
이전 글에서 텍스트 데이터를 분석해보고, 벡터화 및 전처리 작업까지 마무리했다.
이제 본격적으로 텍스트 데이터 분류 모델 개발 작업을 시작할텐데, 먼저 앞서 정제된 텍스트 데이터를 활용해서 문장 벡터를 만들어 주어야한다. 가장 먼저 알아볼 모델은 앞서 공부했던 Tf-idf를 사용해서 문장 벡터를 만들고, LogisticRegression을 활용해서 이진 분류 모델을 만들어보겠다.
LogisticRegression
참고로 앞서 저장했던 파일들은 data 폴더 안으로 이동시킨 뒤 진행하는 작업이다.
import os
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
DATA_IN_PATH = './data/'
DATA_OUT_PATH = './data_out/'
TRAIN_CLEAN_DATA = 'train_clean.csv'
# 동일한 결과를 위해 랜덤 시드값을 지정한다.
RANDOM_SEED = 28
TEST_SPLIT = 0.2이제 Tf-idf 벡터화를 진행한다. 각각의 파라미터에 대한 해석은 다음과 같다.
- min_df :
설정한 값보다 특정 토큰의 df값이 더 적게 나오면 벡터화 과정에서 제거한다는 의미이다.
참고로 DF는 document frequency의 약자이다. - analyzer :
분석하기 위한 기준 단위. word, char 두 가지 옵션이 있는데, word는 단어 하나를 단위로 하고 char는 문자 하나를 단위로 한다. - sublinear_tf :
문서의 단어 빈도 수(TF, term frequency)에 대한 스무딩 여부. - ngram_range :
빈도의 기본 단위를 어느 범위의 n-gram으로 설정할 것인지 물어보는 것. - max_features :
각 벡터의 최대 길이, 특징의 길이
tf-idf로 벡터화를 진행하면 바로 학습/검증 데이터 분리를 해준다.
# 데이터 불러오기
train_data = pd.read_csv( DATA_IN_PATH + TRAIN_CLEAN_DATA )
# 리뷰, 감정 데이터 할당
reviews = list(train_data['review'])
sentiments = list(train_data['sentiment'])
# tf-idf 벡터화
vectorizer = TfidfVectorizer(min_df = 0.0, analyzer="char", sublinear_tf=True, ngram_range=(1,3), max_features=5000)
X = vectorizer.fit_transform(reviews)
y = np.array(sentiments)
X_train, X_eval, y_train, y_eval = train_test_split(X, y, test_size=TEST_SPLIT, random_state=RANDOM_SEED)이후 성능을 평가하고 기본 모델만 활용했을 때의 모델을 바탕으로 예측값 파일을 생성한다.
lgs = LogisticRegression(class_weight='balanced')
lgs.fit(X_train, y_train)
predicted = lgs.predict(X_eval)
print("Accuracy: %f" % lgs.score(X_eval, y_eval))#파일 불러오기
TEST_CLEAN_DATA = 'test_clean.csv'
test_data = pd.read_csv(DATA_IN_PATH + TEST_CLEAN_DATA)
#테스트 데이터 tf-idf벡터화
testDataVecs = vectorizer.transform(test_data['review'])
#예측
test_predicted = lgs.predict(testDataVecs)
#저장
if not os.path.exists(DATA_OUT_PATH):
os.makedirs(DATA_OUT_PATH)
answer_dataset = pd.DataFrame({'id': test_data['id'], 'sentiment': test_predicted})
answer_dataset.to_csv(DATA_OUT_PATH + 'lgs_tfidf_answer.csv', index=False, quoting=3)캐글에 제출 시 다음과 같은 결과를 얻을 수 있다.

word2vec lightgbm
이번에는 tf-idf 대신 word2vec으로 벡터화를 진행하고, lightgbm을 사용한 분류 모델을 만들어보려고 한다.
기본적으로 사용할 pandas와 numpy, 그리고 beautifulsoup과 nltk를 import한다. 추가적으로 사용될 변수와 경로를 지정하자.
import os
import re
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
import nltk
nltk.download('stopwords')
DATA_IN_PATH = './data/'
TRAIN_CLEAN_DATA = 'train_clean.csv'
RANDOM_SEED = 28
TEST_SPLIT = 0.2이제 파일을 불러오자. tf-idf에서 문장을 받아서 변환했던 것과는 다르게 단어 단위로 쪼개서 넣어야 Word2Vec을 사용할 수 있다. 따라서 split()함수를 활용한다.
train_data = pd.read_csv(DATA_IN_PATH + TRAIN_CLEAN_DATA)
reviews = list(train_data['review'])
sentiments = list(train_data['sentiment'])
sentences = []
for review in reviews:
sentences.append(review.split())이제 word2vec 모델 학습을 진행하기 이전에, 하이퍼파라미터 값을 알아보겠다.
- num_features :
각 단어에 대해 임베딩된 벡터의 차원 - min_word_count :
모델에 의미 있는 단어를 가지고 학습하기 위해 적은 빈도 수의 단어들은 학습하지 않는다. - num_workers :
모델 학습 시 사용할 프로세스 개수를 지정한다. - context :
컨텍스트 윈도우 크기를 지정한다. - downsampling :
학습을 수행할 때 빠른 학습을 위해 정답 단어 라벨에 대한 다운샘플링 비율을 지정한다. 일반적으로 0.001이 가장 성능이 좋다고 한다.
num_features = 300
min_word_count = 40
num_workers = 4
context = 10
downsampling = 1e-3 학습 시 진행 상황을 알아보기 위해 log를 출력할 수 있다. log는 INFO수준으로 지정하면 알맞은 정보들을 확인하며 학습을 수행할 수 있다.
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s',\
level=logging.INFO)
from gensim.models import word2vec
model = word2vec.Word2Vec(sentences, workers=num_workers, \
size=num_features, min_count = min_word_count, \
window = context, sample = downsampling)
# 모델 저장, word2vec.load()를 사용해서 추후에 다시 사용할 수 있다.
model_name = "w2v_300features_40minwords_10context"
model.save(model_name)여기까지 word2vec 학습을 완료했다. 이제 예측 모델 학습을 위해 리뷰들을 같은 형태의 입력값으로 만들어야 한다. 여기서는 리뷰 내의 단어 벡터값에 대해 평균을 내서 리뷰 하나당 하나의 벡터를 출력하는 형식으로 만들어볼 것이다.
다음의 함수는 하나의 리뷰에 대해 전체 단어의 평균값을 계산하는 함수이다.
words는 하나의 리뷰에 포함된 단어의 모임이다. model은 word2vec 모델이며, num_features는 사전에 임베딩 시 지정했던 벡터의 차원 수이다.
def get_features(words, model, num_features):
feature_vector = np.zeros((num_features),dtype=np.float32)
num_words = 0
index2word_set = set(model.wv.index2word)
for w in words:
if w in index2word_set:
num_words += 1
feature_vector = np.add(feature_vector, model[w])
feature_vector = np.divide(feature_vector, num_words)
return feature_vector이제 위의 함수를 이용해서 전체 리뷰에 대한 평균값을 계산하는 함수를 만들고, 실행시키자.
reviews는 학습 데이터, 전체 리뷰 데이터를 의미하고 model은 word2vec모델, num_features는 사전에 임베딩 시 지정했던 벡터의 차원 수이다.
def get_dataset(reviews, model, num_features):
dataset = list()
for s in reviews:
dataset.append(get_features(s, model, num_features))
reviewFeatureVecs = np.stack(dataset)
return reviewFeatureVecs
# 실행
test_data_vecs = get_dataset(sentences, model, num_features)이제 학습 데이터인 test_data_vecs가 만들어졌다. 이를 바탕으로 lightgbm 모델을 활용한 모델 학습을 진행해보자.
from sklearn.model_selection import train_test_split
import numpy as np
X = test_data_vecs
y = np.array(sentiments)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=TEST_SPLIT, random_state=RANDOM_SEED)
from lightgbm import LGBMClassifier
lgbm = LGBMClassifier(n_estimators=500)
lgbm.fit(X_train, y_train, early_stopping_rounds=100, eval_metric="auc", eval_set=[(X_test,y_test)], verbose = True)평가지표는 ROC-AUC 값이기 때문에 eval_metric을 auc값으로 잡아주었다. 이제 테스트 데이터에 학습된 모델을 적용시켜 최종 제출을 해보자.
TEST_CLEAN_DATA = 'test_clean.csv'
test_data = pd.read_csv(DATA_IN_PATH + TEST_CLEAN_DATA)
test_review = list(test_data['review'])
test_sentences = list()
for review in test_review:
test_sentences.append(review.split())
test_data_vecs = get_dataset(test_sentences, model, num_features)
DATA_OUT_PATH = './data_out/'
test_predicted = lgbm.predict(test_data_vecs)
if not os.path.exists(DATA_OUT_PATH):
os.makedirs(DATA_OUT_PATH)
ids = list(test_data['id'])
answer_dataset = pd.DataFrame({'id': ids, 'sentiment': test_predicted})
answer_dataset.to_csv(DATA_OUT_PATH + 'lgbm_w2v_answer_1000estimators.csv', index=False, quoting=3)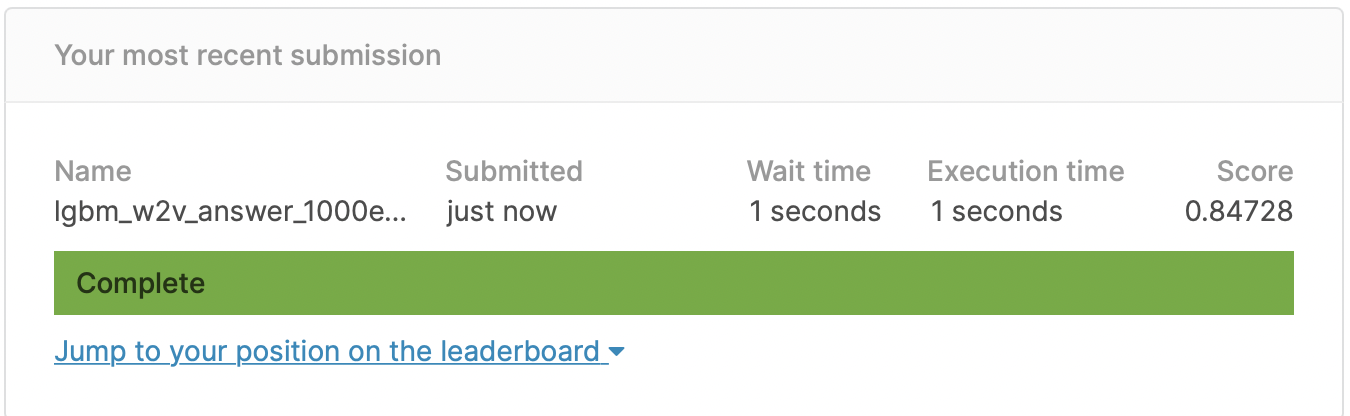
word2vec에 lightgbm을 사용했는데 tf-idf에 로지스틱 회귀를 사용한 값보다 떨어지는 결과가 나왔다. word2vec이 모든 경우에 tf-idf보다 좋은 성능을 보이는 것은 아니며, 데이터의 양에 따라서도 다를 수 있다는 것을 명심해야한다. lightgbm 역시 좋은 성능을 보이긴 하지만 데이터의 양잉 10,000건 이하일 경우 성능이 좋지 않고, 과적합의 가능성이 있기 때문에 언제나 예측 모델을 개발하는 과정에서는 다양한 경우의 수를 생각해보는 것이 좋다.
다음 글에서는 RNN,CNN을 활용한 텍스트 데이터 분류 문제를 해결해보도록 하겠다.
