
텍스트 분류
자연어 처리 문제를 대표하는 텍스트 분류(Text Classification)는 NLP기술을 활용하여 특정한 텍스트를 어떠한 범주(Class, Label 등)로 구분하는 문제이다.
텍스트 분류 문제를 해결하기 위해서는 지도학습과 비지도학습의 두가지 방식이 있다.
Label값이 미리 지정되어있는 상태로 학습하는지에 따라 지도/비지도학습으로 구분하는데, 대표적인 지도학습 텍스트 분류 모델은 다음과 같다.
- 나이브 베이즈 분류(Naive Bayes Classifier)
- 서포트 벡터 머신(Support Vector Machine)
- 신경망(Neural Network)
- 선형 분류(Linear Classifier)
- 로지스틱 분류(Logistic Classifier(Regressor이라고도 한다))
- 랜덤포레스트 분류(RandomForest Classifier)
비지도학습의 경우 라벨 값이 미리 정해져있지 않고, 대표적인 예는 K-means 군집화이다.
영어 텍스트 분류 캐글 실습
캐글의 워드 팝콘 문제를 활용할 것이다. 워드 팝콘은 인터넷 영화 데이터베이스(IMDB)에서 나온 영화 평점 데이터를 활용한 캐글 문제다. 영화 평점 데이터이므로 각 데이터는 영화 리뷰 텍스트와 평점에 따른 감정(긍정/부정)으로 구성되어 있다.
텍스트 분류 문제를 해결하기 위한 단계는 3단계 정도로 구성되어 있다.
1. 데이터 분석
2. 데이터 전처리
3. 알고리즘 모델링
먼저 캐글 데이터를 불러오도록 하자. 캐글 활용법은 여기에 설명해두었다.
!kaggle competitions download -c word2vec-nlp-tutorial그 다음, 불러온 데이터는 zip형채이므로 압축해제 과정을 거쳐야한다. python zipfile 라이브러리를 활용해서 문제를 해결할 수 있다.
import zipfile
DATA_IN_PATH = './'
file_list = ['labeledTrainData.tsv.zip', 'unlabeledTrainData.tsv.zip', 'testData.tsv.zip']
for file in file_list:
zipRef = zipfile.ZipFile(DATA_IN_PATH + file, 'r')
zipRef.extractall(DATA_IN_PATH)
zipRef.close()데이터 분석
데이터 분석은 아래와 같은 순서로 진행한다.
1. 데이터 크기
2. 데이터의 개수
3. 각 리뷰의 문자 길이 분포
4. 많이 사용된 단어
5. 긍정, 부정 데이터의 분포
6. 각 리뷰의 단어 개수 분포
7. 특수문자 및 대문자, 소문자 비율
- 데이터 크기 확인
print("파일 크기 : ")
for file in os.listdir(DATA_IN_PATH):
if 'tsv' in file and 'zip' not in file:
print(file.ljust(30) + str(round(os.path.getsize(DATA_IN_PATH + file) / 1000000, 2)) + 'MB')
- 데이터의 개수
먼저 라벨링 되어있는 학습 데이터 tsv파일을 불러와 pandas로 읽은 다음, 데이터 개수를 출력한다.
train_data = pd.read_csv( DATA_IN_PATH + 'labeledTrainData.tsv', header = 0, delimiter = '\t', quoting = 3)
print('전체 학습데이터의 개수: {}'.format(len(train_data)))- 각 리뷰의 문자 길이 분포
먼저 리뷰 별로 문자 길이를 담고있는 Series를 생성한 뒤, 이를 히스토그램으로 그린다. 참고로 y값이 지나치게 편향된 모습을 나타내기 때문에 log를 취해서 분포를 시각적으로 확실히 파악할 수 있다.
train_length = train_data['review'].apply(len)
plt.figure(figsize=(12, 5))
plt.hist(train_length, bins=200, alpha=0.5, color= 'r', label='word')
plt.yscale('log', nonposy='clip')
plt.title('Log-Histogram of length of review')
plt.xlabel('Length of review')
plt.ylabel('Number of review')로그를 취했을 때와 그렇지 않을 때의 그래프 결과는 다음과 같다.


그래프를 보면 대부분의 데이터가 문자 길이 6000 이하로 구성되어 있고, 대부분 2000 이하에 분포하고 있다는 것을 알 수 있다. 또한 아래 그래프에서 10000 이상의 이상치 데이터도 검출된다는 것을 확인할 수 있다. 이제 몇 가지 통계값들을 확인해보겠다.
print('리뷰 길이 최대 값: {}'.format(np.max(train_length)))
print('리뷰 길이 최소 값: {}'.format(np.min(train_length)))
print('리뷰 길이 평균 값: {:.2f}'.format(np.mean(train_length)))
print('리뷰 길이 표준편차: {:.2f}'.format(np.std(train_length)))
print('리뷰 길이 중간 값: {}'.format(np.median(train_length)))
print('리뷰 길이 제 1 사분위: {}'.format(np.percentile(train_length, 25)))
print('리뷰 길이 제 3 사분위: {}'.format(np.percentile(train_length, 75)))
평균은 약 1300, 최댓값은 약 13000에 해당한다는 사실을 알 수 있다. 위 내용을 바탕으로 박스 플롯을 그려보자.
plt.figure(figsize=(12, 5))
plt.boxplot(train_length,
labels=['counts'],
showmeans=True)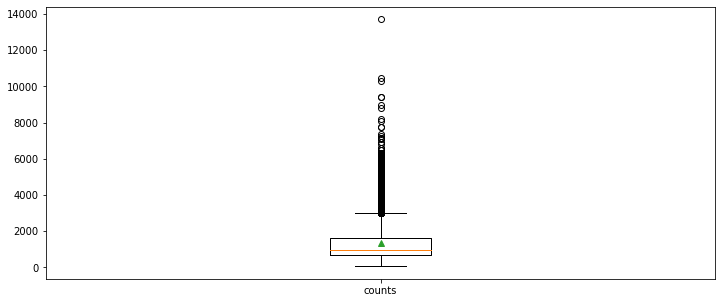
박스플롯을 보면 대부분 2000 이하의 데이터이지만 4000 이상의 이상치 데이터도 꽤 보이는 모습을 알 수 있다.
- 많이 사용된 단어
많이 사용된 단어를 가장 시각적으로 자연스럽게 알 수 있는 방식은 워드클라우드이다.
from wordcloud import WordCloud
cloud = WordCloud(width=800, height=600).generate(" ".join(train_data['review']))
plt.figure(figsize=(20, 15))
plt.imshow(cloud)
plt.axis('off')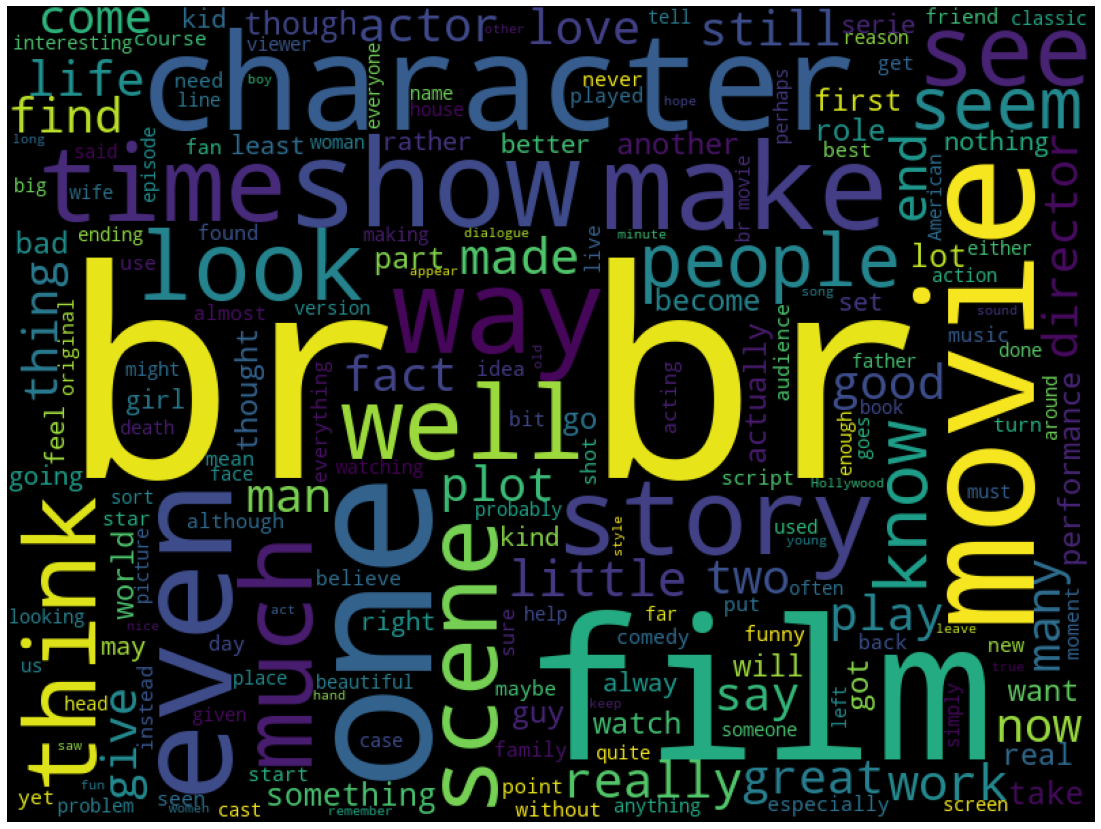
이미지에서 알 수 있듯이, br이라는 HTML태그가 가장 눈에 띈다. 이후 전처리 과정에서 삭제하는 작업이 필요하다는 것을 알 수 있다. 또한 Python wordcloud 모듈은 따로 설정하지 않더라도 자동으로 불용어를 제거하는 것이 디폴트이다.
참고로 정제되지 않은 형태의 데이터에서 가장 많이 나오는 단어를 확인하는 방법은 python Counter 라이브러리를 활용하면 간단하다.
from collections import Counter
review = list((" ".join(train_data['review'])).split())
reviewFreq = Counter(review).most_common()결과는 예상했겠지만 a, the, is 와 같은 불용어들이다.
- 긍정, 부정 데이터의 분포
fig, axe = plt.subplots(ncols=1)
fig.set_size_inches(6, 3)
sns.countplot(train_data['sentiment'])
- 각 리뷰의 단어 개수 분포
train_word_counts = train_data['review'].apply(lambda x:len(x.split(' ')))
plt.figure(figsize=(15, 10))
plt.hist(train_word_counts, bins=50, facecolor='r',label='train')
plt.title('Log-Histogram of word count in review', fontsize=15)
plt.yscale('log', nonposy='clip')
plt.legend()
plt.xlabel('Number of words', fontsize=15)
plt.ylabel('Number of reviews', fontsize=15)각 리뷰별 단어가 몇 개로 구성되어 있는지 알아보는 방법도 위와 유사하게 진행한다.
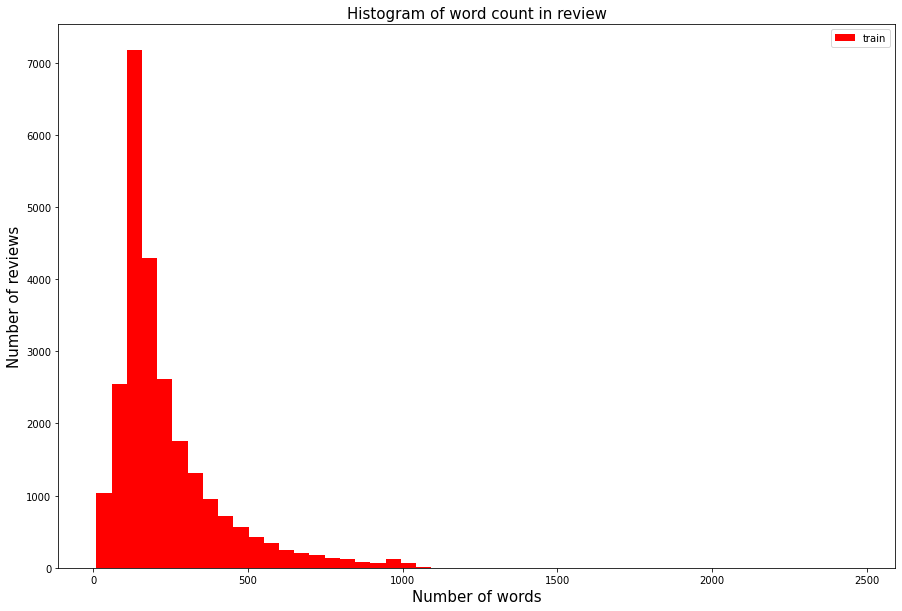
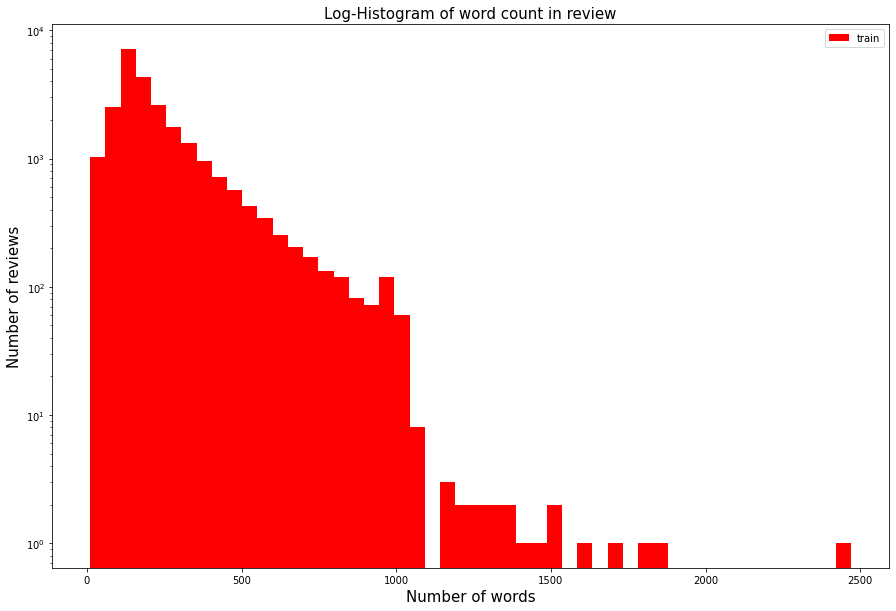
log로 표현해서 2500자의 이상치 데이터들을 확인할 수 있다.
단어 개수의 통계값들은 다음과 같다.
print('리뷰 단어 개수 최대 값: {}'.format(np.max(train_word_counts)))
print('리뷰 단어 개수 최소 값: {}'.format(np.min(train_word_counts)))
print('리뷰 단어 개수 평균 값: {:.2f}'.format(np.mean(train_word_counts)))
print('리뷰 단어 개수 표준편차: {:.2f}'.format(np.std(train_word_counts)))
print('리뷰 단어 개수 중간 값: {}'.format(np.median(train_word_counts)))
# 사분위의 대한 경우는 0~100 스케일로 되어있음
print('리뷰 단어 개수 제 1 사분위: {}'.format(np.percentile(train_word_counts, 25)))
print('리뷰 단어 개수 제 3 사분위: {}'.format(np.percentile(train_word_counts, 75)))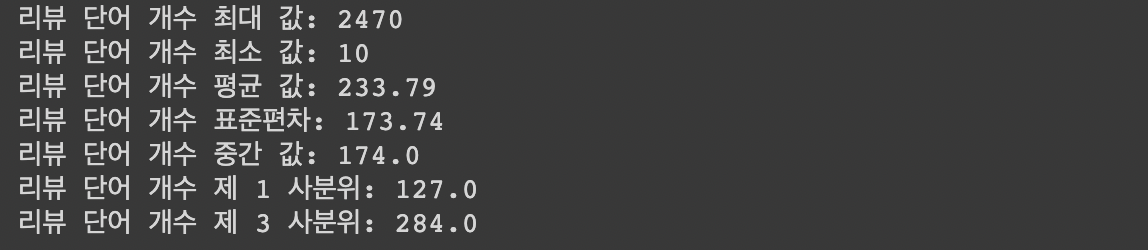
- 특수문자 및 대문자, 소문자 비율
qmarks = np.mean(train_data['review'].apply(lambda x: '?' in x)) # 물음표가 구두점으로 쓰임
fullstop = np.mean(train_data['review'].apply(lambda x: '.' in x)) # 마침표
capital_first = np.mean(train_data['review'].apply(lambda x: x[0].isupper())) # 첫번째 대문자
capitals = np.mean(train_data['review'].apply(lambda x: max([y.isupper() for y in x]))) # 대문자가 몇개
numbers = np.mean(train_data['review'].apply(lambda x: max([y.isdigit() for y in x]))) # 숫자가 몇개
print('물음표가있는 질문: {:.2f}%'.format(qmarks * 100))
print('마침표가 있는 질문: {:.2f}%'.format(fullstop * 100))
print('첫 글자가 대문자 인 질문: {:.2f}%'.format(capital_first * 100))
print('대문자가있는 질문: {:.2f}%'.format(capitals * 100))
print('숫자가있는 질문: {:.2f}%'.format(numbers * 100))여기까지 데이터 분석을 간단하게 진행해보았다. 지금부터는 여기서 얻은 정보들을 바탕으로 데이터 전처리 작업을 실시한다.
데이터 전처리
데이터를 일부 확인해보면,
DATA_IN_PATH = './'
train_data = pd.read_csv( DATA_IN_PATH + 'labeledTrainData.tsv', header = 0, delimiter = '\t', quoting = 3)
print(train_data['review'][0])"With all this stuff going down at the moment ... bad m'kay.
Visually impressive but of course this is all ... hope he is not the latter."
와 같이 HTML태그가 일부 들어있음을 알 수 있다. 따라서 BeautifulSoup을 이용해서 HTML태그를 제거하는 작업을 진행해야 한다.
또한, 감정 분석에서 조사나 관사와 같은 것들이 큰 의미를 가지지 않을 가능성이 높으므로 NLTK의 STOPWORDS를 사용해 불용어 제거를 거치는 것이 좋아보인다. 한편 불용어사전은 소문자로만 구성되어 있으므로 소문자로 바꾼 후에 진행하는 것이 좋다. 또, 정규표현식(re)를 사용하여 특수문자들도 모두 삭제하는 과정을 거치도록 하겠다.
이 과정을 모두 결합해서 하나의 함수로 구성해보면 다음과 같다.
import re
import json
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup
from nltk.corpus import stopwords
# 불용어 사전 다운로드 받기
# import nltk
# nltk.download('stopwords')
def preprocessing( review, remove_stopwords = False ):
# 불용어 제거는 옵션으로 선택 가능하다.
# 1. HTML 태그 제거
review_text = BeautifulSoup(review, "html5lib").get_text()
# 2. 영어가 아닌 특수문자들을 공백(" ")으로 바꾸기
review_text = re.sub("[^a-zA-Z]", " ", review_text)
# 3. 대문자들을 소문자로 바꾸고 공백단위로 텍스트들 나눠서 리스트로 만든다.
words = review_text.lower().split()
if remove_stopwords:
# 4. 불용어들을 제거
#영어에 관련된 불용어 불러오기
stops = set(stopwords.words("english"))
# 불용어가 아닌 단어들로 이루어진 새로운 리스트 생성
words = [w for w in words if not w in stops]
# 5. 단어 리스트를 공백을 넣어서 하나의 글로 합친다.
clean_review = ' '.join(words)
else: # 불용어 제거하지 않을 때
clean_review = ' '.join(words)
return clean_review
#정제된 리뷰 데이터 만들기
clean_train_reviews = []
for review in train_data['review']:
clean_train_reviews.append(preprocessing(review, remove_stopwords = True))
이렇게 정제된 리뷰들을 만들었다면, 정제된 리뷰와 해당하는 감정을 컬럼으로 가지는 DataFrame을 만들어 저장하자.
clean_train_df = pd.DataFrame({'review': clean_train_reviews, 'sentiment': train_data['sentiment']})이제 텍스트 데이터를 정제했다면, 모델에 학습시킬 시 input 데이터의 길이가 같아지도록 Padding 과정을 거쳐야 한다. 이 과정을 진행하기 위해서는 Tensorflow Tokenizer를 사용해 텍스트 리뷰 데이터를 단어 사전에 따른 인덱스 데이터로 바꾼 뒤, pad_sequences함수를 사용하면 된다.
# tokenizer 생성
tokenizer = Tokenizer()
tokenizer.fit_on_texts(clean_train_reviews)
text_sequences = tokenizer.texts_to_sequences(clean_train_reviews)
# 단어 사전
word_vocab = tokenizer.word_index
word_vocab["<PAD>"] = 0
# 최대 길이는 중간값 기준
MAX_SEQUENCE_LENGTH = 174
train_inputs = pad_sequences(text_sequences, maxlen=MAX_SEQUENCE_LENGTH, padding='post')
print('Shape of train data: ', train_inputs.shape)여기까지 전처리 작업을 마쳤다면 본격적으로 모델에 활용하기 전에 정제된 파일들을 적절하게 저장해주어야한다. 특히 Colab을 쓰고 있다면 런타임이 초기화되어서 파일이 날라갈 수 있으므로 구글 드라이브 연동 후 파일을 저장해주면 불필요한 추가 작업을 막을 수 있다. 저장할 파일들은 다음과 같다.
- 정제된 텍스트 데이터
- 벡터화된 데이터
- 정답 Label
- 데이터 정보(단어 사전, 전체 단어 개수(PAD 포함))
TRAIN_CLEAN_DATA = 'train_clean.csv'
TRAIN_INPUT_DATA = 'train_input.npy'
TRAIN_LABEL_DATA = 'train_label.npy'
DATA_CONFIGS = 'data_configs.json'
import os
# 저장하는 디렉토리가 존재하지 않으면 생성
# 디렉토리 만들기는 기본이니 아래와 같은 코드는 알아두는게 좋다.
if not os.path.exists(DATA_IN_PATH):
os.makedirs(DATA_IN_PATH)
# 전처리 된 데이터를 넘파이 형태로 저장
np.save(open(DATA_IN_PATH + TRAIN_INPUT_DATA, 'wb'), train_inputs)
np.save(open(DATA_IN_PATH + TRAIN_LABEL_DATA, 'wb'), train_labels)
# 정제된 텍스트를 csv 형태로 저장
clean_train_df.to_csv(DATA_IN_PATH + TRAIN_CLEAN_DATA, index = False)
# 데이터 사전을 json 형태로 저장
json.dump(data_configs, open(DATA_IN_PATH + DATA_CONFIGS, 'w'), ensure_ascii=False)위의 저장을 마무리했다면, Test데이터에 대해서도 Train데이터에 한 것과 같은 작업을 반복한다. 참고로, tokenizer는 train데이터에서 fit되어있는 tokenizer객체를 사용해서 sequences로 바꿔준다.
test_data = pd.read_csv(DATA_IN_PATH + "testData.tsv", header=0, delimiter="\t", quoting=3)
clean_test_reviews = []
for review in test_data['review']:
clean_test_reviews.append(preprocessing(review, remove_stopwords = True))
clean_test_df = pd.DataFrame({'review': clean_test_reviews, 'id': test_data['id']})
test_id = np.array(test_data['id'])
text_sequences = tokenizer.texts_to_sequences(clean_test_reviews)
test_inputs = pad_sequences(text_sequences, maxlen=MAX_SEQUENCE_LENGTH, padding='post')
TEST_INPUT_DATA = 'test_input.npy'
TEST_CLEAN_DATA = 'test_clean.csv'
TEST_ID_DATA = 'test_id.npy'
np.save(open(DATA_IN_PATH + TEST_INPUT_DATA, 'wb'), test_inputs)
np.save(open(DATA_IN_PATH + TEST_ID_DATA, 'wb'), test_id)
clean_test_df.to_csv(DATA_IN_PATH + TEST_CLEAN_DATA, index = False)여기까지 마무리했다면 텍스트 데이터 모델링을 위한 준비작업이 마무리 되었다. 다음 글에는 여기서 준비된 파일을 바탕으로 텍스트 분류 모델을 만들어보겠다.
