
🌹 목적
얼마전 친구와 같이 편의점에 들려 술을 사는데, 알바생이 내 얼굴을 보고 신분증 검사를 했다...
나는 편의점에서 나와 나이 30에 신분증 검사를 당한 것이 기뻐 친구에게 말했다.
"내가 동안이라 신분증 검사한듯?"
그러자 친구는 말했다.
"뭔소리야 나 때문에 검사한거지."
CNN 을 활용한 이미지 분류 토이프로젝트 기회가 찾아왔을 때, 나는 문득 이 날이 떠올랐다.
'그래 나이 예측모델을 만들어서, 나와 친구중에 누구의 말이 더 일리가 있는지 확인해보자!'
그리하여 이 프로젝트가 시작되었다...
🌹 데이터 분석
탐색적 데이터 분석 EDA 과정을 진행해보았다.
github 🔗EDA 주피터 파일 확인하기
다양한 나이 분포를 가진 얼굴 이미지를 Kaggle 사이트에서 쉽게 구할 수 있었다.
📌 출처
https://www.kaggle.com/datasets/jangedoo/utkface-new
https://susanqq.github.io/UTKFace/


데이터는 나이별로 폴더 구분이 없었고, 아래와 같이 파일명에 정보가 담겨있었다.
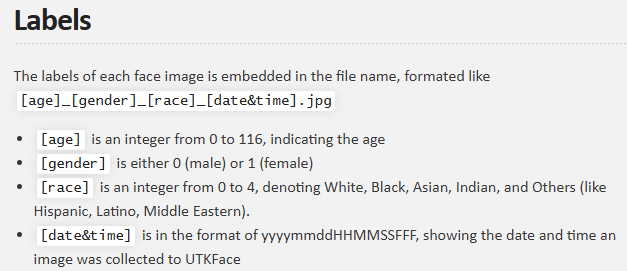
Google Colab 에서 Kaggle API로 데이터를 로드한 후, 파일명 규칙대로 정보를 파싱했다.
파싱한 데이터에서 랜덤하게 16개의 얼굴이미지를 뽑아 데이터가 신뢰할 수 있는지 파악해보았다.

!!!!!! 두번째 사진에 원빈이 있어서 깜짝놀랐다...
얼굴이미지에 나이, 성별, 인종을 확인하였더니 어느정도 납득이 간다.
1. 성별, 인종 분포
이제 성별, 인종 분포를 확인해보자.
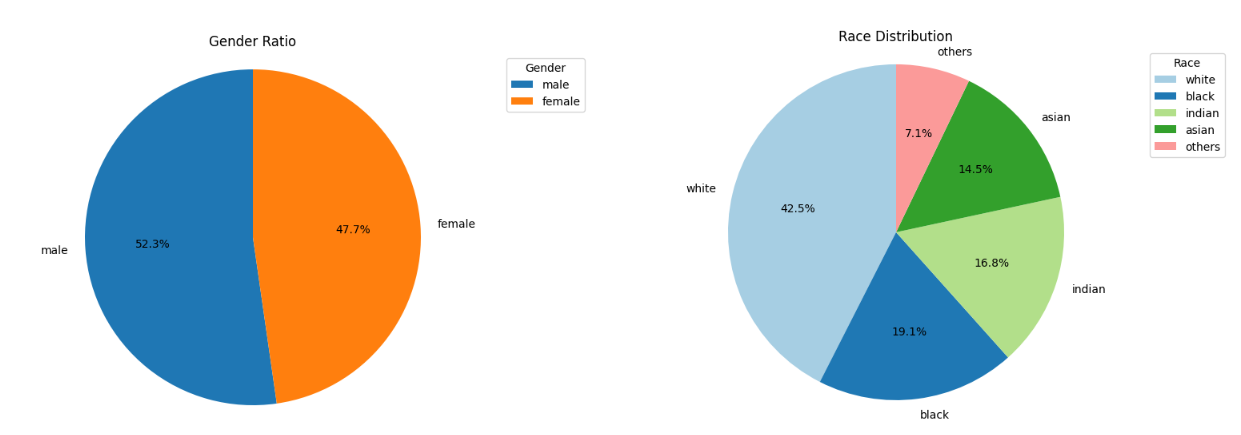
성비는 어느정도 비등하지만, 인종은 고르게 분포되지 않았다.
전체 데이터 양도 적었기 때문에 과감히 인종 정보는 버리기로...
(사실 인종에 따라 노화속도가 달라서 동양인 얼굴 이미지만 모은 데이터셋을 구하고 싶었지만 찾기가 힘들었다... 바이두에서 다운받는게 있었는데 중국사이트는 좀 불안해서;;)
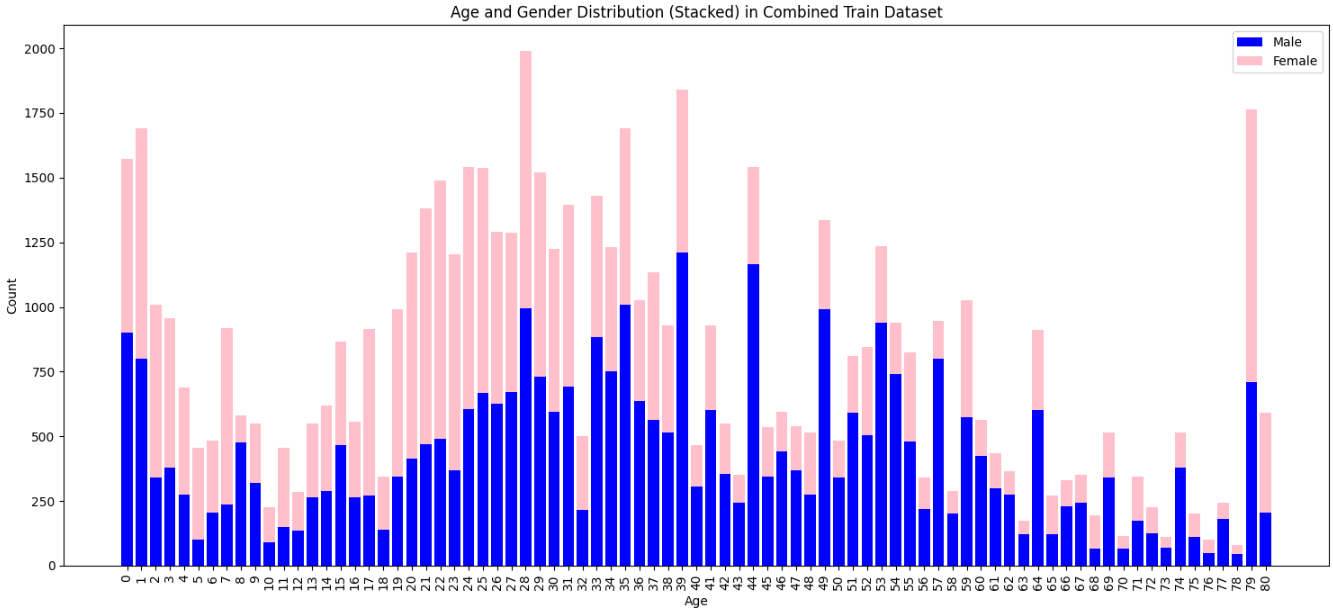
2. 나이별 남녀 수
다음으로는 나이별 남녀 수를 확인해보았다.

데이터가 너무 적다. 연령별로 그룹화하여 클래스 데이터의 양을 늘리는 것이 올바른 방향인 것 같다.
하지만, 단순히 20대로 보일지 30대로 보일지 예측하는 모델은 나라면 사용할 거 같지 않다 (전혀 흥미롭지 않다).
3. 프로젝트 진행 방향
그리하여 내가 정한 방향은 다음과 같다.
📌 분석 및 모델링 과정에서의 인종 배제
인종 데이터가 고르게 분포되지 않았기 때문에, 인종은 분석 및 모델링 과정에서 고려하지 않는다.
📌 나이 및 성별 예측
초기 계획에 따라 나이는 그룹화하지 않고, 나이와 성별을 함께 예측한다.
📌 고령 연령대의 그룹화 예외
80대 및 90세 이상의 데이터가 제한적이므로, 해당 연령대는 각각 "80대"와 "90+"로 그룹화한다.
🌹 나이 성별 예측
이제 본격적으로 코드를 짜보자.
github 🔗prediction 주피터 파일 확인하기
1. Train | Valid | Test 분리
먼저 파일명을 파싱하여 나이, 성별, 이미지명을 가진 pandas dataframe(이하 df)를 만들었다.
나이는 1~79세 / 80대 / 90대이상, 총 81개의 클래스가 있다.
손실함수 CrossEntropyLoss를 통해 총 손실을 구할 때, 입력할 정수형 레이블이 0부터 시작하여야 하므로
나이는 아래 코드의 주석대로 값을 넣었다.
folder_name = 'UTKFace'
file_mapping = {
"UTKFace/61_1_20170109142408075.jpg.chip.jpg": "UTKFace/61_1_1_20170109142408075.jpg.chip.jpg",
"UTKFace/39_1_20170116174525125.jpg.chip.jpg": "UTKFace/39_0_1_20170116174525125.jpg.chip.jpg",
"UTKFace/61_1_20170109150557335.jpg.chip.jpg": "UTKFace/61_1_3_20170109150557335.jpg.chip.jpg"
}
def parse_dataset(dataset_path, ext='jpg'):
def parse_info_from_file(path):
try:
filename = os.path.split(path)[1]
filename = os.path.splitext(filename)[0]
age, gender, _, _ = filename.split('_')
'''
손실 함수 nn.CrossEntropyLoss()
-> 모델 출력(logits)과 정수형 레이블 입력
정수형 레이블은 0부터 시작하는 정수값
-> age 레이블을 다음과 같이 변경
1 -> 0
2 -> 1
3 -> 2
.
.
.
79 -> 78
80 ~ 89 -> 79
90 ~ 116 -> 80
'''
if int(age) // 10 == 8:
age = 79
elif int(age) // 10 >= 9:
age = 80
else:
age = int(age) - 1
return age, int(gender)
except Exception as ex:
return None, None
files = glob(os.path.join(dataset_path, "*.%s" % ext))
records = []
for file in files:
if file in file_mapping:
file = file_mapping[file]
info = parse_info_from_file(file)
if info[0] is not None:
records.append(info)
else:
print(file)
df = pd.DataFrame(records)
df['file'] = files[:len(records)]
df.columns = ['age', 'gender', 'file']
df = df.dropna()
return df
df = parse_dataset(folder_name)
print(df.head())age gender file 0 50 0 UTKFace/51_0_3_20170104220403390.jpg.chip.jpg 1 54 1 UTKFace/55_1_3_20170119200044963.jpg.chip.jpg 2 49 0 UTKFace/50_0_0_20170104021859988.jpg.chip.jpg 3 52 1 UTKFace/53_1_0_20170103183702714.jpg.chip.jpg 4 0 0 UTKFace/1_0_3_20161219225252688.jpg.chip.jpg
UTKFace 데이터는 train, valid, test 데이터셋 구분이 없어 분리가 필요했다. 나는 임의로 train, valid, test 데이터셋을 7:2:1 로 나눴다.
# stratify는 **데이터를 분할(split)**할 때, 특정 컬럼이나 배열의 클래스 분포를 유지하도록 도와주는 역할을 합니다.
stratify_array = np.array(list(zip(df['age'], df['gender'])))
# df -> 70% train_df, 30% temp_df
train_df, temp_df = train_test_split(
df,
test_size=0.3, # 30% temp_df
random_state=0,
shuffle=True,
stratify=stratify_array,
)
temp_stratify_array = np.array(list(zip(temp_df['age'], temp_df['gender'])))
# temp_df -> valid_df, test_df (2:1)
valid_df, test_df = train_test_split(
temp_df,
test_size=1/3, # 1/3 test_df
random_state=0,
shuffle=True,
stratify=temp_stratify_array,
)
# print result
print(f"Train set size: {len(train_df)}")
print(f"Validation set size: {len(valid_df)}")
print(f"Test set size: {len(test_df)}")Train set size: 16595 Validation set size: 4742 Test set size: 2371
2. DataSet, DataLoader 생성
훈련 및 검증 전 PyTorch DataSet, DataLoader를 생성한다.
# 사용자 정의 데이터셋 클래스 생성 (CustomDataset)
class CustomDataset(Dataset):
def __init__(self, dataframe, transform=None):
# 데이터셋 초기화
# dataframe: 이미지 경로와 age, gender가 포함된 데이터프레임
# transform: 이미지에 적용할 전처리(transform) 함수
self.dataframe = dataframe
self.transform = transform
def __len__(self):
# 데이터셋의 총 샘플 수 반환
return len(self.dataframe)
def __getitem__(self, idx):
# 주어진 인덱스(idx)에 해당하는 샘플을 반환
# 이미지 경로를 데이터프레임에서 가져옴
img_name = self.dataframe.iloc[idx, 2]
# 이미지 파일을 열고 RGB 모드로 변환
img = Image.open(img_name).convert('RGB')
# age와 gender 정보를 정수형으로 가져옴
age = int(self.dataframe.iloc[idx, 0])
gender = int(self.dataframe.iloc[idx, 1])
# transform이 지정되어 있다면 이미지에 전처리를 적용
if self.transform:
img = self.transform(img)
# 이미지와 age, gender를 반환
return img, age, gender
# 이미지 전처리를 위한 변환 작업 정의
transform = transforms.Compose([
transforms.ToTensor(), # 이미지를 Tensor로 변환
transforms.Lambda(lambda x: x / 255.0) # 255로 나누어 [0, 1] 범위로 변환
])
# 데이터셋 로딩
train_dataset = CustomDataset(dataframe=train_df, transform=transform)
valid_dataset = CustomDataset(dataframe=valid_df, transform=transform)
test_dataset = CustomDataset(dataframe=test_df, transform=transform)
batch_size = 128
# 데이터 로더 설정
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=2)
valid_loader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=False, num_workers=2)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=2)3. 모델
사전학습된 모델을 받아 전이학습 모델을 만들어보자.
# 모델 클래스 정의
class AgeGenderModel(nn.Module):
def __init__(self, base_model, num_age_classes):
super(AgeGenderModel, self).__init__()
# 사전 학습된 모델 로드
self.base_model = base_model
# 기존 fc의 출력을 기반으로 새로운 fc 계층을 추가
num_features = self.base_model.fc.out_features # 기존 fc 계층의 출력 차원
# 기존 fc 계층은 그대로 두고, 새로운 fc 계층을 이어붙임
self.fc = nn.Sequential(
nn.Linear(num_features, 128), # 기존 fc의 출력에 연결될 새로운 fc
nn.ReLU(),
nn.Dropout(0.5)
)
# 성별 출력 계층
self.gender_logits = nn.Linear(128, 2) # 성별 분류 (2개 클래스)
# 나이 출력 계층
self.age_logits = nn.Linear(128, num_age_classes) # 나이 분류 (num_age_classes 개 클래스)
def forward(self, x):
# 기본 모델을 통해 특징 추출
features = self.base_model(x)
# 기존 fc 계층의 출력을 새로운 fc 계층에 통과시킴
features = self.fc(features)
# 성별과 나이 예측
gender_logits = self.gender_logits(features)
age_logits = self.age_logits(features)
return gender_logits, age_logits
# 사전 학습된 ResNet18 모델 불러오기
base_model = models.resnet18(pretrained=True) # ImageNet 데이터로 학습된 ResNet18 모델 로드
for param in base_model.parameters():
param.requires_grad = True
# AgeGenderModel 정의
model = AgeGenderModel(base_model, number_of_age_classes) # 사용자 정의 AgeGenderModel 생성
# 디바이스 설정
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # CUDA 사용 가능 여부에 따라 디바이스 설정 (GPU 또는 CPU)
# 모델을 설정된 디바이스로 이동
model = model.to(device) # 모델을 GPU 또는 CPU로 이동4. 손실 함수
총 손실 = α x 성별에 대한 손실 + β x 나이에 대한 손실
# 교차 엔트로피 손실 함수 초기화
criterion_gender = nn.CrossEntropyLoss() # 성별 출력에 대한 손실
criterion_age = nn.CrossEntropyLoss() # 나이 출력에 대한 손실
# 총 손실 계산 함수
def calculate_total_loss(gender_preds, age_preds, gender_labels, age_labels, alpha=1.0, beta=1.0):
loss_gender = criterion_gender(gender_preds, gender_labels)
loss_age = criterion_age(age_preds, age_labels)
total_loss = alpha * loss_gender + beta * loss_age
return total_loss
5. 옵티마이저
# 최적화 알고리즘으로 Adam 사용
# filter(lambda p: p.requires_grad, model.parameters())는 requires_grad=True로 설정된 파라미터만 옵티마이저에 전달
# - 사전 학습된 모델의 고정된 파라미터(requires_grad=False)를 제외하여 불필요한 계산 낭비 방지
# - lr: 학습률(learning rate), weight_decay: L2 정규화 항
optimizer = torch.optim.Adam(
filter(lambda p: p.requires_grad, model.parameters()), # 학습 가능한 파라미터만 전달
lr=1e-5, # 학습률 설정
weight_decay=1e-5 # 가중치 감소(L2 정규화)로 과적합 방지
)
# StepLR 스케줄러 정의 (매 10 에폭마다 학습률을 0.1배씩 감소)
scheduler = StepLR(optimizer, step_size=10, gamma=0.1)6. 학습
나이 클래스가 81개이므로 정확도가 매우 낮을 것으로 예상했다.
👉 나이가 top 3 안에 포함되면 정답으로 인정하고, 정확도를 구했다.
# 학습 파라미터 설정
num_epochs = 50
best_val_acc = 0.0
patience = 5
no_improve = 0
# 훈련 및 검증 손실을 추적하기 위한 리스트
train_losses = []
valid_losses = []
# 훈련 및 검증 나이 Top-3 정확도 추적하기 위한 리스트
train_accs = []
valid_accs = []
for epoch in range(num_epochs):
model.train()
train_running_loss = 0.0
train_correct_gender = 0
train_correct_age_top3 = 0
train_total = 0
for inputs, ages, genders in tqdm(train_loader, desc=f"Epoch {epoch+1}/{num_epochs}", dynamic_ncols=True):
inputs, ages, genders = inputs.to(device), ages.to(device), genders.to(device)
optimizer.zero_grad()
# 모델의 출력
gender_logits, age_logits = model(inputs)
# 손실 계산
total_loss = calculate_total_loss(gender_logits, age_logits, genders, ages)
# 역전파
total_loss.backward()
optimizer.step()
train_running_loss += total_loss.item()
# 성별 정확도 계산
_, predicted_gender = torch.max(gender_logits, 1)
train_correct_gender += (predicted_gender == genders).sum().item()
# 나이 예측에 대한 Top-3 정확도 계산
_, predicted_age_top3 = torch.topk(age_logits, k=3, dim=1)
train_correct_age_top3 += (predicted_age_top3 == ages.unsqueeze(1)).sum().item() # predicted_age_top3는 [batch_size, 3] 형태이고, ages는 [batch_size]이므로 unsqueeze(1)
train_total += ages.size(0)
# 평균 손실 및 정확도 계산
train_avg_loss = train_running_loss / len(train_loader)
train_acc_gender = train_correct_gender / train_total
train_acc_age_top3 = train_correct_age_top3 / train_total
# 검증 단계
model.eval()
val_running_loss = 0.0
val_correct_gender = 0
val_correct_age_top3 = 0
val_total = 0
with torch.no_grad():
for inputs, ages, genders in valid_loader:
inputs, ages, genders = inputs.to(device), ages.to(device), genders.to(device)
# 모델의 출력
gender_logits, age_logits = model(inputs)
# 총 손실 계산
total_loss = calculate_total_loss(gender_logits, age_logits, genders, ages)
val_running_loss += total_loss.item()
# 성별 정확도 계산
_, predicted_gender = torch.max(gender_logits, 1)
val_correct_gender += (predicted_gender == genders).sum().item()
# 나이 예측에 대한 Top-3 정확도 계산
_, predicted_age_top3 = torch.topk(age_logits, k=3, dim=1)
val_correct_age_top3 += (predicted_age_top3 == ages.unsqueeze(1)).sum().item()
val_total += ages.size(0)
# 평균 검증 손실 및 정확도 계산
val_avg_loss = val_running_loss / len(valid_loader)
val_acc_gender = val_correct_gender / val_total
val_acc_age_top3 = val_correct_age_top3 / val_total
# 손실 기록
train_losses.append(train_avg_loss)
valid_losses.append(val_avg_loss)
# 나이 Top-3 정확도 기록
train_accs.append(train_acc_age_top3)
valid_accs.append(val_acc_age_top3)
# 학습 및 검증 결과 출력
print(f"Epoch [{epoch+1}/{num_epochs}]:")
print(f" Train Loss: {train_avg_loss:.4f}, Train Gender Acc: {train_acc_gender:.4f}, Train Age Top-3 Acc: {train_acc_age_top3:.4f}")
print(f" Val Loss: {val_avg_loss:.4f}, Val Gender Acc: {val_acc_gender:.4f}, Val Age Top-3 Acc: {val_acc_age_top3:.4f}")
# 조기 종료를 위한 정확도 비교 (Age Top-3 기준)
if val_acc_age_top3 > best_val_acc:
best_val_acc = val_acc_age_top3
no_improve = 0
# 모델 저장
torch.save(model.state_dict(), f"best_model.pth")
print(f"Model saved at epoch {epoch+1}")
else:
no_improve += 1
if no_improve >= patience:
print("Early stopping triggered.")
break
# 스케줄러 step 호출 (매 에폭 끝에서 호출)
scheduler.step()
7. Loss, Accuracy 시각화
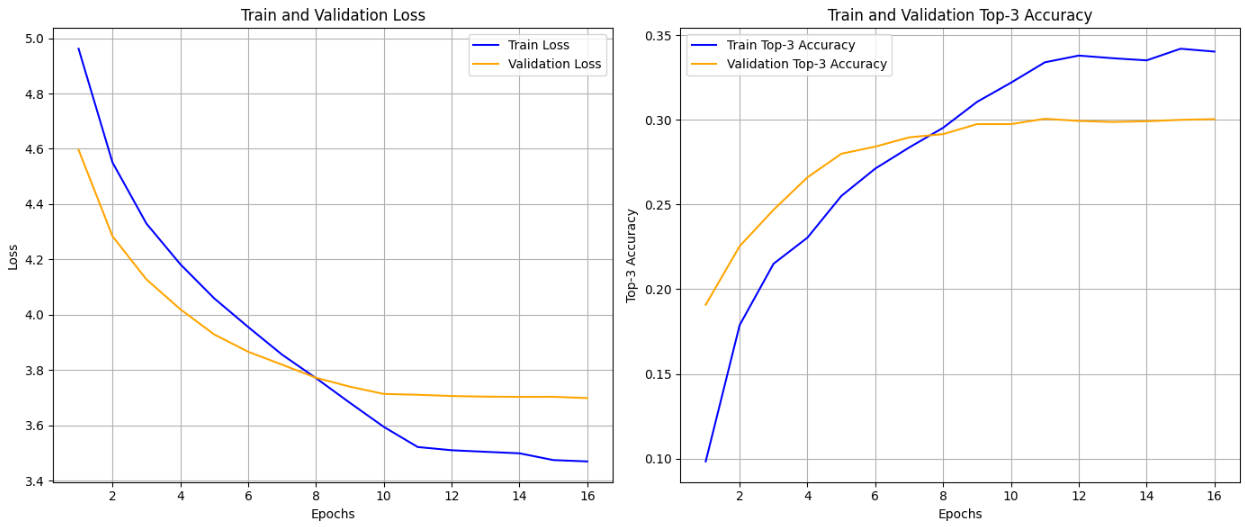
epoch이 증가함에 따른 train, valid 데이터셋의 손실, 정확도 그래프가 아래와 같이 나왔다.
정확도가 너무 낮고, 과적합이 되버렸다;;
아무래도 데이터 증강이 필요하다!
------ 데이터 증강 ------
1. 오버 샘플링
우선 데이터 양이 너무너무 적다...
나이 라벨이 25인 데이터가 상대적으로 매우 크지만 언더 샘플링을 하지않기로 하고,

데이터 크기를 보고 대략적으로 나이별 남녀 합의 값을 구간별로 나눴다.
0-400: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 28, 30, 32, 33, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80 401-600: 24, 26, 29, 31 601-1300: 0, 23, 27, 34 1301+: 25
그리고 데이터 증강을 통해 위에서부터 순서대로 5배, 3배, 2배, 1배 데이터셋 양을 늘렸다...
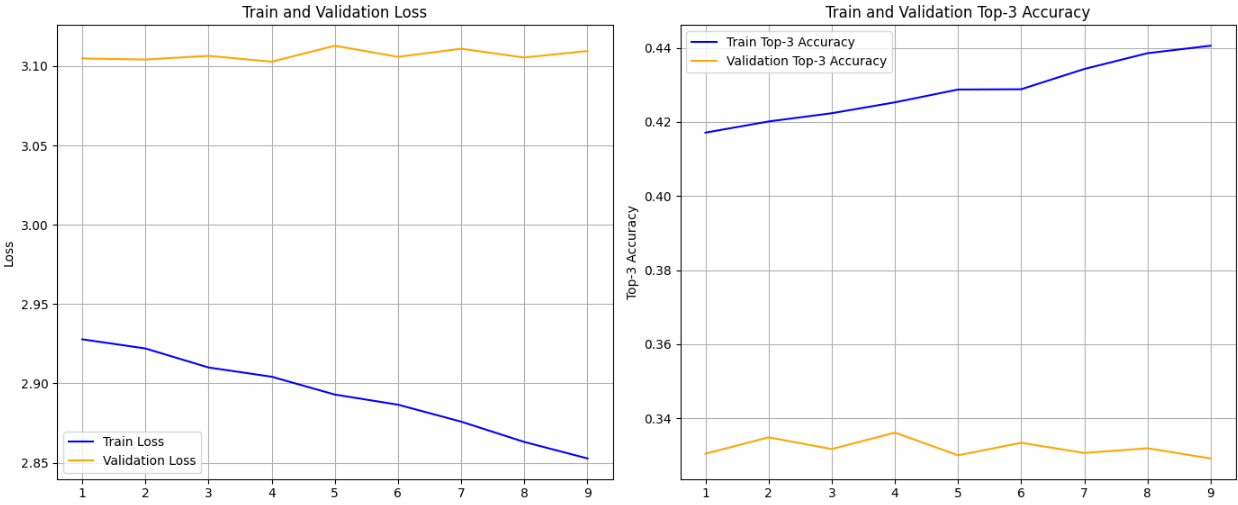
그리고 다시 학습을 진행한 결과 . . . . . . . . . . .
2. Loss, Accuracy 시각화
정확도가 조금 올랐지만 처참하다!
🌹 결론
정확도가 너무 낮게 나왔다...
사실 여러 삽질을 하면서 수많은 학습을 돌렸는데
67% 정확도를 보이던 모델이... 이것저것 만지다보니 어느새 33% 로 정확도가 반이나 줄었다...
슬프다... 아 그리고 얼마전 신분증 검사도 그냥 알바 원칙이었던 것 같다...
끝으로 느낀점과 TODO를 보자.
1. 느낀점
- 학습에 관련된 모든 요소를 기록하자 (하이퍼파라미터 설정, 모델 구조, 데이터 증강 여부, 정확도 등)
- 데이터 품질과 규모의 중요성
- 예측에서 인종 정보를 사용하지 못해 아쉽다.
- 노화정도는 사람마다 천차만별... 데이터가 부족했던 것 같다.
2. TODO
- output을 하나 (나이 따로, 성별 따로)로 하여 다시 학습시켜보기
- 성별에 따른 나이 예측은 다르므로, 종속성을 명시적 부여하는 새로운 모델을 만들어서 해보기
- 분류 모델이 아닌 회귀모델로 해보기
