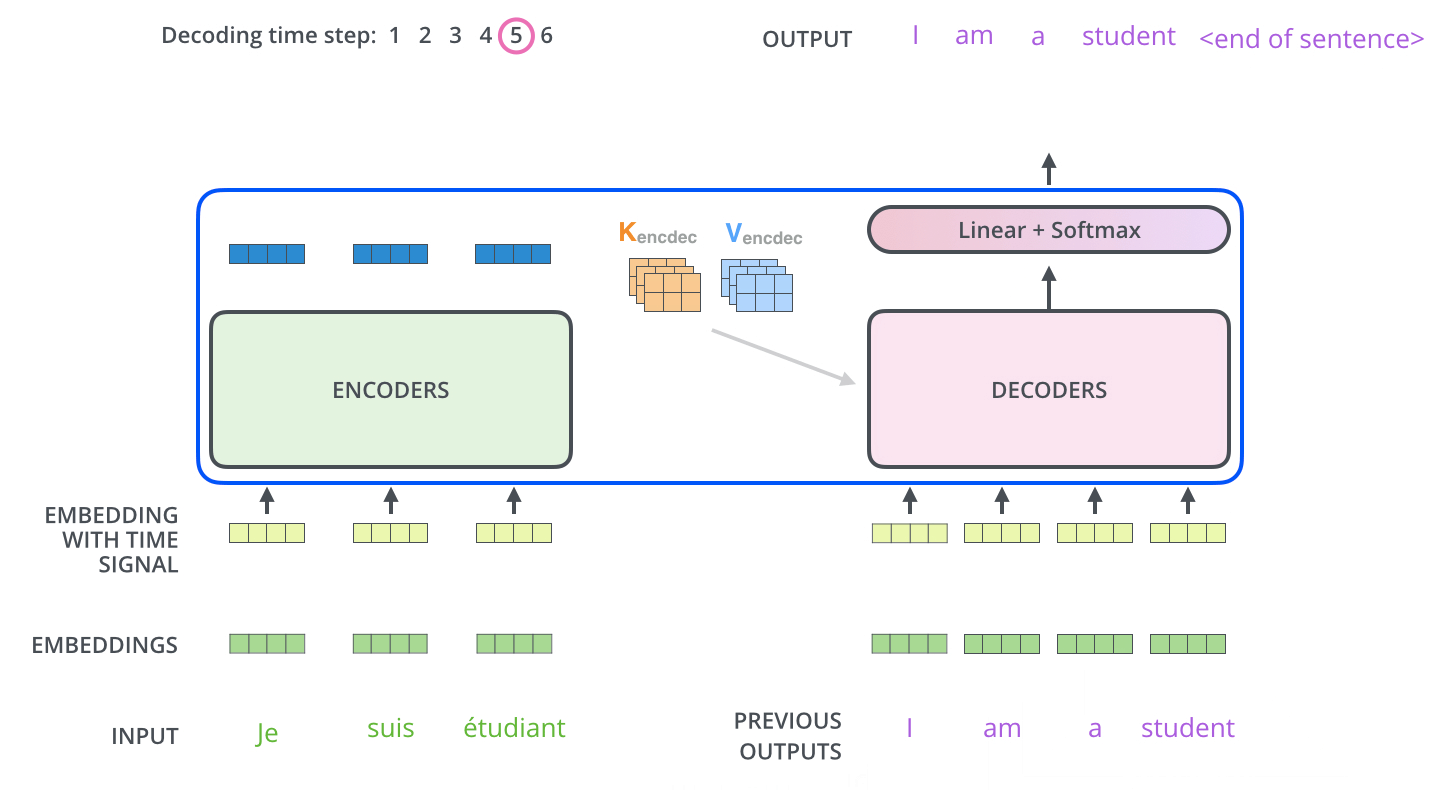 이게 그 다음부터 마지막 스텝까지의 과정이다.
이게 그 다음부터 마지막 스텝까지의 과정이다.
중요한건 output을 다시 decoder의 input으로 사용한다는 것!
3.4 Transformer
이제 진짜 transformer에 대해 알아보자.
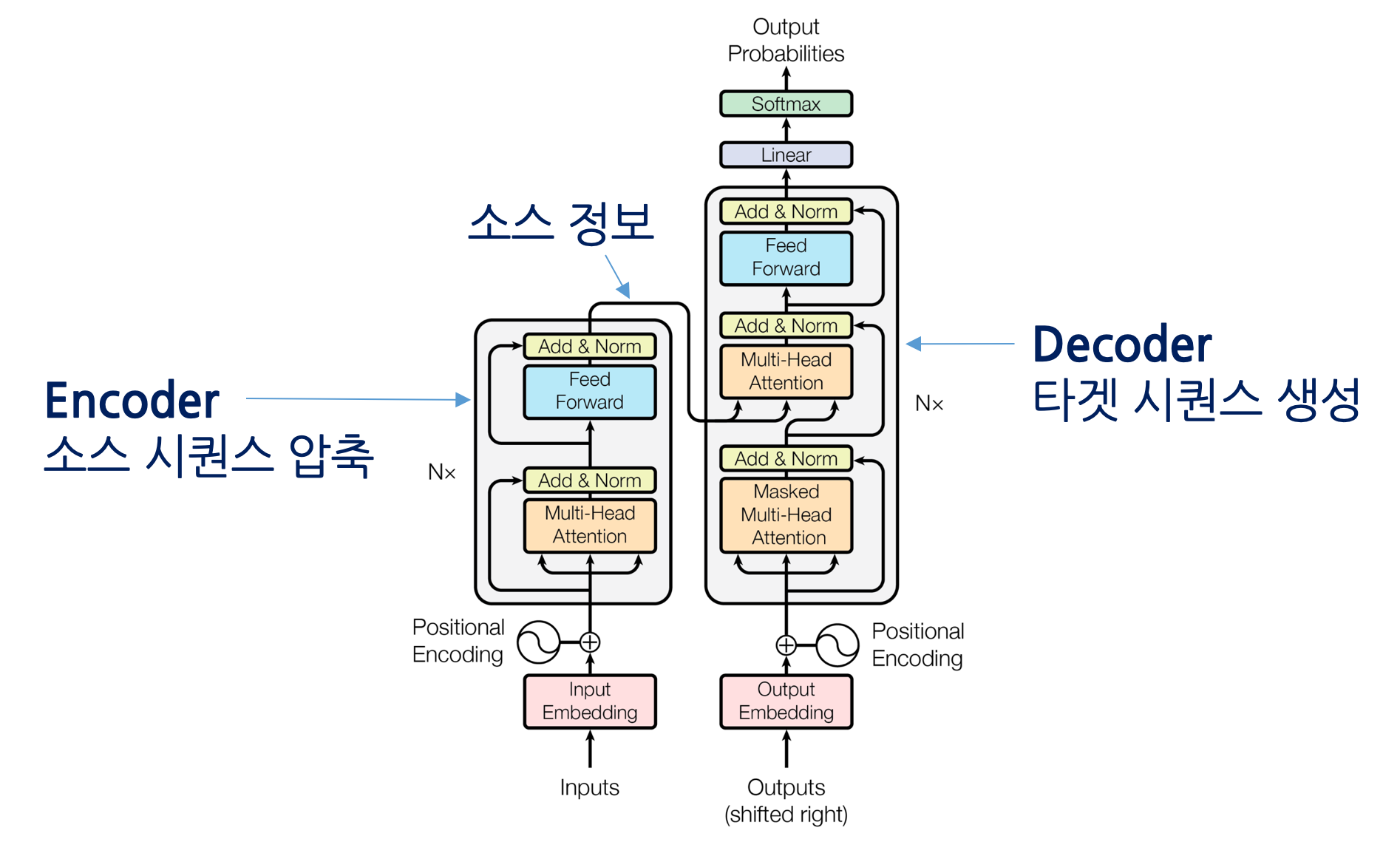 이게 Transformer의 구조이다.
이게 Transformer의 구조이다.
내부에 이거저거 엄청 많긴 한데, 앞에서 다 다룬 것들이다.
다만, Positional Encoding, Multi-Head/Masked Multi-Head Attention은 추가적으로 설명이 필요하다.
3.4.1 Encoder
Transformer의 encoder는 어떻게 생겼는지 한번 보자.
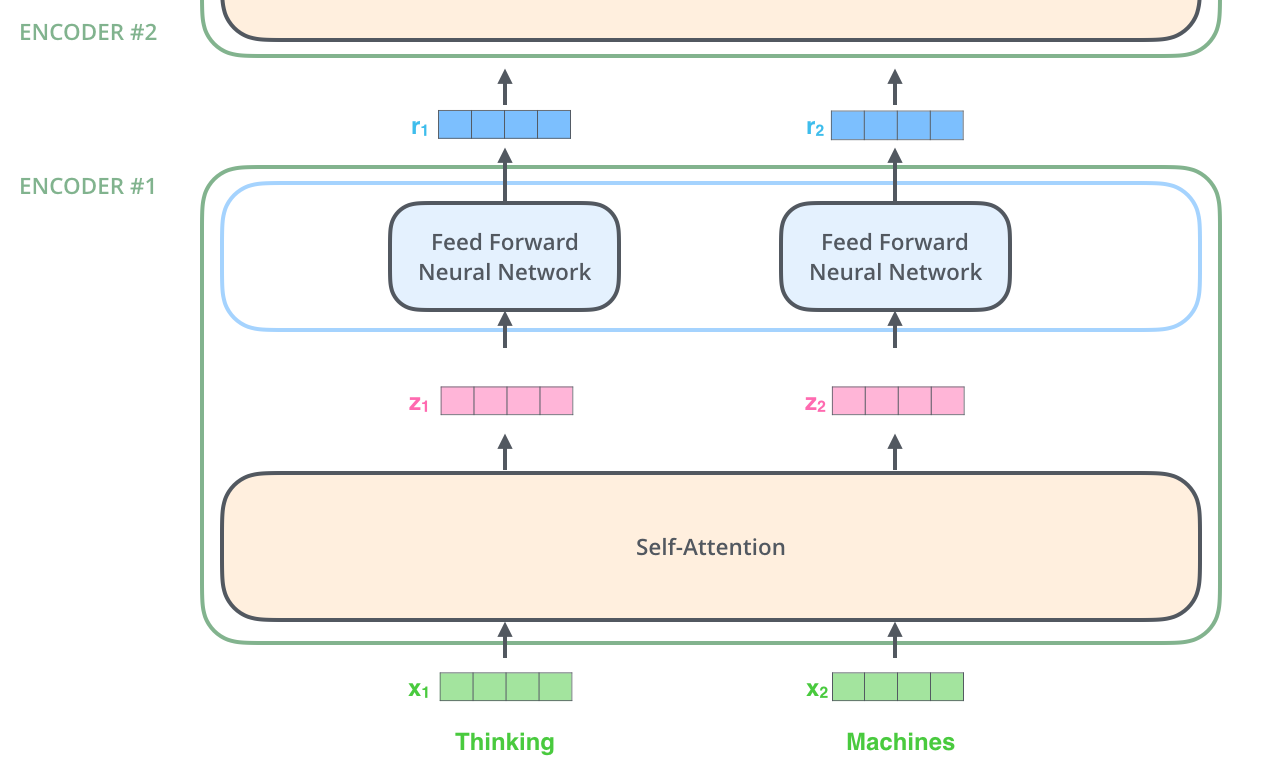
이렇게 생겼다고 한다. Transformer의 코드와 그림을 다룬 노트북 링크가 있었다.(https://colab.research.google.com/github/dlmacedo/starter-academic/blob/master/content/courses/deeplearning/notebooks/pytorch/Transformer_Illustration_and_code.ipynb#scrollTo=QGwbOVbp_hRc)
아무튼, 입력으로 임베딩된 벡터가 들어오면, self-attention을 진행하여 context가 반영된 z를 반환하고, 그걸 NN을 통과시켜서 비선형 처리를 진행하여 다시 다음 층의 인코더에 인풋으로 넣는다.
이걸 N번 반복해서 나온 결과물을 디코더에 사용하는 것이다.
근데 처음에 transformer구조에 대해 살펴볼때, encoder단에는 multi-head attention이란게 있었다. Attention은 대충 이해했는데, multi-head는 뭘까?
3.4.2 Multi-head Attention
우리가 attention은 주어진 context에 맞게 단어를 재가공하는 것이라고 한다 했었다.
Multi-head attention은, 재가공 할 때, 어떤 context에 집중할 것인지 가중치를 곱해줘서 재가공을 하는 것이다.
결론부터 말하자면, 문맥을 더 잘 고려한 출력물이 나오도록 해주는 것이 multi-head attention의 효과이다.

그림 중 아래가 headed attention의 수식인데, 보면 Attention의 인자로 모두 , , 가 각각 곱해진 것으로 전달된다. 각 W행렬을 곱한다는건 Linear Transform을 해준다는 뜻이고, 각 Q,K,V행렬의 일부분을 집중해서 Attention을 진행한다는 뜻으로 해석하면 된다.
Multi-headed는 이 W행렬들을 여러개 곱하면서 최적의 W행렬들을 찾도록 하는것이다. 그냥 headed를 동시에 여러번 한다고 생각하면 된다.
3.4.3 Positional Encoding
Positional encoding은 인코더에 인풋으로 단어들을 전달하기 전에, 단어마다 문장의 어디에 위치하는지를 나타내는 위치 정보를 씌워서 전달해주는 과정이다.
벡터의 연산에서 dot product가 두 벡터 사이의 유사도를 의미하듯이, 벡터 연산에서 덧셈은 두 벡터의 의미를 동시에 갖게 하는 효과가 있다.
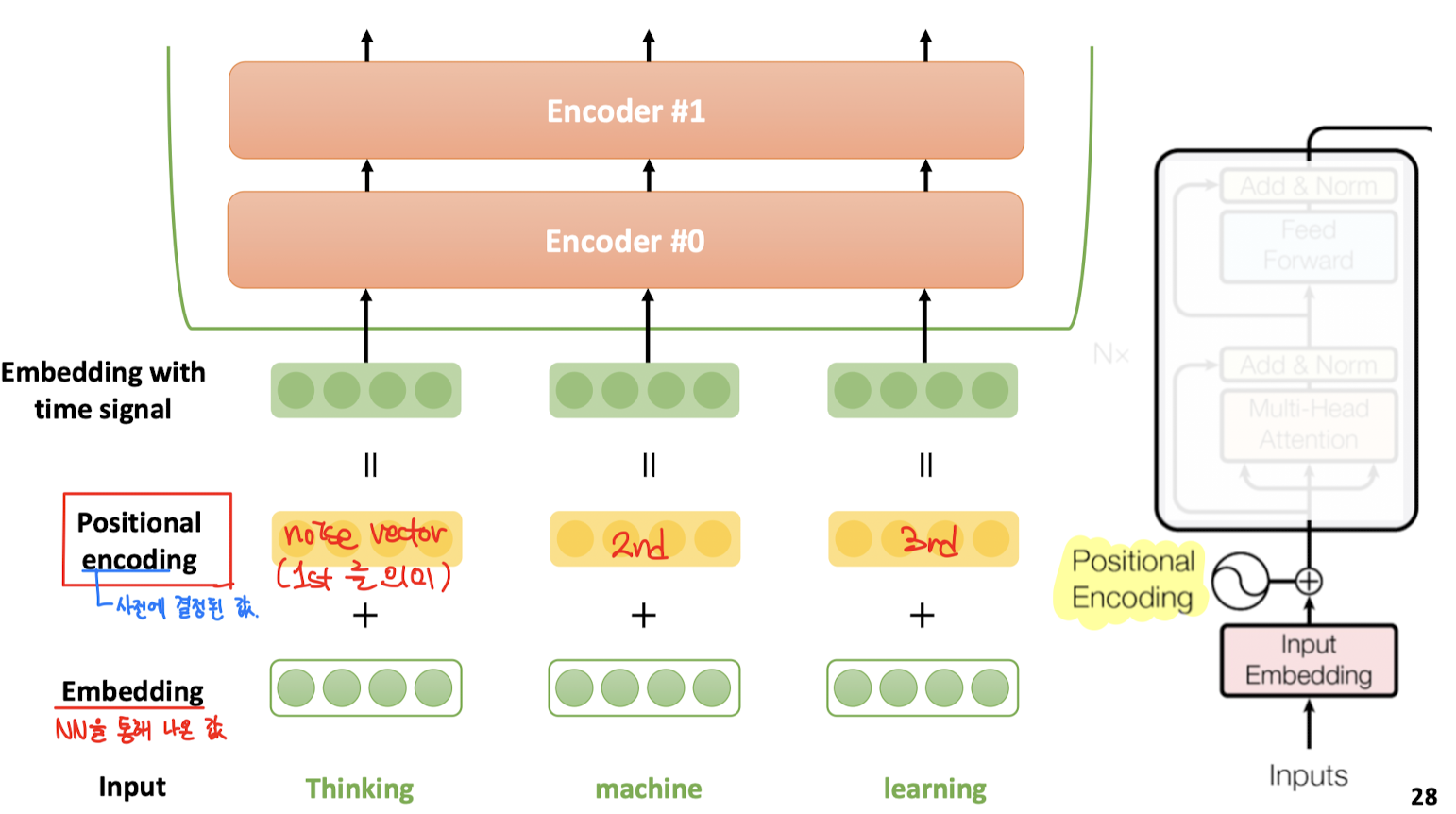
그래서 위 그림과 같은 과정을 거치면, representation vector에 position정보가 동시에 부여된 representation vector가 인풋으로 주어지는 것이다.
이렇게 encoder를 여러 번 쌓은 후 출력된 결과를 여러 번 쌓인 decoder에 모두 residual link로 전달해주는 것이 transformer구조의 작동 원리이다.
물론 수식을 보면 더욱 복잡하겠지만, 이런 흐름으로 진행된다를 배운 과정이었기에, 추가적인 부분은 다른 포스트로 작성하도록 하겠다.
이론 정리 끝!