Extraction-based MRC 문제 정의
질문(question)의 답변(answer)이 항상 주어진 지문(context)내에 span으로 존재 e.g. SQuAD, KorQuAD, NewsQA, Natural Questions, etc.
허깅페이스 데이터 다운로드
Extraction-based MRC datasets in Hugging Face datasets
Extraction-based MRC 평가 방법
SQuAD, KorQuAD 리더보드
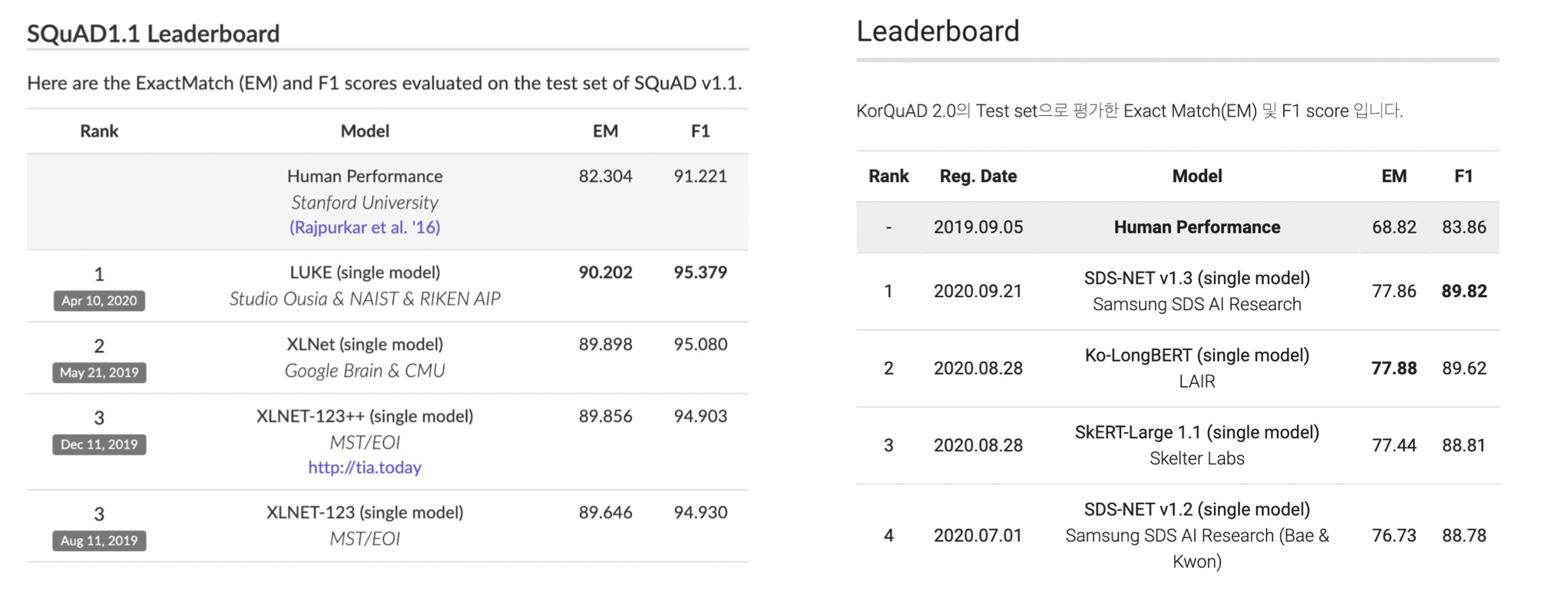
EM(Exact Match Score)
예측값과 정답이 캐릭터 단위로 완전히 똑같을 경우에만 1점 부여. 하나라도 다른 경우 0점.
F1(F1 Score)
예측값과 정답의 overlap을 비율로 계산. 0점과 1점사이의 부분점수를 받을 수 있음.

Ground Truth값은 항상 하나인 경우가 아니기 때문에 여러개인 경우 각각 계산을 진행하고 가장 높은 값을 출력한다.
Extraction-based MRC Overview
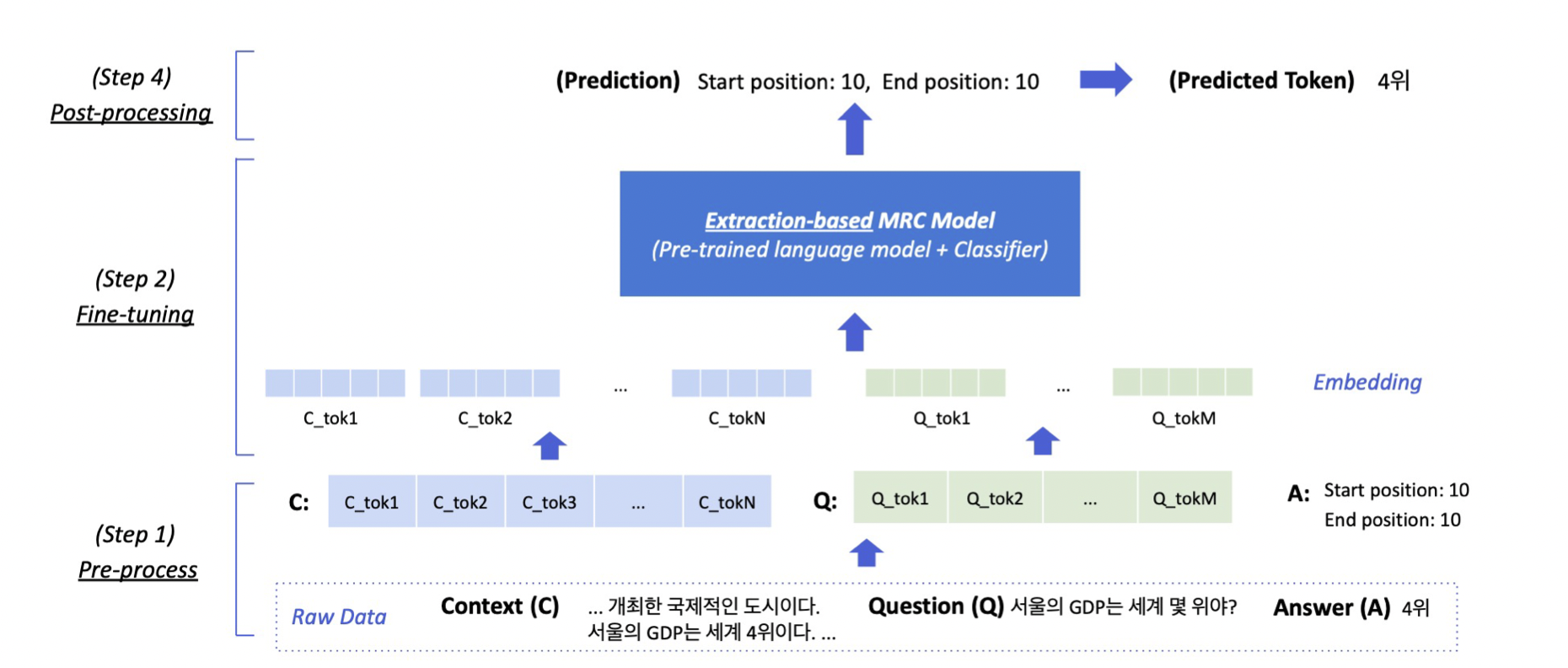
Post Proprecessing에서 prediction으로 start position과 end position을 만들어낸다. (position 중 Start, end로 가장 확률이 높은 단어)
Pre-processing
Tokenization
텍스트를 작은 단위 (Token) 로 나누는 것
• 띄어쓰기 기준, 형태소, subword 등 여러 단위 토큰 기준이 사용됨
• 최근엔 Out-Of-Vocabulary (OOV) 문제를 해결해주고 정보학적으로 이점을 가진 Byte Pair Encoding (BPE) 을 주로 사용함
• 본강에선 BPE 방법론중 하나인 WordPiece Tokenizer를 사용
WordPiece Tokenizer 사용 예시
"미국 군대 내 두번째로 높은 직위는 무엇인가?"
[미국, 군대, 내, 두번째, ##로, 높은, 직, ##위는, 무엇인가, ?]
Attention Mask
• 입력 시퀸스 중에서 attention 을 연산할 때 무시할 토큰을 표시
• 0은 무시,1은 연산에 포함
• 보통 [PAD]와 같은 의미가 없는 특수토큰을 무시하기 위해 사용
Token Type IDs
입력이 2개이상의 시퀸스일 때 (예: 질문 & 지문), 각각에게 ID를 부여하여 모델이 구분해서 해석하도록 유도
SEP 토큰을 이용해 나눠주는 것뿐만 아니라 Toekn Type ID까지 준다.
모델 출력값
• 정답은 문서내 존재하는 연속된 단어토큰 (span)이므로, span의 시작과 끝 위치를 알면 정답을 맞출 수 있음.
• Extraction-based에선 답안을 생성하기 보다, 시작위치와 끝위치를 예측하도록 학습함. 즉 Token Classification문제로 치환.
Fine-Tuning BERT
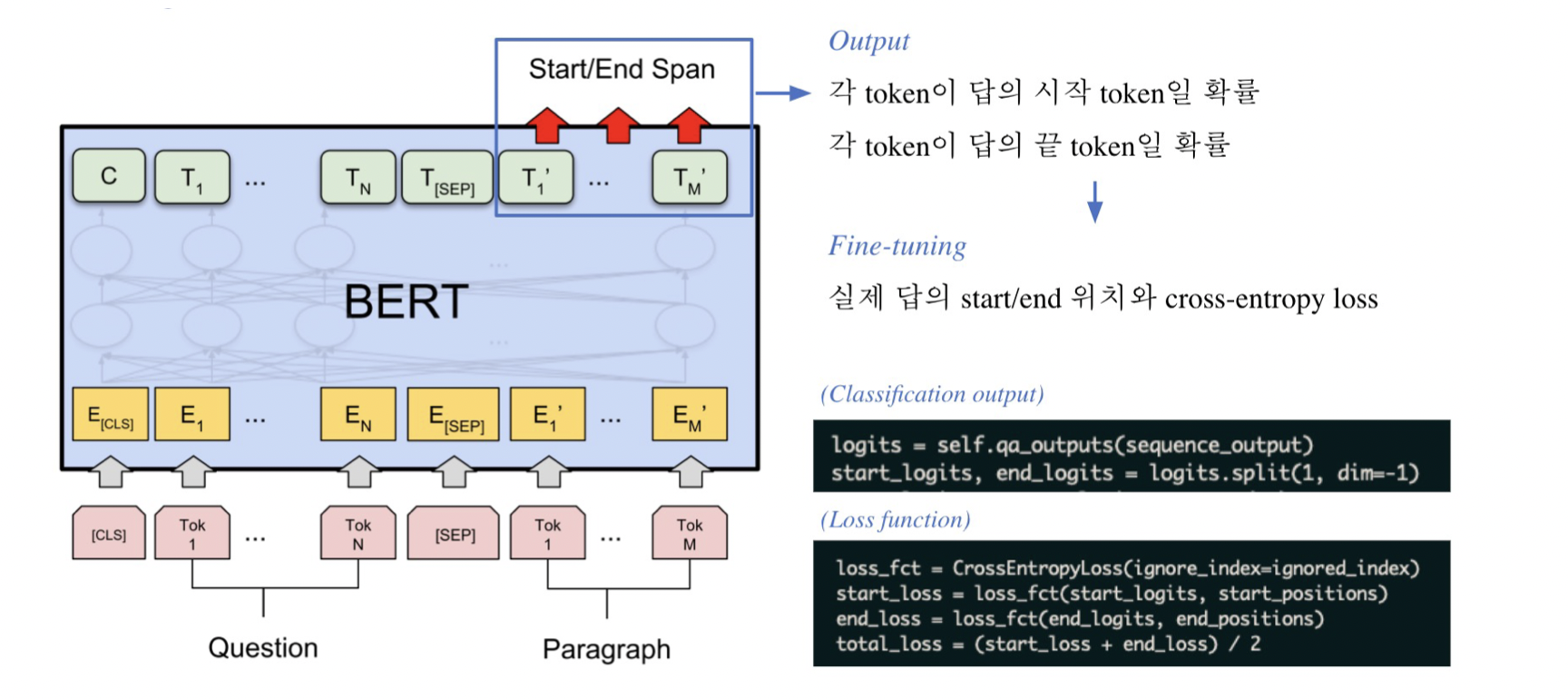
위의 그림과 같이, 실제 답의 Start/end 위치와 Cross-entropy Loss를 사용하고 각 Loss 값의 평균을 계산하는 형식이다.
Post-processing
불가능한 답 제거하기
다음과 같은 경우 candidate list에서 제거
• End position 이 start position보다 앞에 있는 경우 (e.g. start = 90, end =80)
• 예측한 위치가 context를 벗어난 경우 (e.g. question 위치쪽에 답이 나온 경우)
• 미리 설정한 max_answer_length 보다 길이가 더 긴 경우
최적의 답안 찾기
- Start/end position prediction에서 score (logits)가 가장 높은 N개를 각각 찾는다. 총 개이다.
- 불가능한 start/end 조합을 제거한다.
- 가능한 조합들을 score의 합이 큰 순서대로 정렬한다.
- Score가 가장 큰 조합을 최종 예측으로 선정한다.
- Top-k 가 필요한 경우 차례대로 내보낸다.
Codes
max_seq_length = 384 # 질문과 컨텍스트, special token을 합한 문자열의 최대 길이
pad_to_max_length = True
doc_stride = 128 # 컨텍스트가 너무 길어서 나눴을 때 오버랩되는 시퀀스 길이
# -->두 답변 중 확률이 높은 걸 택한다!
max_train_samples = 16
max_val_samples = 16
preprocessing_num_workers = 4
batch_size = 4
num_train_epochs = 2
n_best_size = 20
max_answer_length = 30preprocessing pipeline
column_names = datasets["train"].column_names
train_dataset = train_dataset.map(
prepare_train_features,
batched=True,# 여러개로
num_proc=preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=True,
)Fine-Tuning
from transformers import default_data_collator #학습시 데이터 여러개 합치기
from transformers import TrainingArguments
from transformers import EvalPrediction
from trainer_qa import QuestionAnsweringTrainer
from utils_qa import postprocess_qa_predictions