Generation-based MRC
Generation-based MRC 문제 정의
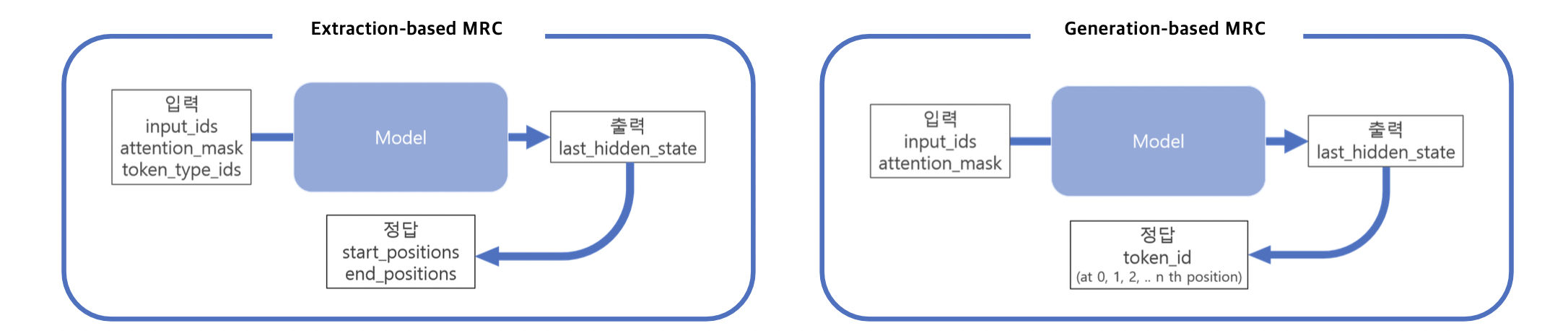
1) Extraction-based mrc: 지문 (context) 내 답의 위치를 예측 ⇒ 분류 문제 (classification)
2) Generation-based mrc: 주어진 지문과 질의 (question) 를 보고, 답변을 생성 ⇒ 생성 문제 (generation)
모든 Extraction-based mrc는 Generation-based mrc로 치환이 가능하다.
Generation-based MRC 평가 방법
동일한 extractive answer datasets ⇒ Extraction-based MRC와 동일한 평가 방법을 사용 (recap)
1) Exact Match(EM) Score
EM = 1 when (Characters of the prediction) == (Characters of ground-truth) Otherwise, EM = 0
2) F1 Score
예측한 답과 ground-truth 사이의 token overlap을 F1으로 계산
Generation-based MRC
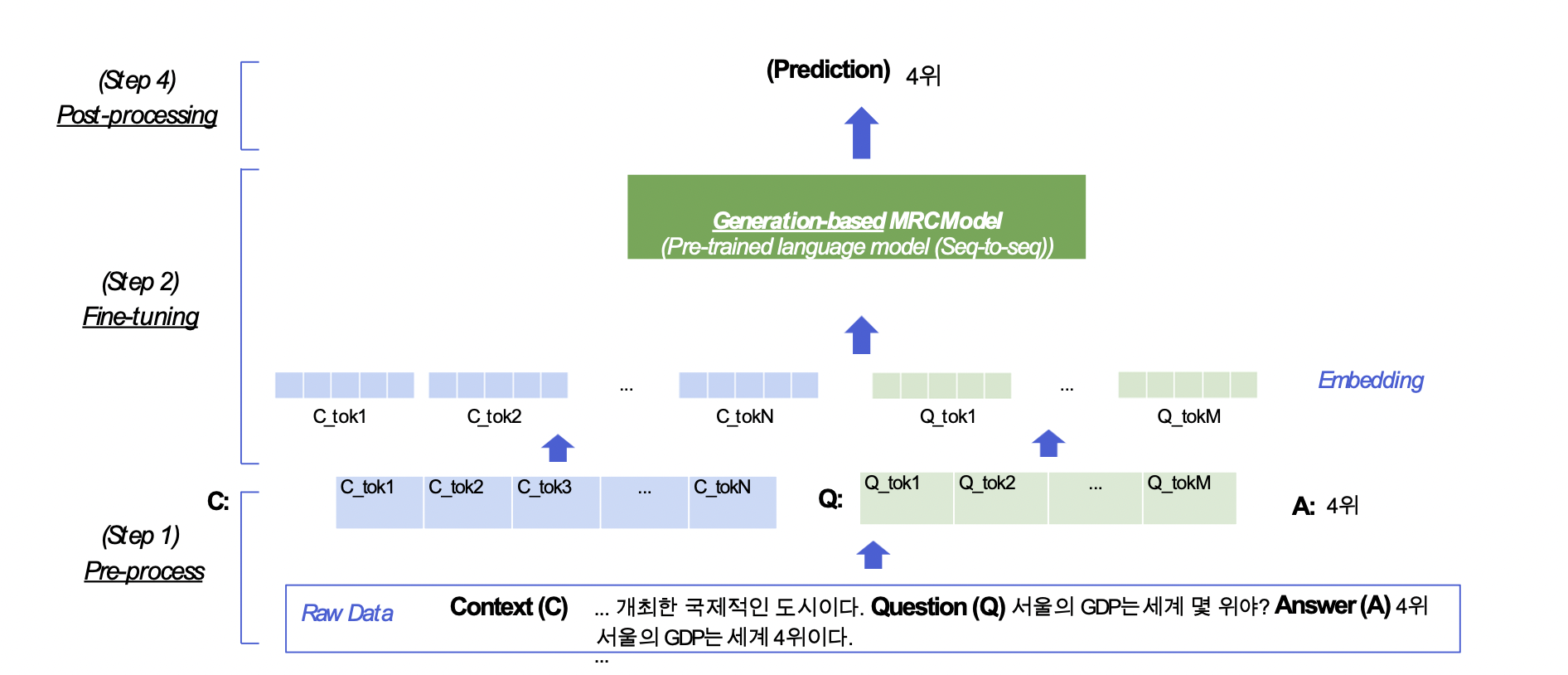
즉, Generation-based mrc는 모델의 Output에서 index를 예측하는 형태가 아닌 정답을 생성해내는 모델이다. 즉 이전 Extractive에서는 정답을 특정할 수 있는 Index를 기반으로 Score를 측정해 정답을 유추했다면, 여기서는 생성해낸 정답을 바탕으로 바로 Metric을 평가할 수 있다.
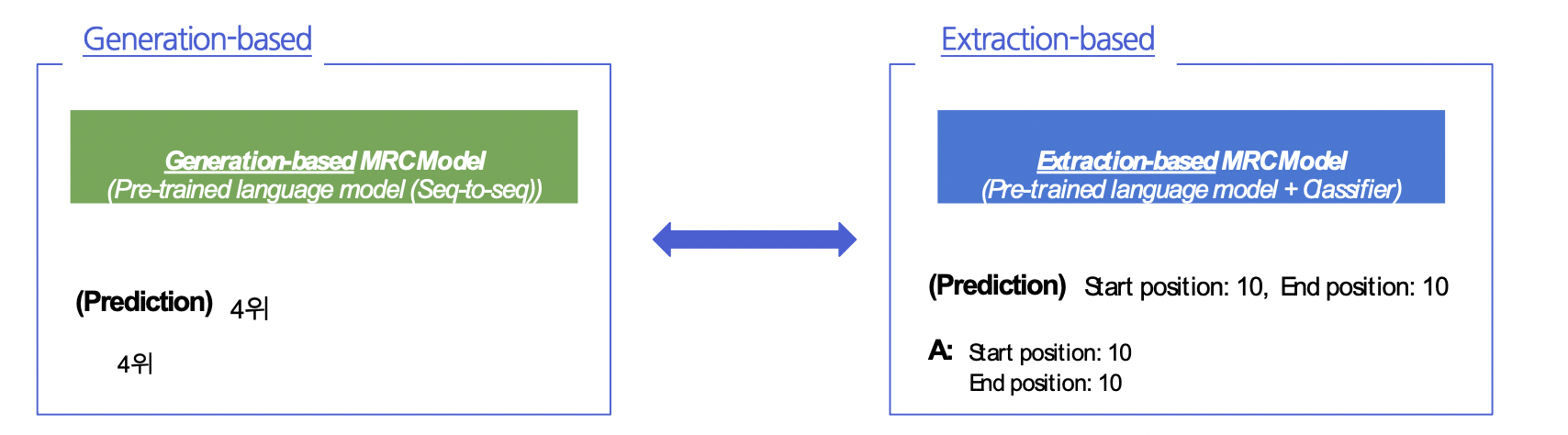
Generation-based MRC vs Extraction-based MRC
1) MRC 모델 구조
Seq-to-seq PLM 구조 (generation) vs. PLM + Classifier 구조 (extraction)
2) Loss 계산을 위한 답의 형태 / Prediction의 형태
Free-form text 형태 + Teacher Forcing (generation) vs. 지문 내 답의 위치 (extraction)
⇒ Extraction-based MRC: F1 계산을 위해 text로의 별도 변환 과정이 필요
Pre-processing
Extract mrc와 달리 정답 텍스트 그 자체를 주면 되기 때문에 오히려 Extract보다 간단하다고 할 수 있다.
입력 표현 - 토큰화
Tokenization(토큰화) : 텍스트를 의미를 가진 작은 단위로 나눈 것 (형태소)
- Extraction-based MRC 와 같이 WordPiece Tokenizer 를 사용함
- WordPiece Tokenizer 사전학습 단계에서 먼저 학습에 사용한 전체 데이터 집합(코퍼스)에
대해서 구축되어 있어야함 - 구축 과정에서 미리 각 단어 토큰들에 대해 순서대로 번호(인덱스)를 부여해둠
-Tokenizer는 입력 텍스트를 토큰화한 뒤, 각 토큰을 미리 만들어둔 단어 사전에 따라 인덱스로 변환함.
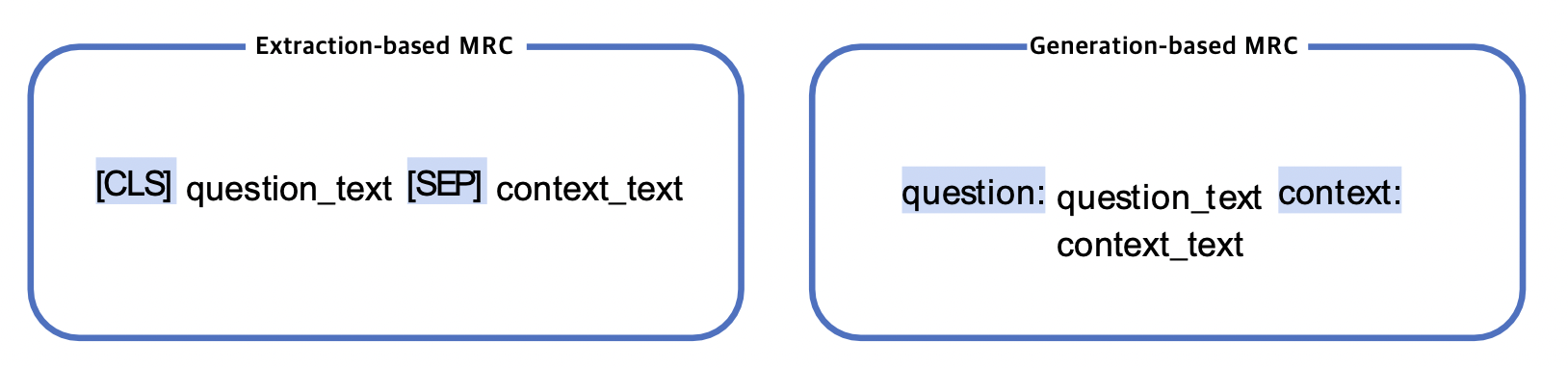
입력 표현 - Special Token
학습 시에만 사용되며 단어 자체의 의미는 가지지 않는 특별한 토큰 -SOS(Start Of Sentence),EOS(End Of Sentence),CLS,SEP,PAD,UNK.. 등등
⇒ Extraction-based MRC에선 CLS,SEP,PAD토큰을사용
⇒ Generation-based MRC 에서도 PAD 토큰은 사용됨. CLS, SEP토큰 또한 사용할 수 있으나, 대신 자연어를 이용하여 정해진 텍스트 포맷(format)으로 데이터를 생성
입력 표현 - additional information
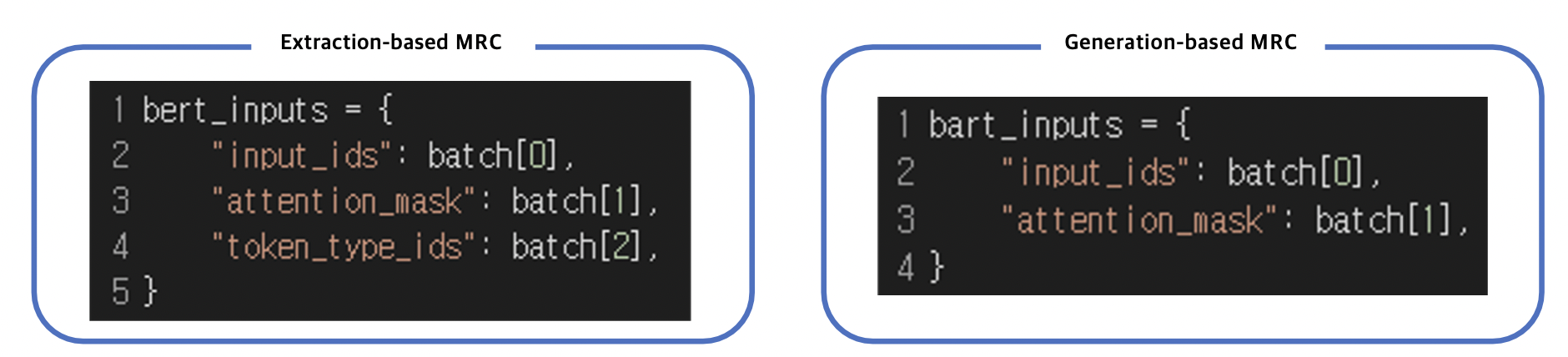
Attention mask
- Extraction-based MRC 와 똑같이 어텐션 연산을 수행할 지 결정하는 어텐션 마스크 존재
Token type ids - BERT 와 달리 BART 에서는 입력시퀀스에 대한 구분이 없어 token_type_ids 가 존재하지 않음 - 따라서 Extraction-based MRC 와 달리 입력에 token_type_ids 가 들어가지 않음
[SEP]토큰이 있으면 Token_type_ids는 어느정도 모델이 구분할 수 있기 때문에 생략한다.
출력 표현 - 정답 출력
Sequence of token ids
- Extraction-based MRC에선 텍스트를 생성해내는 대신 시작/끝 토큰의 위치를 출력하는 것이 모델의 최종 목표였음
- Generation-based MRC는 그보다 조금 더 어려운 실제 텍스트를 생성하는 과제를 수행
- 전체 시퀀스의 각 위치 마다 모델이 아는 모든 단어들 중 하나의 단어를 맞추는 classification 문제
- 모델의 출력을 선형 레이어에 넣음
(seq_length, hidden_dim) -> (seq_length, vocab_size)- Seq_length의 각 위치마다 들어가야할 단어를 하나씩 선택
- 정해진 횟수 또는 전체 길이의 수만큼 반복
Model
BART
기계 독해, 기계 번역, 요약, 대화 등 sequence to sequence 문제의 pre-training을 위한 denoising autoencoder
denoising autoencoder : 노이즈가 없었던 원래 버젼을 reconstruct하는 형태
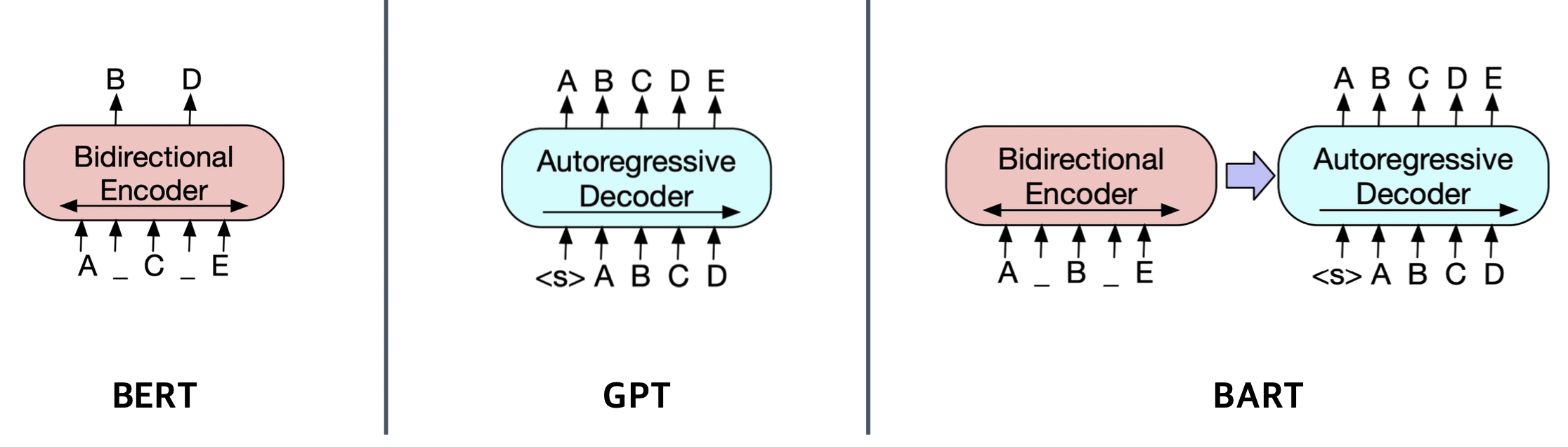
- BART의 인코더는 BERT처럼 bi-directional
- BART의 디코더는 GPT처럼 uni-directional(autoregressive)
Pre-training BART
BART는 텍스트에 노이즈를 주고 원래 텍스트를 복구하는 문제를 푸는 것으로 pre-training함 -> 생성 분야에 강점
Post-Precessing
아래와 같은 다양한 방법으로 생성, 결과물 출력
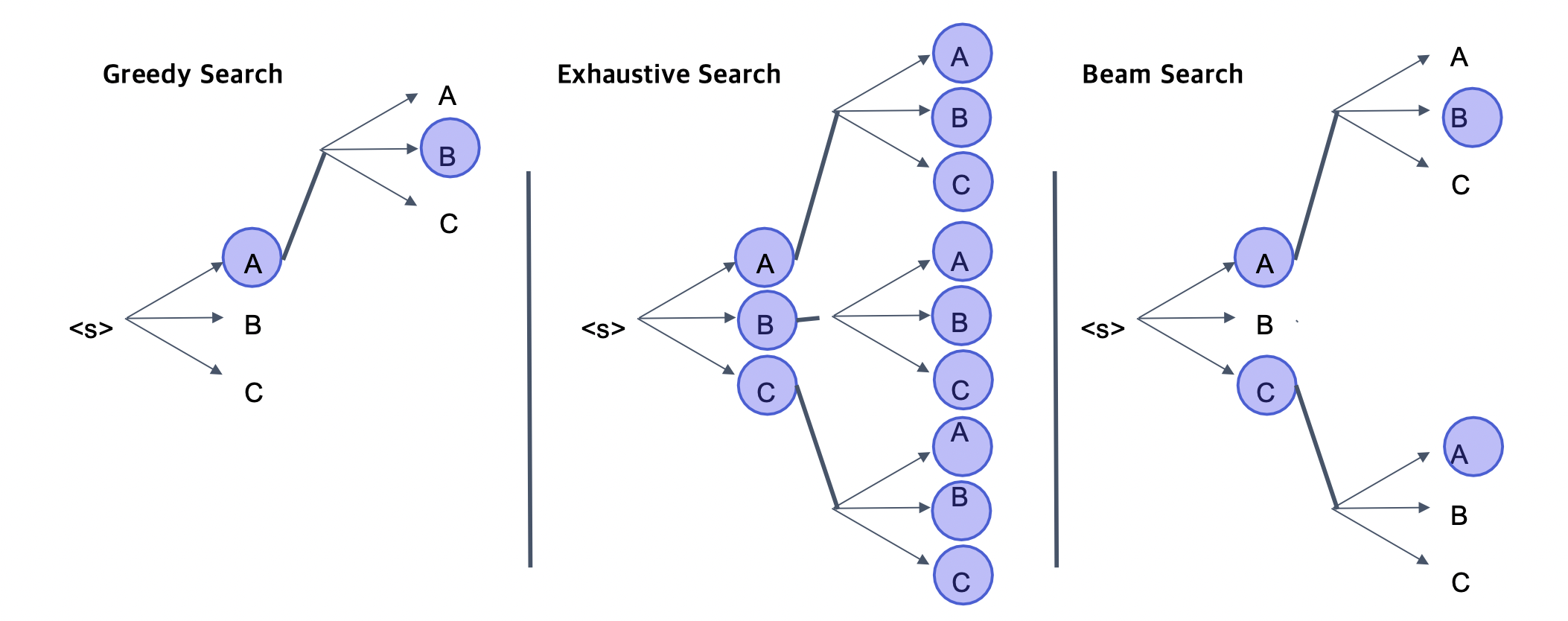
실제로는 Beam Search의 top_k만 유지하는 형식으로 많이 사용한다. Greedy Search는 실제 의미로서 잘못 적용될 가능성이, Exhaustive Search는 너무 많은 Cost소요때문에 사용하기 힘들다.
실습 코드
By mt5.
seq2seq collator : 다른 seq length를 가진 input들을 합쳐줘서 pair computing을 하기 쉽게 만들어준다.
DataCollatorForSeq2Seq
label_pad_token_id = tokenizer.pad_token_id
data_collator = DataCollatorForSeq2Seq(
tokenizer,
model=model,
label_pad_token_id=label_pad_token_id,
pad_to_multiple_of=None,
)