오늘 한일✅
- React Query를 이용하여 데이터 중복 요청과 깜빡임 최적화를 진행했다
🚩 React Query를 사용한 이유
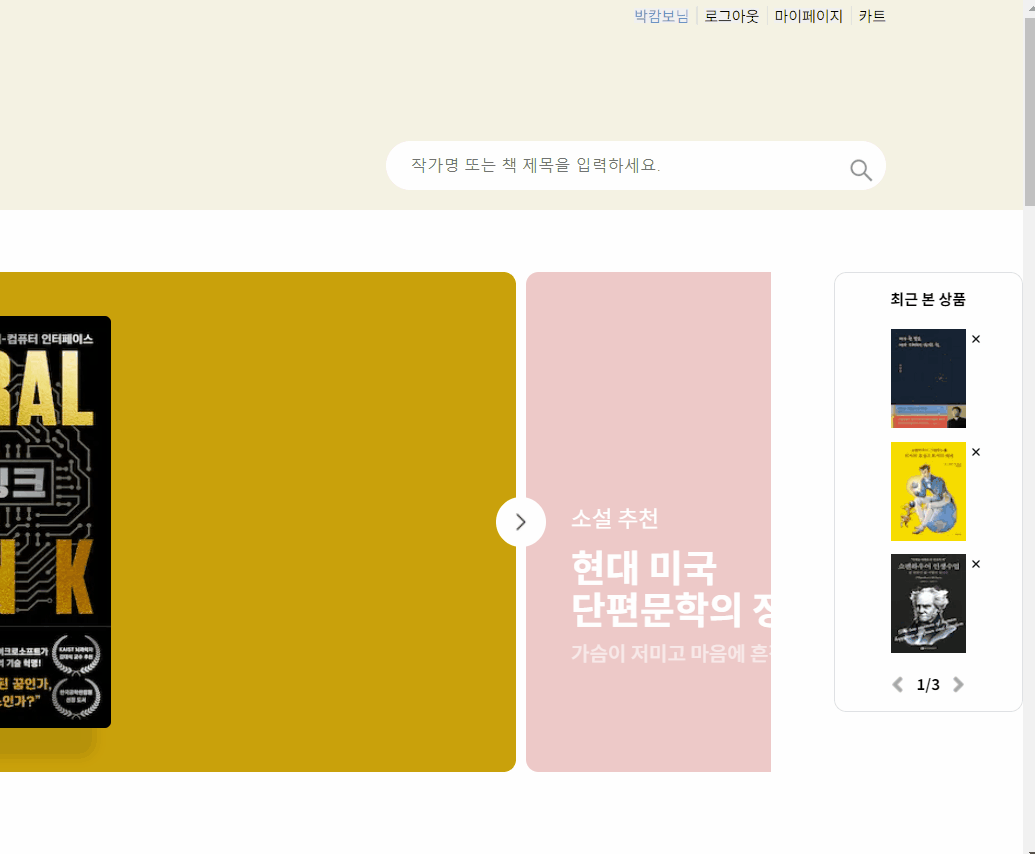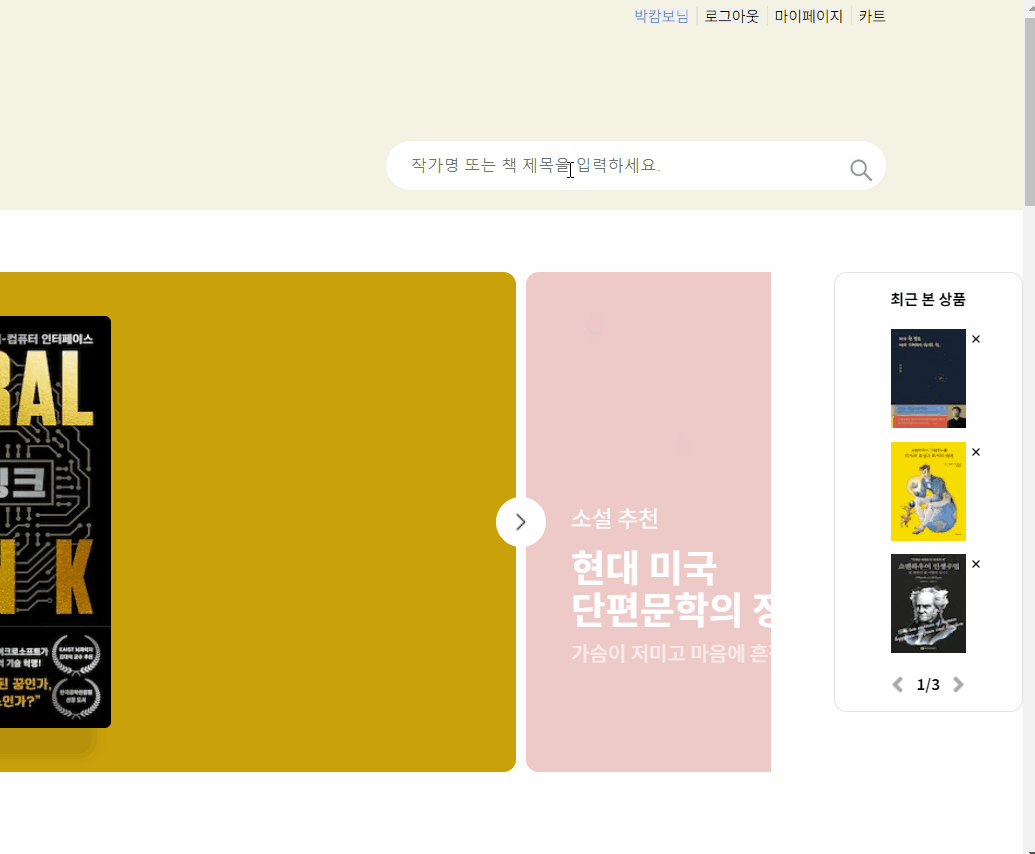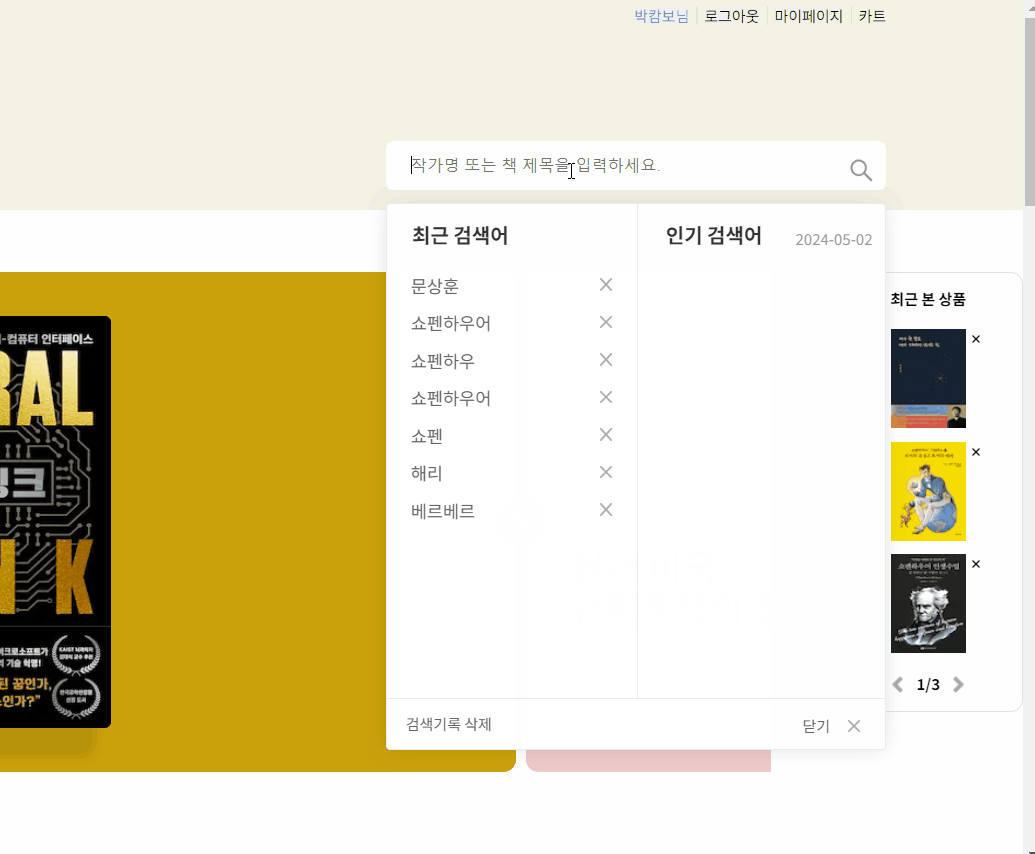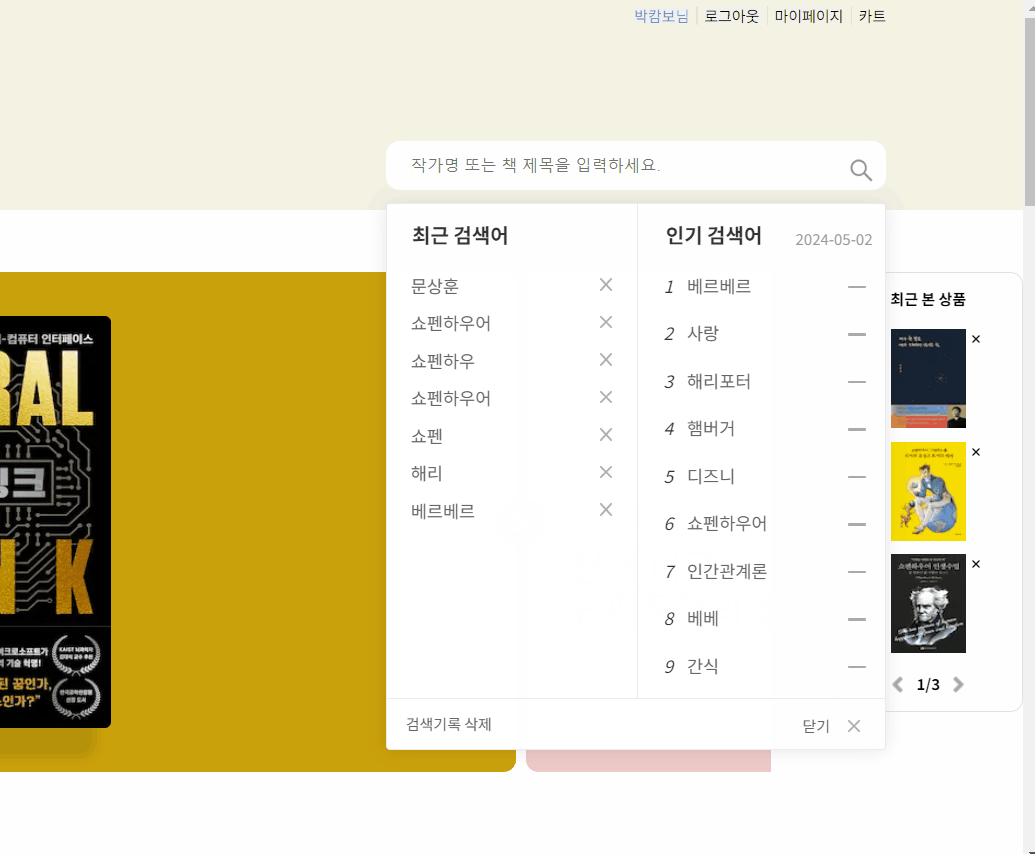
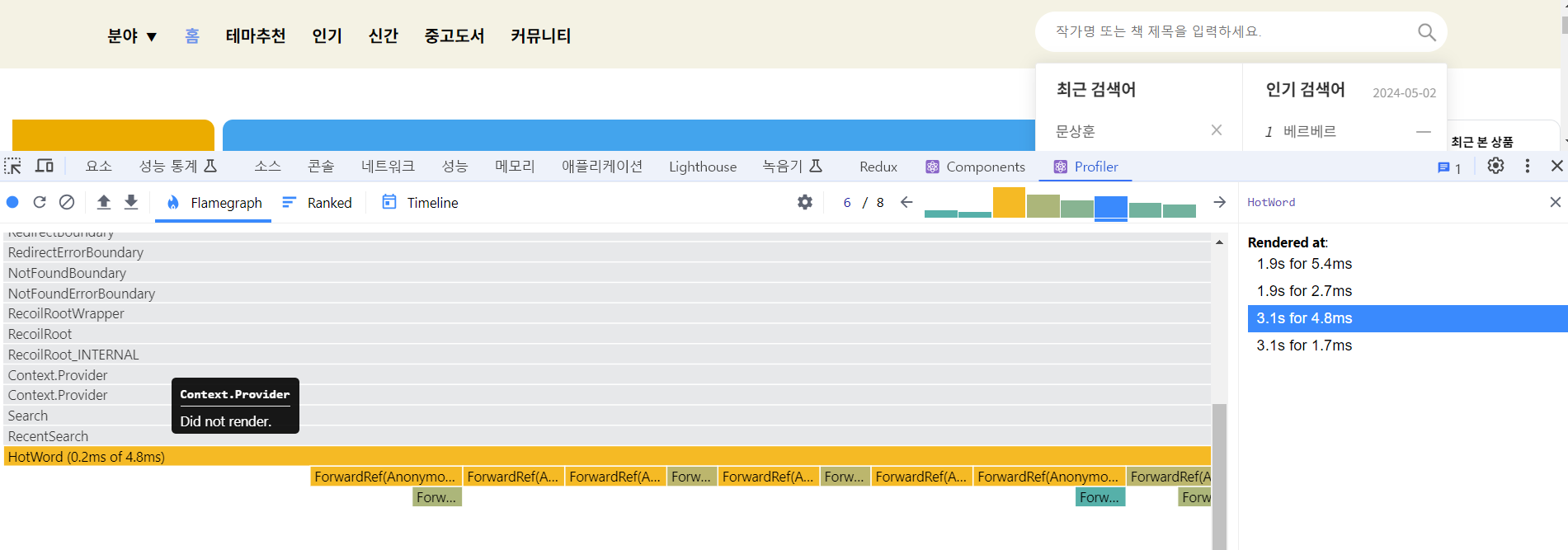
- 검색어를 클릭했을때 인기 검색어가 늦게 뜨는 현상이 생겼다
- 그 이유는 검색어를 클릭할때마다 매번 데이터를 불러오기 때문이다
{kind=link}
이 현상에 대해 팀원들과 회의를 진행했습니다. 회의 중 한 팀원이 제안한 해결책은
React Query나swe를 도입해 중복되는 데이터 요청을 줄이는 것입니다. 또한, 사용자가 에러라고 느끼지 않도록스켈레톤 UI를 구현하기로 결정했습니다. 이 방법을 통해 사용자 경험을 개선하고자 진행하였다.
🚩 Nex.js가 제공해주는 확장된 fetch 함수로 왜 충분하지 않을까?🤷♀️
react-query는 캐싱, 리패칭, 동기화하는데 도움을 주는 라이브러리이다. 하지만 Next.js에서 굳이 사용할 필요가 있을까? 라는 생각이 들었다.
- Next.js 측에서 권장하는 방법
- server component를 이용하여 서버측에서 데이터 fetching
- data fetching은 병렬적으로 수행, layout 및 page의 경우 데이터 사용하는 곳에서 데이터 가져오기 좋음
- Suspense, Loading UI를 이용해 점진적 렌더링 수행하는것이 좋음
async function getData() {
const res = await fetch('https://api.example.com/...');
// The return value is *not* serialized
// You can return Date, Map, Set, etc.
// Recommendation: handle errors
if (!res.ok) {
// This will activate the closest `error.js` Error Boundary
throw new Error('Failed to fetch data');
}
return res.json();
}
export default async function Page() {
const data = await getData();
return <main></main>;
}export default async function Page() {
// revalidate this data every 10 seconds at most
const res = await fetch('https://...', { next: { revalidate: 10 } });
const data = res.json();
// ...
}fetch(`https://...`, { cache: 'no-store' })
fetch('https://...', { cache: 'force-cache' })- Next.js 를 사용하면서 위에 예문처럼 사용해봤는데 너무 편리했다.
확장기능 revalidate도 지정해줄 수 있으며 캐싱 기능도 지원해줘서 간단하게 사용하였다.
🚩 그래서 React-query가 필요한 이유가 뭘까?
- 우선 reac-query의 등장은 next.js의 서버컴포넌트보다 빨랐다.
| @tanstack/react-query | next.js servercomponent fetch |
|---|---|
| 1. 클라이언트 사이드에서 일어나는 다중패칭 문제를 효율화하기 위해 | 1. 서로 자원 공유가 어려운 서버컴포넌트의 특성상 일어나는 다중패칭 문제를 해결하기 위해 |
| 2. 쿼리키로 매개로 각 fetch 상태를 관리 | 2. 엔드포인트와 옵션을 기준으로 fetch 상태를 관리 |
-
Next.js는
동일한 엔드포인트와 동일한 옵션을 가진 요청이라면 같은 요청이며 같은 결과가 올 것이다라는 근거에 의존한다. 즉, 🔶 Next.js caching은 동일한 요청에 동일한 응답을 내려주는 것이며 매번 fetch을 수행해야 한다는 것이다. -
반면
react-query는 엔드포인트가 동일하냐 동일 옵션이 있냐는 전혀 신경쓰지 않는다.
그저 쿼리키를 기준으로 해당 쿼리키에 대한 요청사항을 처리한다.
🔶내가 원하는 값이 담긴 쿼리키의 값만 알고있다면 리액트 쿼리의 스토에서 해당 쿼리키의 값을 빼오는 행위가 가능하다.
🚩 위에 내용처럼 매번 fetch를 수행하는 Next.js의 문제로 인해 인기검색어가 매번 데이터 중복 요청을 하였고 그로인해 깜빡임 현상이 일어난것이다.
✅ 그래서 React-query로 최적화를 진행하기로 결정하였다!!!
next.js에서 react query가 필요할까?
이 블로그를 참고로 위에 내용을 정리하였다. 정말 좋은 내용이니 다들 체크해보시라!
🚩 잠깐 React Query가 무엇인가?
- React Query는 서버 상태를 효율적으로 가져오고, 캐시하며, 동기화하는데 도움을 주는 라이브러리다.
않을까?
위에 내용에 자세히 적었으니 구현해보러 가보자고!
🚩 구현방법
yarn add @tanstack/react-query패키지 설치 (docs를 참고하시라)
2. Error: Only plain objects, and a few built-ins, can be passed to Client Components from Server Components. Classes or null prototypes are not supported.
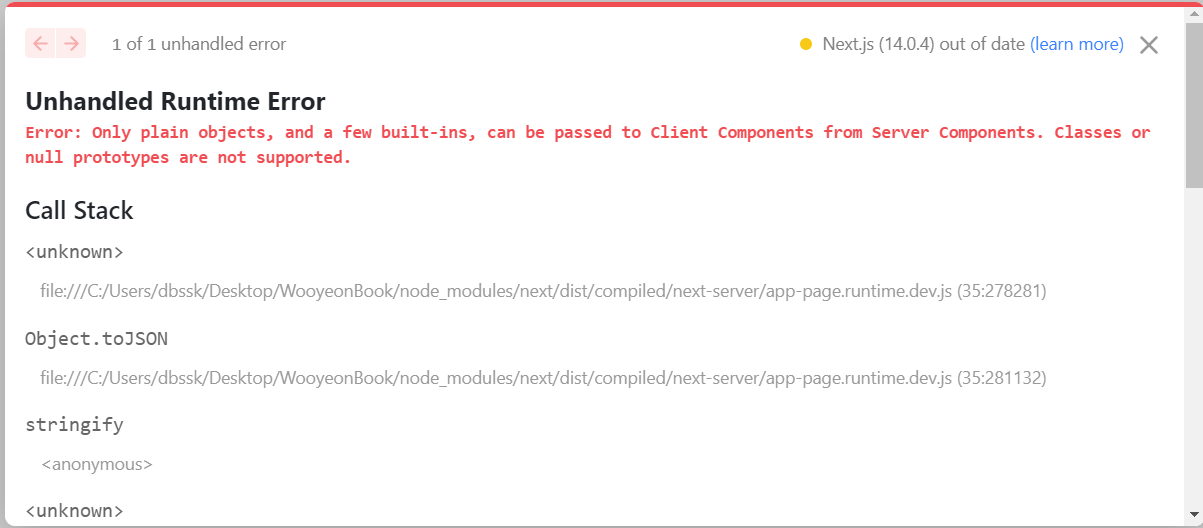
- 문제는 파일명을 ts가 아닌 tsx로 설정해야된다.
// QueryProvider.tsx
'use client';
import { QueryClient, QueryClientProvider } from '@tanstack/react-query';
const queryClient = new QueryClient({});
export default function QueryProvider({
children,
}: {
children: React.ReactNode;
}) {
return (
<QueryClientProvider client={queryClient}>{children}</QueryClientProvider>
);
}// layout.tsx
export default async function RootLayout({ children, auth }: BasicLayoutType) {
return (
<html lang="kr">
<body className={inter.className} suppressHydrationWarning={true}>
<QueryClientProvider client={queryClient}>
<RecoilRootWrapper>
<Header />
{children}
{auth}
<Footer />
</RecoilRootWrapper>
</QueryClientProvider>
</body>
</html>
);
}3.@tanstack/react-query-devtools 패키지 설치 후 에러 typeerror: queryclient.getquerycache is not a function
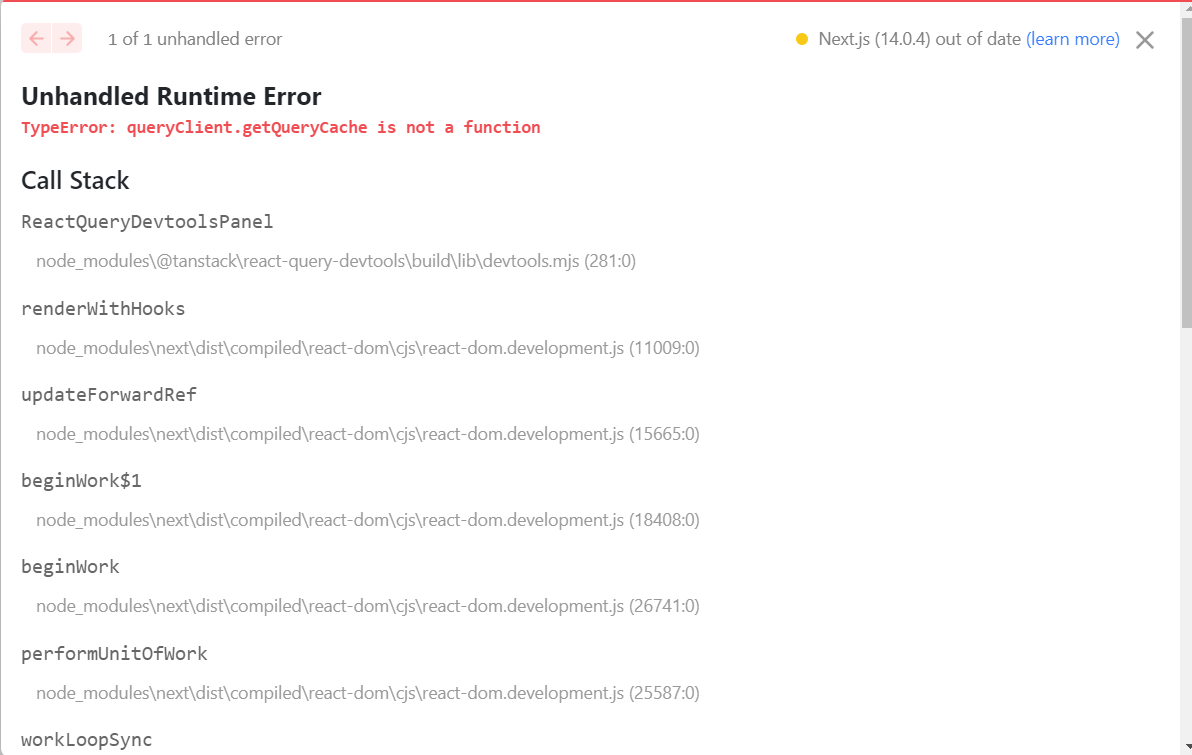
react-query-devtools is not working in nextjs v13 이슈 참고
-
우선 아래 tanStackQuery에서 yarn add @tanstack/react-query-devtools@4 설치 후 문제가 생김
-
위에 깃헙을 참고하면
yarn add @tanstack/react-query-devtools": "5.0.0-alpha.52로 다시 설치해야된다. -
"ENOENT" 오류는 일반적으로 파일이나 디렉터리가 존재하지 않을 때 발생하는 에러입니다. 이는 특정 파일을 찾을 수 없거나 파일 시스템 문제로 인해 발생할 수 있습니다. 주어진 오류 메시지에 따르면, @tanstack/react-query-devtools의 특정 파일을 찾을 수 없다는 것을 의미합니다. -
yarn cache clean 후
yarn add @tanstack/react-query-devtools@5.0.0-alpha.53
설치
'use client';
import { QueryClient, QueryClientProvider } from '@tanstack/react-query';
import { ReactQueryDevtools } from '@tanstack/react-query-devtools';
const queryClient = new QueryClient({
defaultOptions: { queries: { staleTime: 60000, gcTime: 10 * (60 * 1000) } },
});
export default function QueryProvider({
children,
}: {
children: React.ReactNode;
}) {
return (
<QueryClientProvider client={queryClient}>
{children}
<ReactQueryDevtools initialIsOpen={false} />
</QueryClientProvider>
);
}// useKeyWordsQuery.ts
import { searchKeyword } from '@/recoil/atom/searchKeyword';
import { useQuery, useMutation, useQueryClient } from '@tanstack/react-query';
import { useRecoilState } from 'recoil';
interface popularKeywords {
id: string;
keyword: string | number | Date;
search_count: string;
created_at: Date;
}
export default function useKeyWordsQuery() {
// 검색어 리코일
const [keyword, setKeyword] = useRecoilState(searchKeyword);
const queryClient = useQueryClient();
const getHotwordsData = useQuery<popularKeywords[]>({
queryKey: ['oldHotWords'],
queryFn: () =>
fetch(
`${process.env.NEXT_PUBLIC_SERVER_BASE_URL}/search/supabase/keywords`,
).then((res) => res.json()),
refetchOnWindowFocus: false,
});
// 검색어 sever에서 확인하는 로직
const keyonSubmitData = useMutation({
// 인기 검색어 데이터
mutationFn: async (newHotWords) => {
const response = await fetch(
`${process.env.NEXT_PUBLIC_SERVER_BASE_URL}/search/supabase/popularSearch?keyword=${keyword}`,
{
method: 'GET',
body: JSON.stringify(newHotWords),
headers: { 'Content-Type': 'application/json; charset=UTF-8' },
},
);
if (!response.ok) {
throw new Error('Failed to fetch new hot words');
}
//데이터 변환
const key = await response.json();
// 데이터 추가
const postdata = {
keyword: keyword,
search_count: 1,
created_at: new Date(),
};
// 검색어가 대한 기록이 서버에 이미 존재하는지 확인
if (key.length > 0) {
await fetch(
`${process.env.NEXT_PUBLIC_SERVER_BASE_URL}/search/update/supabase/keyword?keyword=${keyword}&count=${key[0].search_count}`,
{
method: 'PUT',
body: JSON.stringify({ search_count: key[0].search_count + 1 }),
headers: { 'Content-Type': 'application/json; charset=UTF-8' },
},
);
} else {
// 검색어 기록이 서버에 없으면 검색어 추가
await fetch(
`${process.env.NEXT_PUBLIC_SERVER_BASE_URL}/search/create/supabase/keywords`,
{
method: 'POST',
body: JSON.stringify(postdata),
headers: { 'Content-Type': 'application/json; charset=UTF-8' },
},
);
}
},
onSuccess: () => {
queryClient.invalidateQueries({ queryKey: ['oldHotWords'] });
},
});
return { getHotwordsData, keyonSubmitData };
}- isLoading일때 스켈레톤 UI 적용하여 사용자 경험 개선하였다.
// react-query 훅
const {
getHotwordsData: { isLoading, error, data },
} = useKeyWordsQuery();
if (error) return <div> There was an error!</div>;
return (
<dd>
<ol className={styles.hotWordPopularWrap}>
{isLoading || !data?.length
? Array.from({ length: 9 }).map((_, index) => (
<li className={styles.hotWordPopularLi} key={index}>
<div className={styles.loadingSkeleton}></div>
</li>
))
: data?.map((hotword: any, index: any) => (
<li className={styles.hotWordPopularLi} key={index}>
<span
className={styles.hotWordLink}
onMouseDown={() => {
handleValueClick(hotword.keyword as string);
}}>
<span className={styles.hotWordNum}>{index + 1}</span>
<span className={styles.hotWordTitle}>
{hotword.keyword as string}
</span>
<Image
src={lineIcon}
alt="lineIcon"
className={styles.lineIcon}
width={15}
height={2}
/>
</span>
</li>
))}
</ol>
</dd>
</dl>
);
}
- 유튜브와 예전에 사논 react-query 강의와 docs를 참고로 구현하였다.
🔶 깜빡임의 현상과 속도가 현저히 좋아졌다.
defaultOptions: { queries: { staleTime: 60000, gcTime: 10 * (60 * 1000) }staleTime를 60000로 설정하여 1분동안 새로운 데이터로 간주한다. 즉 이 시간 동안 새로운 데이터를 불러오지 않는다.
gcTime을 10분이 지나면 데이터를 메모리에서 지운다. 필요 없는 데이터를 10분마다 지워서 공간을 확보한다.
최적화 전 속도(3.1s)
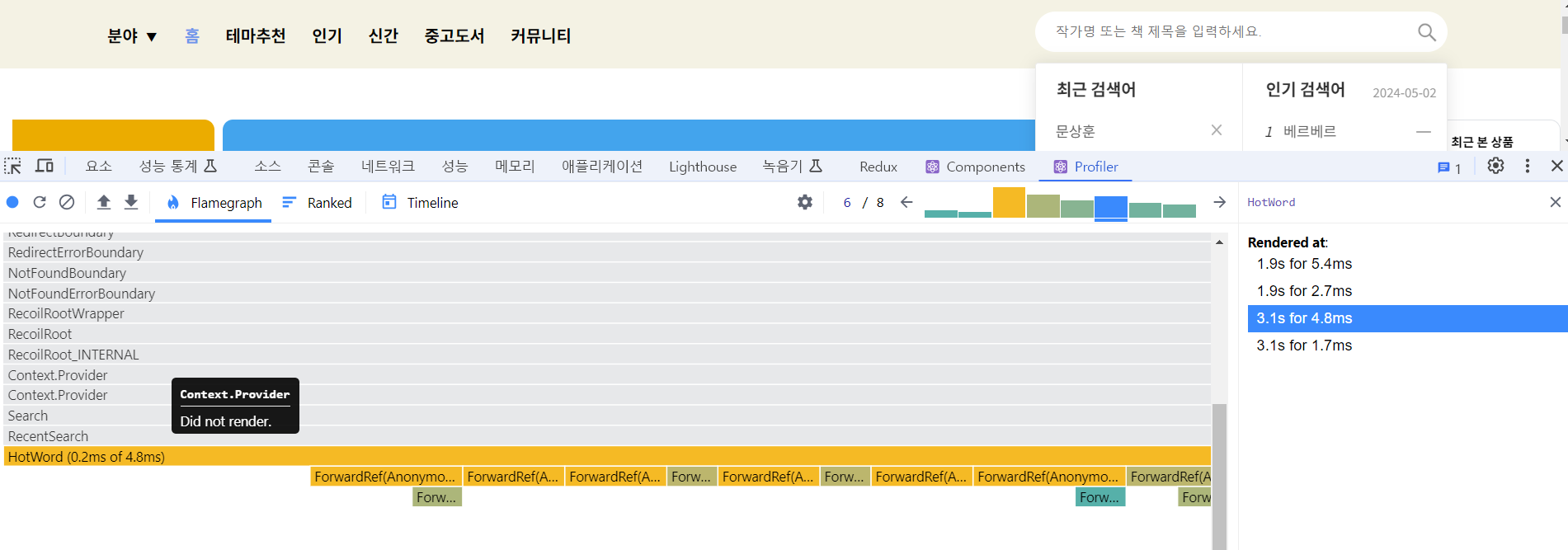
최적화 후 속도(0.9s)
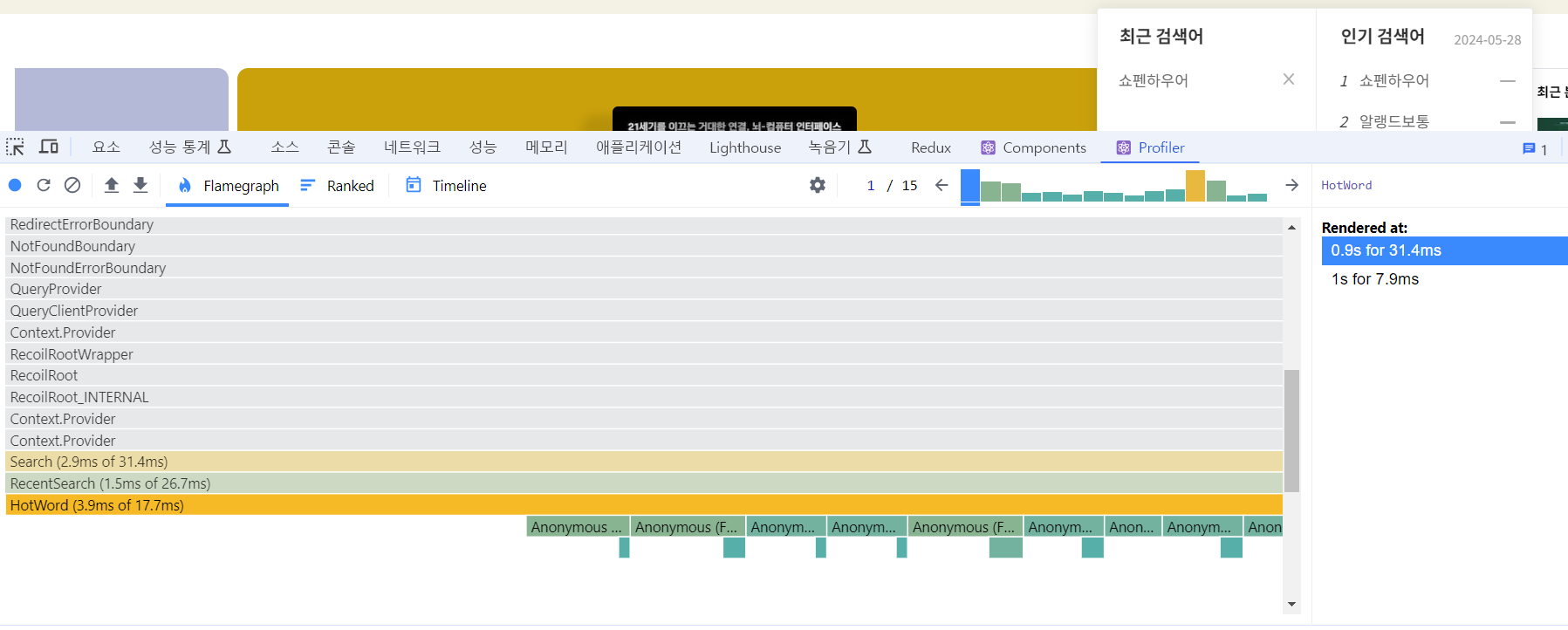
데이터 중복을 최소화 시켜 속도나 깜빡임 현상을 최적화하는 경험은 언제나 뿌뜻하다^^
