
이전 글은 머신러닝을 활용한 모델이었다. 지금 부터는 딥러닝모델을 활용한 분류 모델을 알아보도록 하겠다. 가장 먼저 RNN이다.
RNN이란?
RNN(순환 신경망,Recurrent Neural Network)은 언어 모델에서 많이 쓰이는 딥러닝 모델 중 하나이다.
- 주로 순서가 있는 데이터, 즉 문장 데이터를 입력해 문장 흐름에서 패턴을 찾아 분류하게 한다. 앞선 모델들과 달리, 이미 주어진 단어 특징 벡터를 활용해 모델을 학습하지 않고 텍스트 정보를 입력해서 문장에 대한 특징 정보를 추출한다.
- RNN은 이전 정보가 점층적으로 쌓이면서 현재 정보를 표현하는 모델이다. 따라서 시간에 의존적인 또는 순차적인 데이터에 대한 문제에 활용된다.
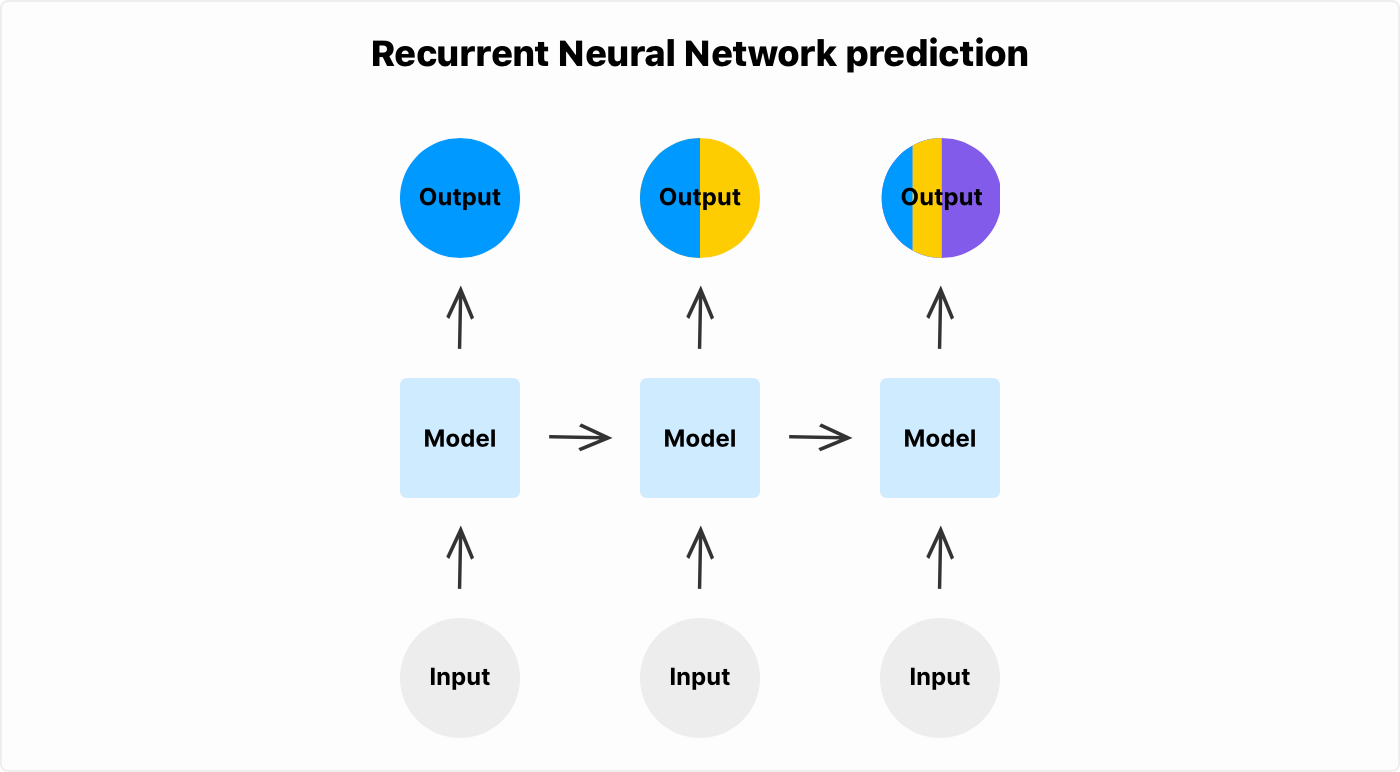
이번 영화 평점 리뷰 데이터를 생각하면, 입력으로 문장을 순차적으로 넣어주고, RNN의 구조에 따라 순환적으로 input-output을 반복하다 마지막으로 출력된 벡터를 바탕으로 이진 분류를 진행하는 것이다.
필요한 모듈들을 import하고, 경로 정의, 랜덤 시드 고정을 진행한다. 랜덤 시드를 고정해야 학습 시 랜덤 변수에 대한 상태를 고정해서 성능을 보다 정확히 비교할 수 있다.
import tensorflow as tf
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from tensorflow.keras import layers
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
import json
from tqdm import tqdm
# 경로 정의
DATA_IN_PATH = './data/'
DATA_OUT_PATH = './data_out/'
TRAIN_INPUT_DATA = 'train_input.npy'
TRAIN_LABEL_DATA = 'train_label.npy'
DATA_CONFIGS = 'data_configs.json'
# 랜덤 시드 고정
SEED_NUM = 1234
tf.random.set_seed(SEED_NUM)
# 시각화 함수 정의
def plot_graphs(history, string):
plt.plot(history.history[string])
plt.plot(history.history['val_'+string], '')
plt.xlabel("Epochs")
plt.ylabel(string)
plt.legend([string, 'val_'+string])
plt.show()이제 저장했던 numpy.array파일들을 np.load()함수를 사용하여 불러오자. 또, 단어 임베딩 크기를 정의할 때 활용하기 위해 json파일로 저장된 데이터 사전정보 파일을 불러온다.
train_input = np.load(open(DATA_IN_PATH + TRAIN_INPUT_DATA, 'rb'))
train_label = np.load(open(DATA_IN_PATH + TRAIN_LABEL_DATA, 'rb'))
prepro_configs = json.load(open(DATA_IN_PATH + DATA_CONFIGS, 'r'))그 다음 모델 하이퍼 파라미터를 정의한다.
model_name = 'rnn_classifier_en'
BATCH_SIZE = 128
NUM_EPOCHS = 5
VALID_SPLIT = 0.1
MAX_LEN = train_input.shape[1]
kargs = {'model_name': model_name,
'vocab_size': prepro_configs['vocab_size'],
'embedding_dimension': 100,
'dropout_rate': 0.2,
'lstm_dimension': 150,
'dense_dimension': 150,
'output_dimension':1}모델을 선언하기 위해서는 Class를 선언하여 객체를 생성하는 형식으로 진행할 것이다. tf.keras.Model을 상속받아 Model 형태로 만들어지는 클래스이며, __init__함수(객체를 생성할 때마다 실행)에서는 앞서 선언한 kargs라는 모델 레이어의 입력, 출력 차원 수를 정의하는 하이퍼 파라미터 정보를 dict 객체로 받는다.
먼저 layers.embedding 객체를 생성해서 self.embedding에 저장한다. 입력 차원 수는 단어 사전 사이즈를 넣는다. 우리가 Tokenizer객체를 통해 만들었던 단어 사전과 임베딩을 사용하기 때문이다.
그 다음은 RNN 분류기 중 하나인 LSTM 레이어를 추가해주었다. return_sequence 값을 통해 은닉 상태의 벡터를 출력시켜 확인할 수 있다.
그리고 RNN에서 출력한 상태 벡터가 피드 포워드 네트워크를 거치게 하도록 Dense 레이어를 만들어 주어야한다. 먼저 tanh를 사용해서 출력 차원 수가 dense_dimension이 되는 Dense레이어를 추가한다. 마지막으로 출력으로 확인할 때 1차원의 데이터가 나오도록 units를 1로 지정하고, 활성 함수를 시그모이드 함수를 사용해준다.
추가로 과적합을 방지하기 위해 0.2의 확률로 dropout을 진행하는 함수도 추가한다.
이제 call() 함수를 입력하면 임베딩부터 마지막 예측값을 출력하는 과정까지 한 번에 진행하도록 만든다.
class RNNClassifier(tf.keras.Model):
def __init__(self, **kargs):
super(RNNClassifier, self).__init__(name=kargs['model_name'])
self.embedding = layers.Embedding(input_dim=kargs['vocab_size'],
output_dim=kargs['embedding_dimension'])
self.lstm_1_layer = tf.keras.layers.LSTM(kargs['lstm_dimension'], return_sequences=True)
self.lstm_2_layer = tf.keras.layers.LSTM(kargs['lstm_dimension'])
self.dropout = layers.Dropout(kargs['dropout_rate'])
self.fc1 = layers.Dense(units=kargs['dense_dimension'],
activation=tf.keras.activations.tanh)
self.fc2 = layers.Dense(units=kargs['output_dimension'],
activation=tf.keras.activations.sigmoid)
def call(self, x):
x = self.embedding(x)
x = self.dropout(x)
x = self.lstm_1_layer(x)
x = self.lstm_2_layer(x)
x = self.dropout(x)
x = self.fc1(x)
x = self.dropout(x)
x = self.fc2(x)
return x이제 본격적으로 모델을 생성해보자. 앞서 구현한 RNN Class를 통해 객체를 생성하고, 옵티마이저와 loss함수, 그리고 평가지표를 compile해준다.
model = RNNClassifier(**kargs)
model.compile(optimizer=tf.keras.optimizers.Adam(1e-4),
loss=tf.keras.losses.BinaryCrossentropy(),
metrics=[tf.keras.metrics.BinaryAccuracy(name='accuracy')])그 다음은 모델 학습을 위해 필요한 Earlystopping과 ModelCheckPoint를 사용한 Callback함수를 선언한다.
EearlyStopping은 오버피팅을 방지하기 위해서 평가 점수가 이전 점수보다 일정 수치 미만으로 떨어질 경우 학습을 멈추는 역할을 한다. val_accuracy를 검증 평가 점수로 활용한다.
min_delta는 현재 점수가 이전 점수에 비해 min_delta값 이상 낮아지면 학습을 멈추는 역할을 하고, patience는 검증 평가 점수가 이전 최고 점수보다 높아지지 않는 에폭 수가 patience를 넘어가면 학습을 멈추는 역할을 한다.
CheckPoint는 에폭마다 모델을 저장해주는 콜백함수다. sace_best_only 값이 True라면 가장 성능이 좋은 모델만 저장된다. monitor 파라미터에서 평가지표를 정하고 save_weights_only는 모델 저장 시 가중치만 저장하는 옵션이다.
# overfitting을 막기 위한 ealrystop 추가
earlystop_callback = EarlyStopping(monitor='val_accuracy', min_delta=0.0001, patience=1)
# min_delta: the threshold that triggers the termination (acc should at least improve 0.0001)
# patience: no improvment epochs (patience = 1, 1번 이상 상승이 없으면 종료)
checkpoint_path = DATA_OUT_PATH + model_name + '/weights.h5'
checkpoint_dir = os.path.dirname(checkpoint_path)
# Create path if exists
if os.path.exists(checkpoint_dir):
print("{} -- Folder already exists \n".format(checkpoint_dir))
else:
os.makedirs(checkpoint_dir, exist_ok=True)
print("{} -- Folder create complete \n".format(checkpoint_dir))
cp_callback = ModelCheckpoint(
checkpoint_path, monitor='val_accuracy', verbose=1, save_best_only=True, save_weights_only=True)이제 학습을 진행한다. 딥러닝 학습이기 때문에 일반 CPU로 학습 시 시간이 꽤 소요될 가능성이 있다. Colab GPU 사용을 추천한다. Colab에서 GPU를 사용하지 않을 때 1 epoch당 4분 40초가 소요되었으며, GPU를 사용했을 때 30초가 소요되었다.
history = model.fit(train_input, train_label, batch_size=BATCH_SIZE, epochs=NUM_EPOCHS,
validation_split=VALID_SPLIT, callbacks=[earlystop_callback, cp_callback])학습이 완료되었다면 그래프를 통해 성능 변화를 살펴보자.
plot_graphs(history, 'accuracy')
plot_graphs(history, 'loss')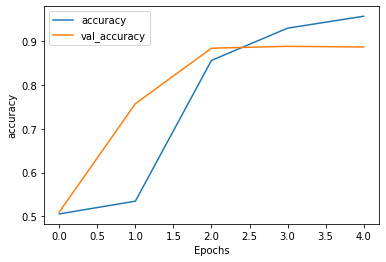

이렇게 결과를 시각적으로 검증할 수 있다. 이제 테스트 데이터를 완성된 모델에 적용해보자.
DATA_OUT_PATH = './data_out/'
TEST_INPUT_DATA = 'test_input.npy'
TEST_ID_DATA = 'test_id.npy'
test_input = np.load(open(DATA_IN_PATH + TEST_INPUT_DATA, 'rb'))
test_input = pad_sequences(test_input, maxlen=test_input.shape[1])
# 최적 모델 불러오기
SAVE_FILE_NM = 'weights.h5'
model.load_weights(os.path.join(DATA_OUT_PATH, model_name, SAVE_FILE_NM))
# 데이터 예측
predictions = model.predict(test_input, batch_size=BATCH_SIZE)
predictions = predictions.squeeze(-1)
# 데이터 저장
test_id = np.load(open(DATA_IN_PATH + TEST_ID_DATA, 'rb'), allow_pickle=True)
if not os.path.exists(DATA_OUT_PATH):
os.makedirs(DATA_OUT_PATH)
output = pd.DataFrame(data={"id": list(test_id), "sentiment":list(predictions)})
output.to_csv(DATA_OUT_PATH + 'movie_review_result_rnn.csv', index=False, quoting=3)캐글에 제출했을 때 지금까지 모델들 중 가장 높은 성능을 내는 것을 확인할 수 있다.

다음 글에서는 CNN으로 작업을 진행하도록 하겠다.
