Reading CSV Data in Python
CSV(comma seperated values): tabular data, that fits into tables like spreadsheets
import pandas
data = pandas.read_csv("weather_data.csv")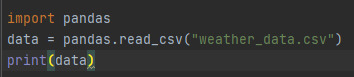
Primary Datatype in Pandas
1. Dataframe: a whole table
2. Series: every single column like a list
data["score"] : returns series(column) of items under the name 'score' lable in 'data' file
Method in pandas
- to_dict() / to_list()
#convert the the whole dataframe(table) or series(column) into a dict/ list format
data_dict = data.to_dict()
print(data_dict)
temp_list = data["temp"].to_list()
print(temp_list)- method: .mean()/ .max() / .min() etc.
print(data["temp"].mean())
print(data["temp"].max())
e.g. filter the column with a condition
find the max value of temperature: returns maximum number in a 'temp' column. Which row, inside 'temp' column eqauls to maximum value
print(data[data.temp == data["temp"].max()])
Get Data in Columns
- word works as an index in a key, attribute format
- dictionary's key
-name of the column: fitst row of the data. e.g. condition label in data file
print(data["condition"]) - object's attribute
-python converted them into an attritubte.
print(data.condition) Get Data in Row
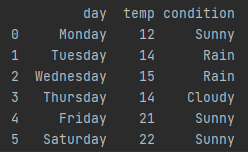
e.g. if I want to get hold of the entire row data. when the day matches monday
print(data[data.day == "monday"]) first data is to fetch a table
second [data.day ~] is to fetch a column
== is to find the value eaqual to "monday" in that column
RESULT-> pulls out the correct row where the day equals to monday. It gives me all the rest of the data for that row
- getting the value of under other lable in a row
monday = data.[data.day == "monday"]
print(monday.condition)
#printed : Sunnyprint(data[data["Primary Fur Color"] == "Gray"])
Create & Save Dataframe from scratch
data_dict = {
"names": ["Amy", "Jack", "Hannah"]
"scores": ["76", "88", "57"]
}
#create the table
data = pandas.DataFrame(data_dict)
print(data)
#save in as csv file
data.to_csv("path")Converting List & Dictionary to Dataframe and save as .csv file
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
#--------------------------------------------------------------
#(from flash card example)
df = pandas.DataFrame(word_dictionary)
df.to_csv('words_to_learn.csv')
Project 1: Squirrel Census Data Analysis
My code
import pandas as pd
data = pd.read_csv("2018_Central_Park_Squirrel_Census_-_Squirrel_Data.csv")
fur_list = data["Primary Fur Color"].to_list()
g = fur_list.count("Gray")
b = fur_list.count("Black")
c = fur_list.count("Cinnamon")
sq = pd.DataFrame([['Black', b], ['Gray', g], ['Cinnamon', c]], columns=["Fur Color", "Count"])
sq.to_csv('Squirrel_Count.csv')Angela's
import pandas as pd
#counting each
gray_count = len(data[data["Primary Fur Color"] == "Gray"])
black_count = len(data[data["Primary Fur Color"] == "Black"])
cinnamon_count = len(data[data["Primary Fur Color"] == "Cinnamon"])
#data orginising in a dict form to make a table
data_dict = {
"Fur Colour": ["Gray", "Cinnamon", "Black"],
"Count": [gray_count, black_count, cinnamon_count]
}
#saving the dict in csv file
df = pd.DataFrame(data_dict)
df.to_csv("sq_count_angela.csv")
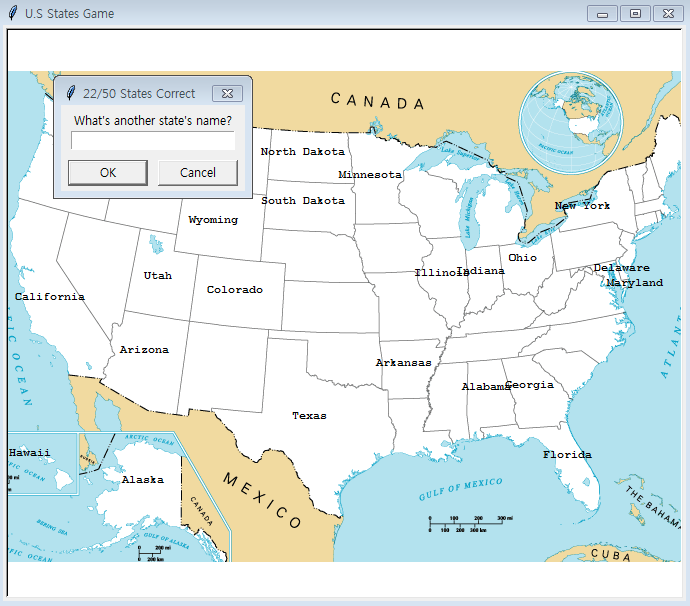
Project 2 : U.S States Game
- my approach was to create a dictionary to access each items; state, x and y
- angela fetched all the values that are matching with state name.
state_data = data[data.state == answer_state]
int(state_data.x)
int(state_data.y)My Code
from turtle import Turtle, Screen
import turtle
import pandas
FONT = ("Courier", 8, "bold")
screen = turtle.Screen()
screen.title("U.S States Game")
img = "blank_states_img.gif"
screen.addshape(img)
turtle.shape(img)
# TODO 1: convert the guess to Title case
# answer_state = screen.textinput(title="Guess the state", prompt= "What's another state's name?")
# titled_answer = answer_state.title()
# print(titled_answer)
# TODO 2: check if answer is among the 50 states
# TODO 3: write correct guess onto the map
name_data = "50_states.csv"
# get only the columns you want from the csv file
df = pandas.read_csv("50_states.csv", usecols=['state', 'x', 'y'])
dict_state = df.to_dict(orient='records')
# print(dict_state)
correct_answer = []
score = 0
while len(correct_answer) < 50:
if score == 0:
answer_state = screen.textinput(title="Guess the state", prompt="What's another state's name?")
elif score > 0:
answer_state = screen.textinput(title=f"{score}/50 States Correct", prompt="What's another state's name?")
if score >= 0 and answer_state == 'exit':
break
titled_answer = answer_state.title()
for state in dict_state:
if state['state'] == titled_answer:
state_coordinate = Turtle()
state_coordinate.hideturtle()
state_coordinate.penup()
state_coordinate.goto(x=state['x'], y=state['y'])
state_coordinate.write(f"{state['state']}", align="center", font=FONT)
correct_answer.append(state['state'])
score = len(correct_answer)
learn = []
for item in dict_state:
if item['state'] not in correct_answer:
learn.append(item['state'])
#List Comprehension ver
#learn = [item['state'] for item in dict_state if item['state'] not in correct_answer]
data_dict = {
"state": learn
}
df = pandas.DataFrame(data_dict)
df.to_csv("states_to_learn.csv")
# TODO 4: use a loop to allow the user to keep guessing
# TODO 5: record the correct guesses in a list
# TODO 6: keep track of the score
# TODO 7: save missing states into csv
turtle.mainloop() # keep screen open click
#
# my approach was to make a dictionary to access each items; state, x and y
# angela fetched all the values that are matching with state name.
#
# # state_data = data[data.state == answer_state]
# # int(state_data.x) int(state_data.y)Angela's solution
import turtle
import pandas
screen = turtle.Screen()
screen.title("U.S. States Game")
image = "blank_states_img.gif"
screen.addshape(image)
turtle.shape(image)
data = pandas.read_csv("../Solution+-+us-states-game-end/us-states-game-end/50_states.csv")
all_states = data.state.to_list()
guessed_states = []
while len(guessed_states) < 50:
answer_state = screen.textinput(title=f"{len(guessed_states)}/50 States Correct",
prompt="What's another state's name?").title()
if answer_state == "Exit":
missing_states = []
for state in all_states:
if state not in guessed_states:
missing_states.append(state)
new_data = pandas.DataFrame(missing_states)
new_data.to_csv("states_to_learn.csv")
break
if answer_state in all_states:
guessed_states.append(answer_state)
t = turtle.Turtle()
t.hideturtle()
t.penup()
state_data = data[data.state == answer_state]
t.goto(int(state_data.x), int(state_data.y))
t.write(answer_state)

You can use (zip) to convert list to dataframe in python:
import pandas as pd
import pandas as pd
list of strings
lst1 = ['apple', 'grape', 'orange', 'mango']
list of int
lst2 = [11, 22, 33, 44]
Calling DataFrame after zipping both lists, with columns specified
df = pd.DataFrame(list(zip(lst1, lst2)),
df
Source : List to dataframe python