
CNN
CNN이란?
CNN은 Convolutional Neural Network의 약자로, Dense신경망 앞에 여러 계층의 합성곱(Convolution)을 쌓은 모델이다. 보통 이미지 데이터에 많이 쓰이는데, 입력받은 데이터에 대한 가장 좋은 특징을 만들어 내도록 학습하고, 추출된 특징을 활용해 데이터를 분류하는 방식이다.
이런 방식이 텍스트에서도 좋은 효과를 낼 수 있다는 것을 Yoon Kim 박사가 쓴 "Convolutional Neural Network for Sentence Classification(2014)"를 통해 입증했다.
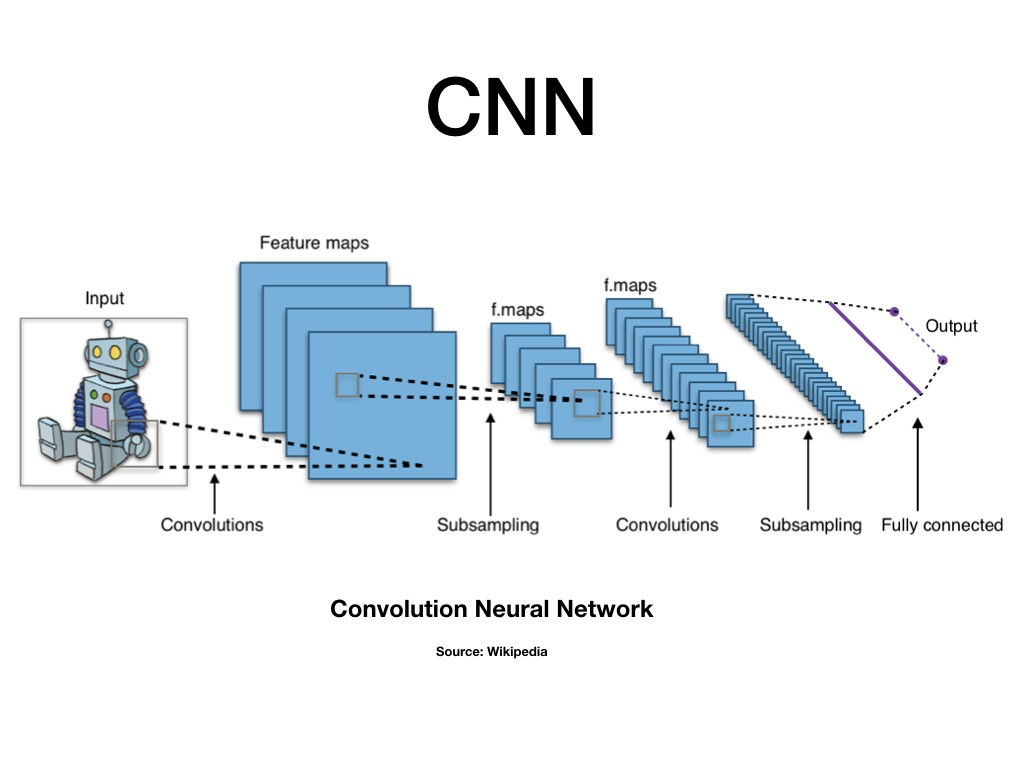
RNN이 단어의 입력 순서를 중요하게 반영한다면 CNN은 문장의 지역 정보를 보존하면서 각 문장 성분의 등장 정보를 학습에 반영하는 구조로 풀어가고 있다. 학습할 때 각 필터 크기를 조절하면서 언어의 특징 값을 추출하게 되는데, 기존의 n-gram방식과 유사하다고 볼 수 있다.
전체적인 구조는 RNN에서 진행한 것과 크게 다르지 않다. 모델 부분만 변경해주면 쉽게 CNN모델을 통한 학습을 진행할 수 있다.
앞의 글을 참조해서 파일을 불러오기까지 끝냈다고 가정한다.
모델의 하이퍼 파라미터를 결정해야한다.
model_name = 'cnn_classifier_en'
BATCH_SIZE = 512
NUM_EPOCHS = 2
VALID_SPLIT = 0.1
MAX_LEN = train_input.shape[1]
kargs = {'model_name': model_name,
'vocab_size': prepro_configs['vocab_size'],
'embedding_size': 128,
'num_filters': 100,
'dropout_rate': 0.5,
'hidden_dimension': 250,
'output_dimension':1}CNN모델을 생성하기위해 클래스를 생성하도록 한다.
형태는 Embedding벡터를 생성한 후, Conv1D를 활용해 kernel_size가 3,4,5인 세 개의 합성곱 레이어를 사용한다. 추가로 각 합성곱 신경망 이후에는 맥스 풀링 레이어를 적용하게 되고, 마지막으로 과적합 방지를 위한 Dropout과 Fully Connected(완전 연결 계층) 2개 층을 쌓아 최종 출력을 만들어낼 수 있다.
class CNNClassifier(tf.keras.Model):
def __init__(self, **kargs):
super(CNNClassifier, self).__init__(name=kargs['model_name'])
self.embedding = layers.Embedding(input_dim=kargs['vocab_size'],
output_dim=kargs['embedding_size'])
self.conv_list = [layers.Conv1D(filters=kargs['num_filters'],
kernel_size=kernel_size,
padding='valid',
activation=tf.keras.activations.relu,
kernel_constraint=tf.keras.constraints.MaxNorm(max_value=3.))
for kernel_size in [3,4,5]]
self.pooling = layers.GlobalMaxPooling1D()
self.dropout = layers.Dropout(kargs['dropout_rate'])
self.fc1 = layers.Dense(units=kargs['hidden_dimension'],
activation=tf.keras.activations.relu,
kernel_constraint=tf.keras.constraints.MaxNorm(max_value=3.))
self.fc2 = layers.Dense(units=kargs['output_dimension'],
activation=tf.keras.activations.sigmoid,
kernel_constraint=tf.keras.constraints.MaxNorm(max_value=3.))
def call(self, x):
x = self.embedding(x)
x = self.dropout(x)
x = tf.concat([self.pooling(conv(x)) for conv in self.conv_list], axis=-1)
x = self.fc1(x)
x = self.fc2(x)
return x여기까지 진행하면 뒷부분 역시 앞의 글에서와 마찬가지로 모델 컴파일 및 Callback선언, 학습을 진행하면 된다. 학습이 완료되면 시각화를 진행하며 결과를 확인하고, 캐글에 제출해보자.
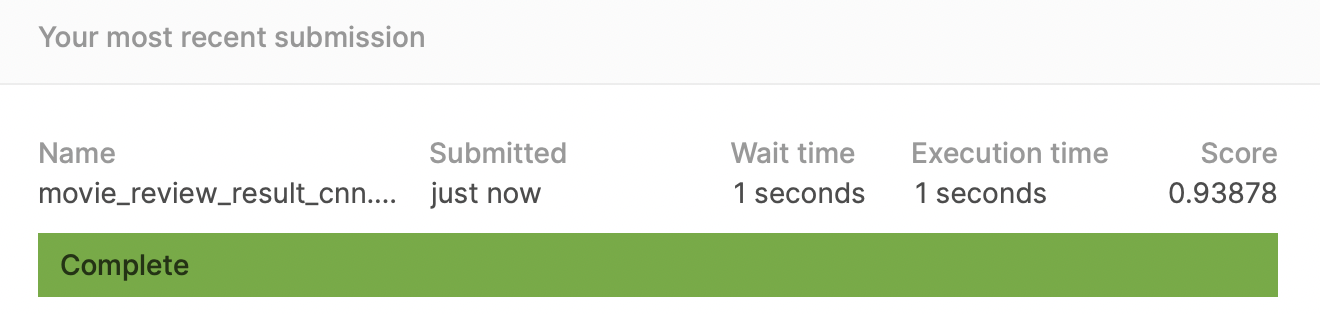
RNN보다 약간 낮은 score지만 높은 성능을 보이고 있음을 확인할 수 있다.
여기까지 머신러닝/딥러닝 모델을 활용한 텍스트 분류 실습을 진행해보았다. 여기서 진행한 실습은 간단하게 구현한 형태이기 때문에 여러가지 시도를 통해 성능을 보완할 수 있도록 노력해보자.
