웹 통신의 큰 흐름 1
이번 포스팅부터 웹 개발을 할 경우 일어나는 웹 통신의 큰 흐름을 네트워크의 관점에서 알아보려고 합니다. 'google.com'을 chrome창에 입력할 경우 일어나는 일에 대해 설명해보라는 질문은 개발자 취업을 준비하시는 분들이라면 익숙한 질문이라고 생각합니다. 이번 포스팅은 이러한 질문에 대한 대답을 포스팅으로 정리하며 네트워크 전반에 걸쳐 일어나는 일에 대해 정리하며 시리즈 형식으로 진행할 생각입니다.
이번 시간에는 가장 위에 해당하는 HTTP, DNS와 관련된 내용을 살펴보겠습니다.
1. HTTP Request
chrome창을 열고 url창에 www.naver.com이라는 주소를 입력하고 엔터를 치면 어떤 일이 일어날까요? 경험상으로 우리는 네이버 홈페이지가 나오고 화면이 보인다는 것을 알고 있습니다.
그렇담 어떤 방법을 통해 이러한 일이 가능할까요? 엔터를 누르는 순간부터 브라우저와 네트워크가 어떻게 움직이는지 살펴보겠습니다.
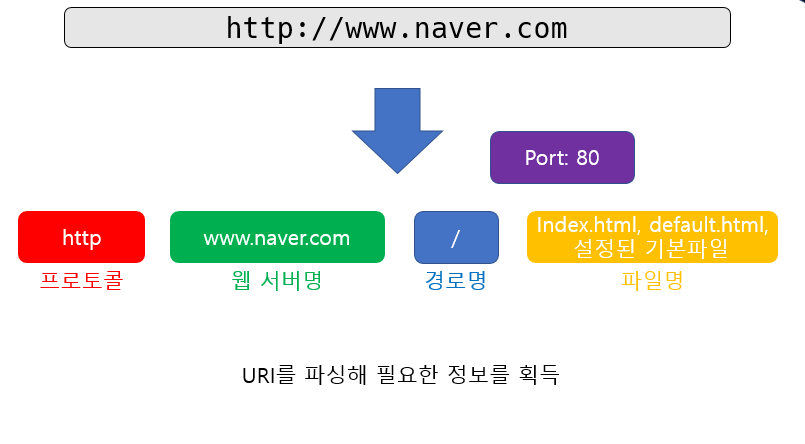 우리가 uri를 입력하고 엔터를 치는 순간, 브라우저는 우리가 입력한 주소를 내부적으로 파싱하여 필요한 정보들을 파악합니다. 위에 보이는 프로토콜, 웹 서버명, 경로명, 포트번호, 파일명 등이 그런 것들이죠.
우리가 uri를 입력하고 엔터를 치는 순간, 브라우저는 우리가 입력한 주소를 내부적으로 파싱하여 필요한 정보들을 파악합니다. 위에 보이는 프로토콜, 웹 서버명, 경로명, 포트번호, 파일명 등이 그런 것들이죠.
이런 내용을 바탕으로 브라우저는 어디에 어떤 파일(혹은 서비스)를 받아야 하는지 파악하는 것입니다.
 브라우저가 하고싶은 일은 HTTP Request Message라는 메시지를 작성하여 원하는 서버에 보내고 그 응답을 받아 우리에게 보여줍니다. 이렇게 서버에 요청하는 메시지를 HTTP Request Message라고 합니다. 흔히 우리가 HTTP로 부르는 프로토콜을 바탕으로 작성되는 Message죠.
브라우저가 하고싶은 일은 HTTP Request Message라는 메시지를 작성하여 원하는 서버에 보내고 그 응답을 받아 우리에게 보여줍니다. 이렇게 서버에 요청하는 메시지를 HTTP Request Message라고 합니다. 흔히 우리가 HTTP로 부르는 프로토콜을 바탕으로 작성되는 Message죠.
디테일을 하나하나 따지면 많은 헤더가 존재하지만, 핵심은 서버에게 무엇을, 어떻게 해서 받겠다는 내용을 적는 것입니다. 또 필요하다면 서버에 보내줄 데이터를 같이 작성하기도 하죠.
 여기서 '무엇을'에 해당하는 내용을 URI라고 합니다. 그리고 '어떻게 해서'에 해당하는 내용을 method라고 하죠. 그리고 만약 서버에 보낼 데이터가 있다면 아래에 데이터도 작성하여 보내게 됩니다.
여기서 '무엇을'에 해당하는 내용을 URI라고 합니다. 그리고 '어떻게 해서'에 해당하는 내용을 method라고 하죠. 그리고 만약 서버에 보낼 데이터가 있다면 아래에 데이터도 작성하여 보내게 됩니다.
 조금 더 형식을 자세히 들어가보면 위 그림과 같습니다. 맨 첫줄에 리퀘스트 라인이라는 라인을 작성합니다. 메소드, URI, HTTP버전등의 정보를 작성하죠. 이후 HTTP 헤더를 작성하고 이후 메시지 본문을 작성하게 됩니다.
조금 더 형식을 자세히 들어가보면 위 그림과 같습니다. 맨 첫줄에 리퀘스트 라인이라는 라인을 작성합니다. 메소드, URI, HTTP버전등의 정보를 작성하죠. 이후 HTTP 헤더를 작성하고 이후 메시지 본문을 작성하게 됩니다.
 우리의 www.naver.com을 예로 들면 저렇게 작성됩니다. 기본적으로 브라우저의 주소창에 주소를 치는 행위는 GET을 의미합니다. 따라서 리퀘스트라인은 GET, 그리고 생략되어 있기에 /index.html(혹은 default.html등 서버의 기본 설정)파일이 됩니다. 또 HTTP/1.1로 버전명을 적게 됩니다.
우리의 www.naver.com을 예로 들면 저렇게 작성됩니다. 기본적으로 브라우저의 주소창에 주소를 치는 행위는 GET을 의미합니다. 따라서 리퀘스트라인은 GET, 그리고 생략되어 있기에 /index.html(혹은 default.html등 서버의 기본 설정)파일이 됩니다. 또 HTTP/1.1로 버전명을 적게 됩니다.
헤더의 영역에는 프로토콜, 웹 서버명, 경로명, 포트 등 브라우저에서 파싱한 데이터를 작성합니다.
메시지 본문은 GET이기 때문에 공백으로 남아있습니다.
 이렇게 메시지를 작성하고 작성한 메시지를 서버로 보내면 서버는 HTTP Response라는 메시지를 전달해줍니다. 위에서 보이는 형식으로 response를 작성해주며, req메시지의 하단에 보이는 html태그로 시작하는 부분부터의 데이터를 응답으로 보내줍니다. 그러면 브라우저는 해당 데이터를 다시 파싱하여 우리에게 보여주고 그게 바로 우리가 보는 네이버 홈페이지 화면이 되는 것이죠.
이렇게 메시지를 작성하고 작성한 메시지를 서버로 보내면 서버는 HTTP Response라는 메시지를 전달해줍니다. 위에서 보이는 형식으로 response를 작성해주며, req메시지의 하단에 보이는 html태그로 시작하는 부분부터의 데이터를 응답으로 보내줍니다. 그러면 브라우저는 해당 데이터를 다시 파싱하여 우리에게 보여주고 그게 바로 우리가 보는 네이버 홈페이지 화면이 되는 것이죠.
브라우저가 html을 어떻게 파싱하여 화면에 보여주는지도 매우 중요하고 흥미로운 내용입니다. 하지만 이번 포스팅에선 브라우저 자체의 렌더링 방법이 아닌, 어떻게 이런 HTTP Message를 주고 받을 수 있는지에 포커스를 두도록 하겠습니다.
여튼, 브라우저는 HTTP Response를 받으면 그 내용을 해석하여 우리가 보는 홈페이지 모습으로 보여줄 수 있습니다. 따라서 HTTP Reqest Message를 작성하고 서버에 보내고 HTTP Response Message를 받는 것이 중요하죠.
DNS Request
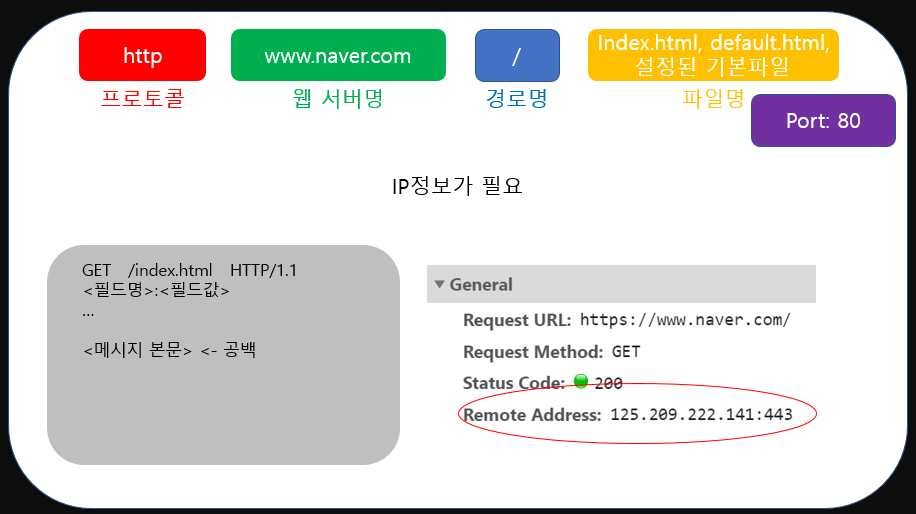 위 그림의 오른쪽 아래 사진은 제가 실제로 chrome창에 'www.naver.com'을 입력한 후 브라우저에서 확인한 Response Message 정보의 일부입니다.
위 그림의 오른쪽 아래 사진은 제가 실제로 chrome창에 'www.naver.com'을 입력한 후 브라우저에서 확인한 Response Message 정보의 일부입니다.
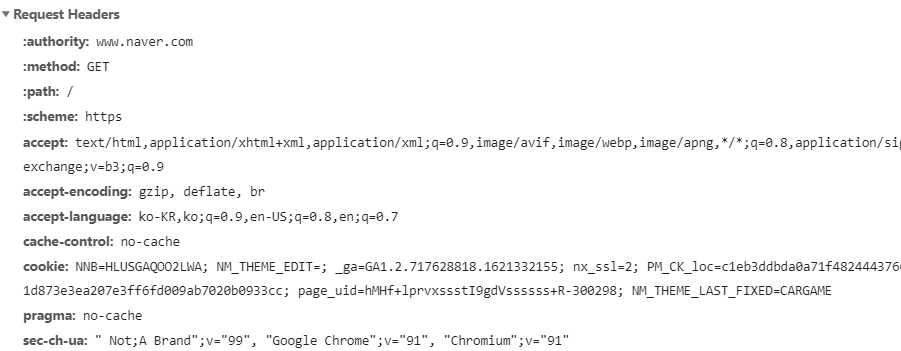 그리고 위 그림은 우리가 보낸 HTTP Request Message의 헤더 정보입니다. URL, Method 등등의 기본 정보가 보이시나요? 브라우저는 우리가 입력한 주소정보를 파싱하여 필요한 정보를 뽑아내고 저렇게 헤더의 형식으로 HTTP Request Message를 작성합니다.
그리고 위 그림은 우리가 보낸 HTTP Request Message의 헤더 정보입니다. URL, Method 등등의 기본 정보가 보이시나요? 브라우저는 우리가 입력한 주소정보를 파싱하여 필요한 정보를 뽑아내고 저렇게 헤더의 형식으로 HTTP Request Message를 작성합니다.
그런데 조금 이질적인 부분이 하나 있습니다. 다른 어려운 헤더들은 그렇다 치더라도 Response Message에서 빨간 동그라미친 Remote Address부분을 살펴보면 ip정보가 담겨있는 것을 알 수 있습니다.
그렇습니다. 컴퓨터는 사람처럼 도메인명(naver 등)이 아니라 ip주소를 기반으로 통신을 진행하죠. 따라서 브라우저가 Req Message를 작성할 때 ip주소가 필요합니다. 하지만 우리는 ip를 입력한 기억이 없죠. 우리는 'www.naver.com'이라는 정보를 주소창에 입력했을 뿐입니다. 그러나 브라우저는 정확하게 네이버 서버의 ip를 파악해 우리에게 홈페이지를 보여주죠.
의문점은 어떻게 서버의 ip정보를 알아내는가? 입니다. 분명히 HTTP Req를 작성하고 서버의 ip를 적어서 보낼텐데 우리는 제공한적이 없는데 말이죠.
정답은 바로 DNS에 의뢰하여 www.naver.com에 해당하는 ip주소를 받아오는 것입니다.
좀 더 구체적인 정보를 위해 먼저 PC가 통신하는 대략적인 그림을 살펴보겠습니다.
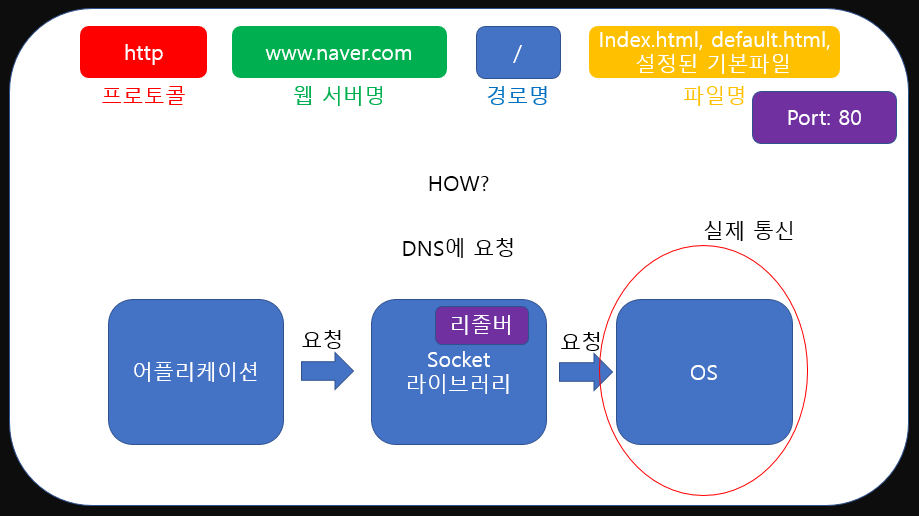 사실 컴퓨터가 인터넷을 이용한다. 통신한다 라는 개념은 전부 OS(운영체제)라고 불리는 소프트웨어의 권한입니다. 우리의 chrome같은 브라우저는 실제로 인터넷을 이용해 통신할 수 없습니다.
사실 컴퓨터가 인터넷을 이용한다. 통신한다 라는 개념은 전부 OS(운영체제)라고 불리는 소프트웨어의 권한입니다. 우리의 chrome같은 브라우저는 실제로 인터넷을 이용해 통신할 수 없습니다.
그렇다면 실제 통신이 어떻게 이루어지는가.. 하면 브라우저와 같은 '어플리케이션'은 Socket 라이브러리라는 도구를 이용하여 OS에게 "이 메시지좀 통신해서 보내줘 ㅠㅠ"와 같이 부탁하게 됩니다. 그러면 OS는 실제로 네트워크를 이용한 통신을 진행하고 그 결과를 다시 어플리케이션에게 전달해주는 것이죠.
Socket라이브러리는 'OS에게 통신을 요청하기위해 어플리케이션이 사용하는 도구' 정도로 이해해주시면 됩니다.
ip얘기하다 뜬금 무슨 얘기인지 모르시겠나요? 다시 Socket 라이브러리쪽을 살펴봐주세요. 저 라이브러리에는 '리졸버'라고 하는 친구(영역)이 존재합니다. 그리고 저 리졸버라는 친구가 바로 DNS에 ip를 물어봐주는 친구죠.
이제 전체 흐름을 살펴보겠습니다.
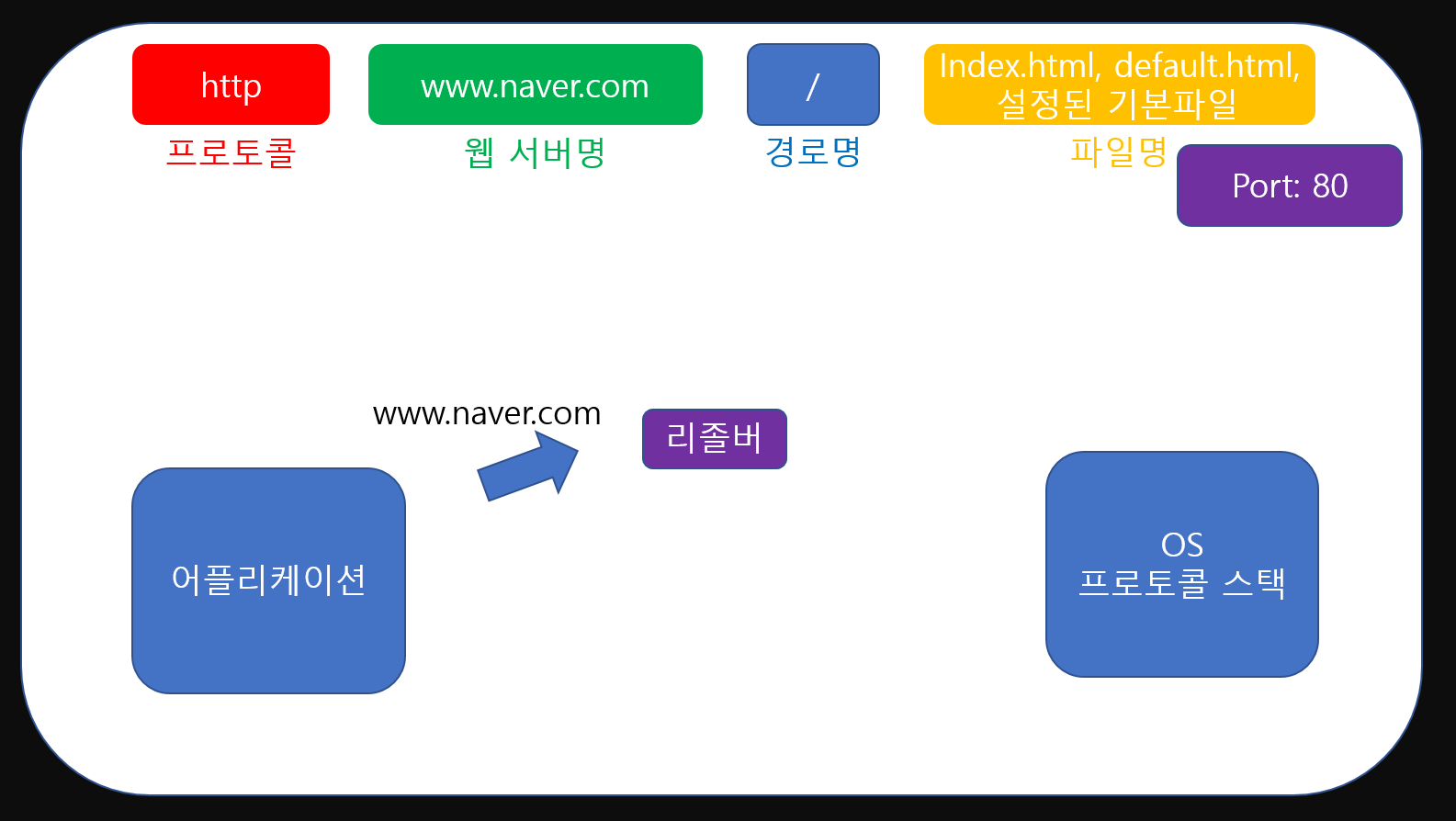 먼저 어플리케이션은 HTTP Message를 작성하는 도중 ip정보가 필요하면 리졸버에게 'www.naver.com'을 넘겨주며 ip요청을 요청하게 됩니다.
먼저 어플리케이션은 HTTP Message를 작성하는 도중 ip정보가 필요하면 리졸버에게 'www.naver.com'을 넘겨주며 ip요청을 요청하게 됩니다. 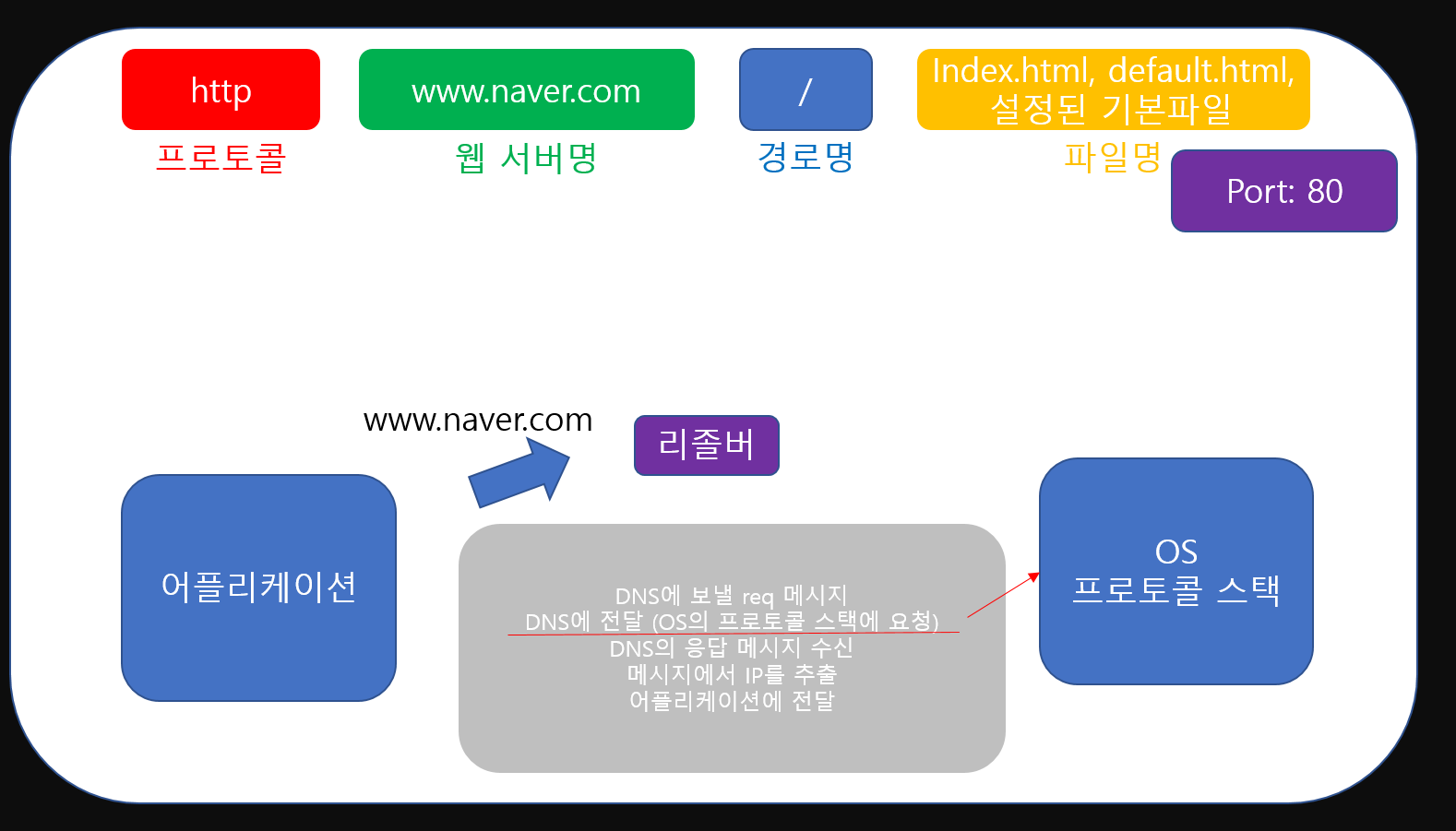 그러면 리졸버는 'www.naver.com'을 이용해 DNS에 보낼 req메시지를 작성하고 OS의 프로토콜 스택에 요청하여 DNS에 메시지를 전달합니다. (이때 통신 방법은 UDP라는 방법을 사용하며 DNS의 ip는 PC가 미리 알고 있는 상황입니다. 이에 대한 설명은 나중에 포스팅 기회가 있다면 포스팅하겠습니다.)
그러면 리졸버는 'www.naver.com'을 이용해 DNS에 보낼 req메시지를 작성하고 OS의 프로토콜 스택에 요청하여 DNS에 메시지를 전달합니다. (이때 통신 방법은 UDP라는 방법을 사용하며 DNS의 ip는 PC가 미리 알고 있는 상황입니다. 이에 대한 설명은 나중에 포스팅 기회가 있다면 포스팅하겠습니다.)
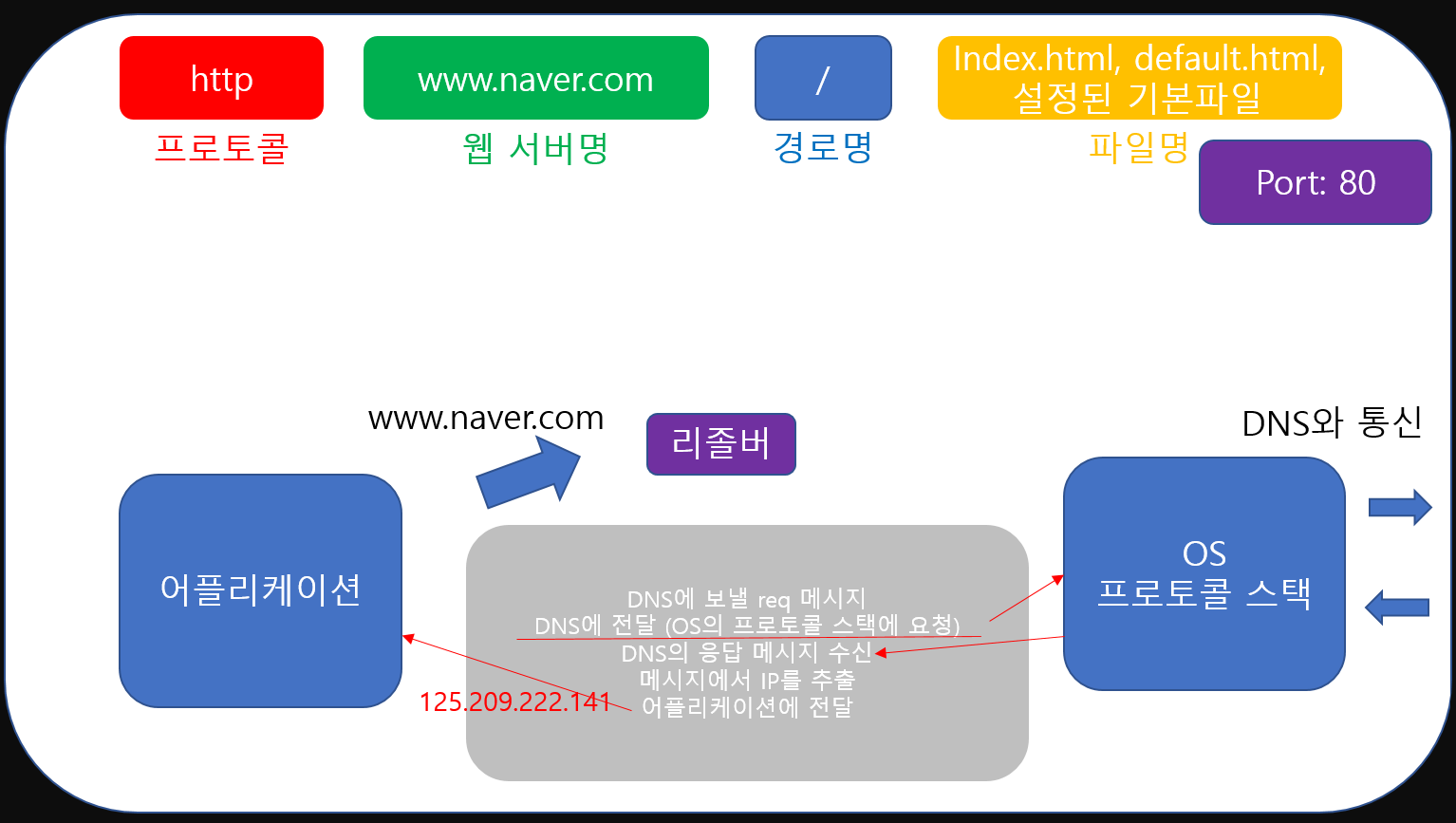 그러면 OS는 DNS와 통신하여 ip주소를 받아오고 리졸버에게 이 정보를 넘겨줍니다. 그러면 리졸버가 응답 메시지에서 ip정보를 추출하여 어플리케이션에게 'www.naver.com'에 해당하는 ip주소를 넘겨주게 되죠.
그러면 OS는 DNS와 통신하여 ip주소를 받아오고 리졸버에게 이 정보를 넘겨줍니다. 그러면 리졸버가 응답 메시지에서 ip정보를 추출하여 어플리케이션에게 'www.naver.com'에 해당하는 ip주소를 넘겨주게 되죠.
이러한 방법을 통해 어플리케이션은 도메인에 해당하는 ip주소를 알아낼 수 있고 이제 다시 HTTP Req Message를 작성하여 다시 OS의 프로토콜 스텍에 통신을 요청합니다. 이번엔 DNS가 아니라 네이버 서버와 통신한 뒤 그 결과를 받아볼 수 있게 되는거죠.
DNS의 동작
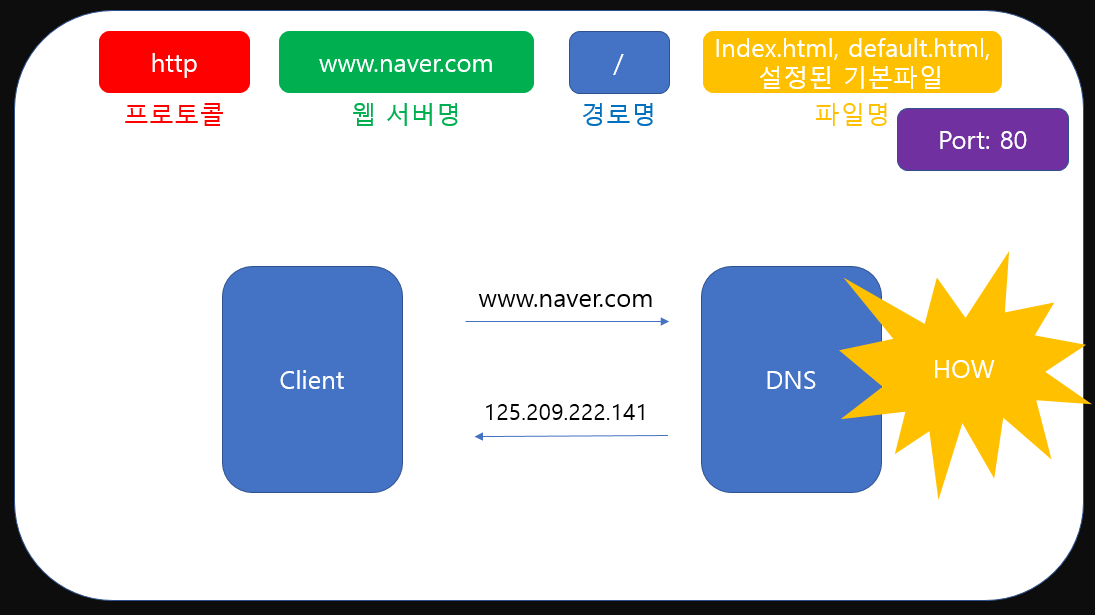 우리는 HTTP Message에 작성할 ip를 DNS서버로부터 받아온다고 배웠습니다. 그렇다면 DNS서버는 어떤 식으로 도메인에 해당하는 ip를 제공해주는지 살펴보겠습니다.
우리는 HTTP Message에 작성할 ip를 DNS서버로부터 받아온다고 배웠습니다. 그렇다면 DNS서버는 어떤 식으로 도메인에 해당하는 ip를 제공해주는지 살펴보겠습니다.
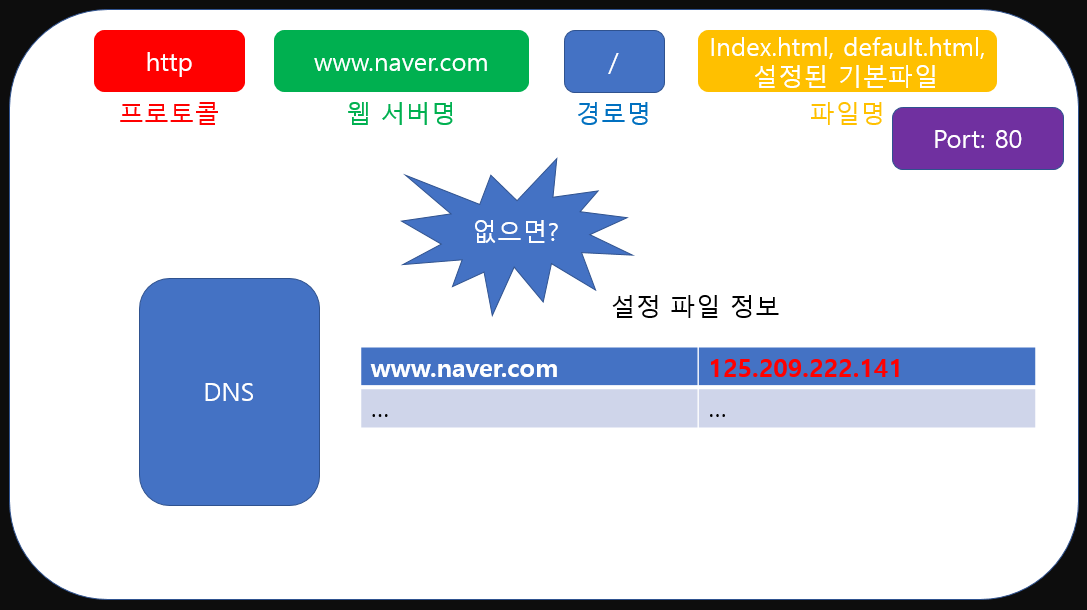 DNS에는 설정 파일 정보들이 들어있습니다. 실제 모습이 저렇게 되어 있지는 않지만, 쉽게 생각하면 도메인(key)에 해당하는 ip(value)를 테이블의 형태로 가지고 있다고 보면 됩니다.
DNS에는 설정 파일 정보들이 들어있습니다. 실제 모습이 저렇게 되어 있지는 않지만, 쉽게 생각하면 도메인(key)에 해당하는 ip(value)를 테이블의 형태로 가지고 있다고 보면 됩니다.
DNS가 도메인 네임과 함께 요청을 받으면 해당하는 ip를 찾아 응답해주는 방식이죠. 문제는 이 세상의 도메인명은 정말 많다는 겁니다. 당장 우리가 돌아다니는 웹의 수 많은 홈페이지는 전부 각자의 도메인을 갖고 있죠.
이런 방대한 양의 정보를 하나의 DNS에서 관리하는 것은 사실 불가능합니다. 즉, DNS에서도 도메인의 ip정보가 없을 수 있다는 말이죠. 그럴 경우 어떻게 해결할 수 있을까요?
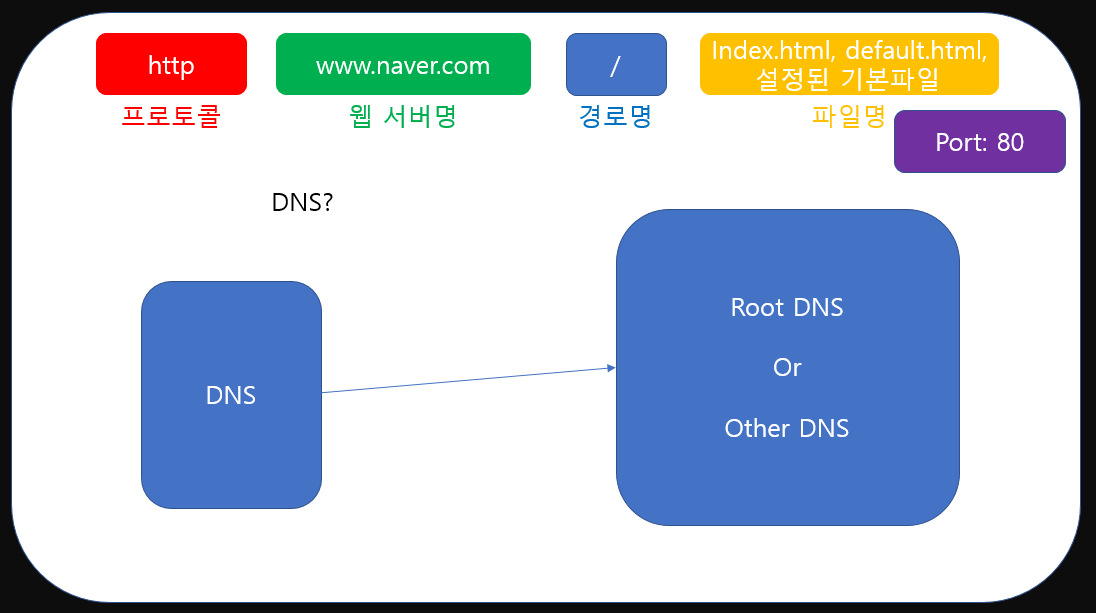 결론부터 얘기하면 DNS는 Root DNS또는 다른 DNS에게 다시 요청을 보내 도메인명이 있는지 확인하고 응답을 받아 우리에게 다시 응답해줍니다. 이러한 방식을 이해하기 위해선 우선 DNS가 어떤 구조를 갖고 있어야 하는지 알아야 합니다.
결론부터 얘기하면 DNS는 Root DNS또는 다른 DNS에게 다시 요청을 보내 도메인명이 있는지 확인하고 응답을 받아 우리에게 다시 응답해줍니다. 이러한 방식을 이해하기 위해선 우선 DNS가 어떤 구조를 갖고 있어야 하는지 알아야 합니다.
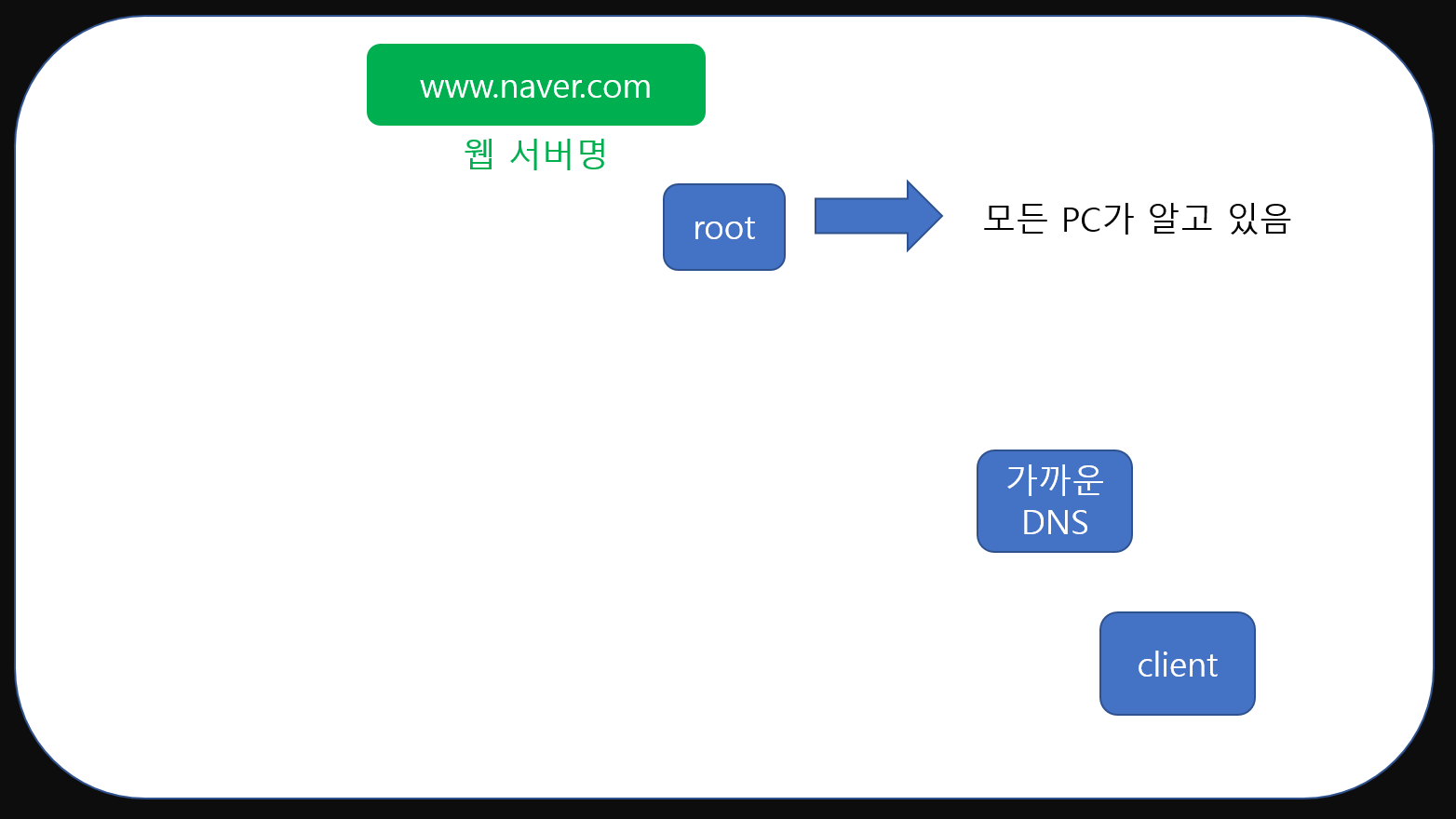 먼저 DNS에는 최상위에 존재하는 root DNS가 있습니다. 이 DNS의 주소는 세상의 모든 DNS가 알고 있죠. 가장 위에 있는 DNS라고 보면 되겠습니다. 그리고 이러한 root DNS에는 13개의 DNS서버데이터가 저장되어있죠.
먼저 DNS에는 최상위에 존재하는 root DNS가 있습니다. 이 DNS의 주소는 세상의 모든 DNS가 알고 있죠. 가장 위에 있는 DNS라고 보면 되겠습니다. 그리고 이러한 root DNS에는 13개의 DNS서버데이터가 저장되어있죠.
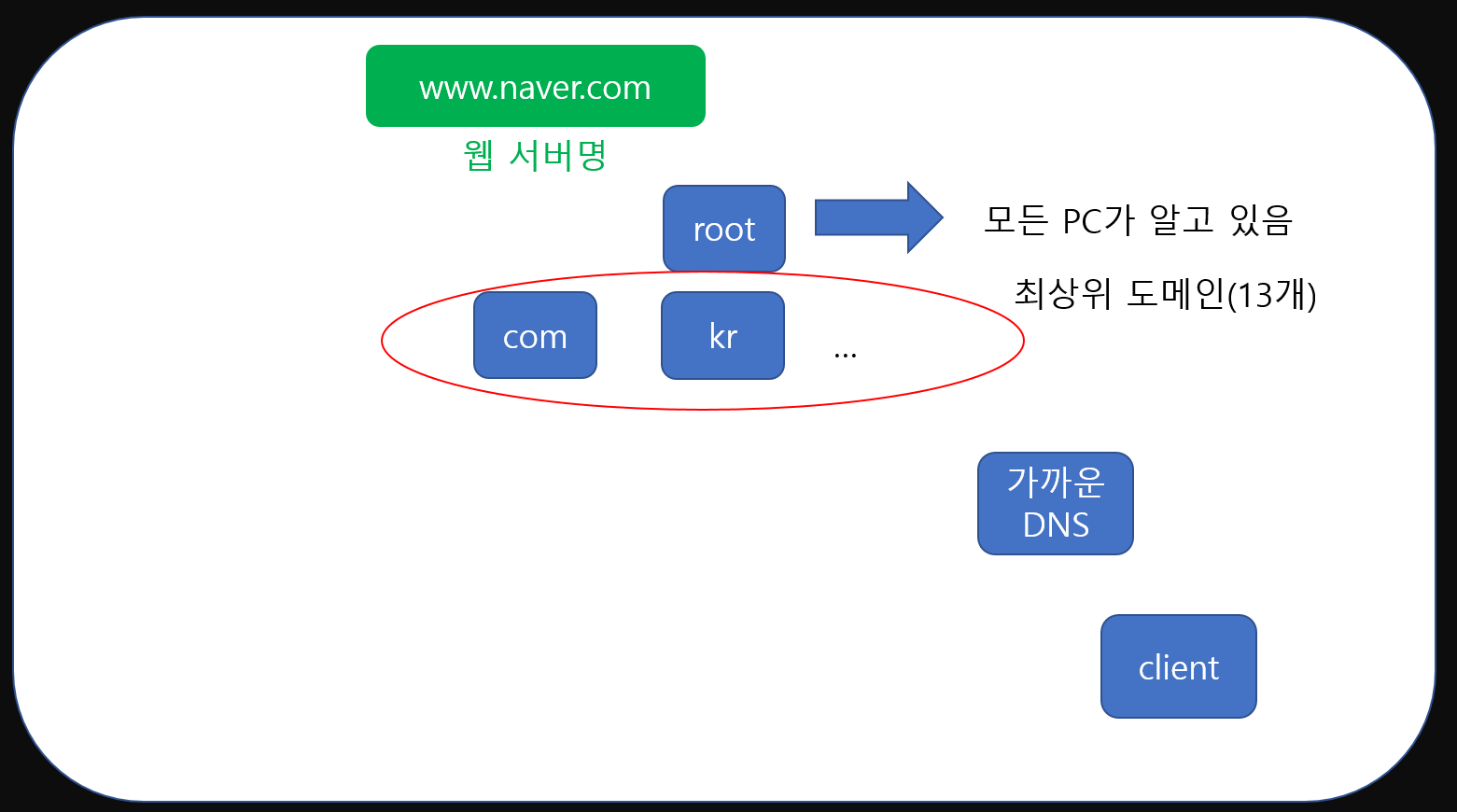 우리가 흔히 볼 수 있는 com, kr 등등의 주소 정보가 바로 그것입니다. 이들은 최상위 도메인이라고 불리며 13가지 종류가 존재합니다. root DNS에는 이들의 정보가 저장되어있죠.
우리가 흔히 볼 수 있는 com, kr 등등의 주소 정보가 바로 그것입니다. 이들은 최상위 도메인이라고 불리며 13가지 종류가 존재합니다. root DNS에는 이들의 정보가 저장되어있죠.
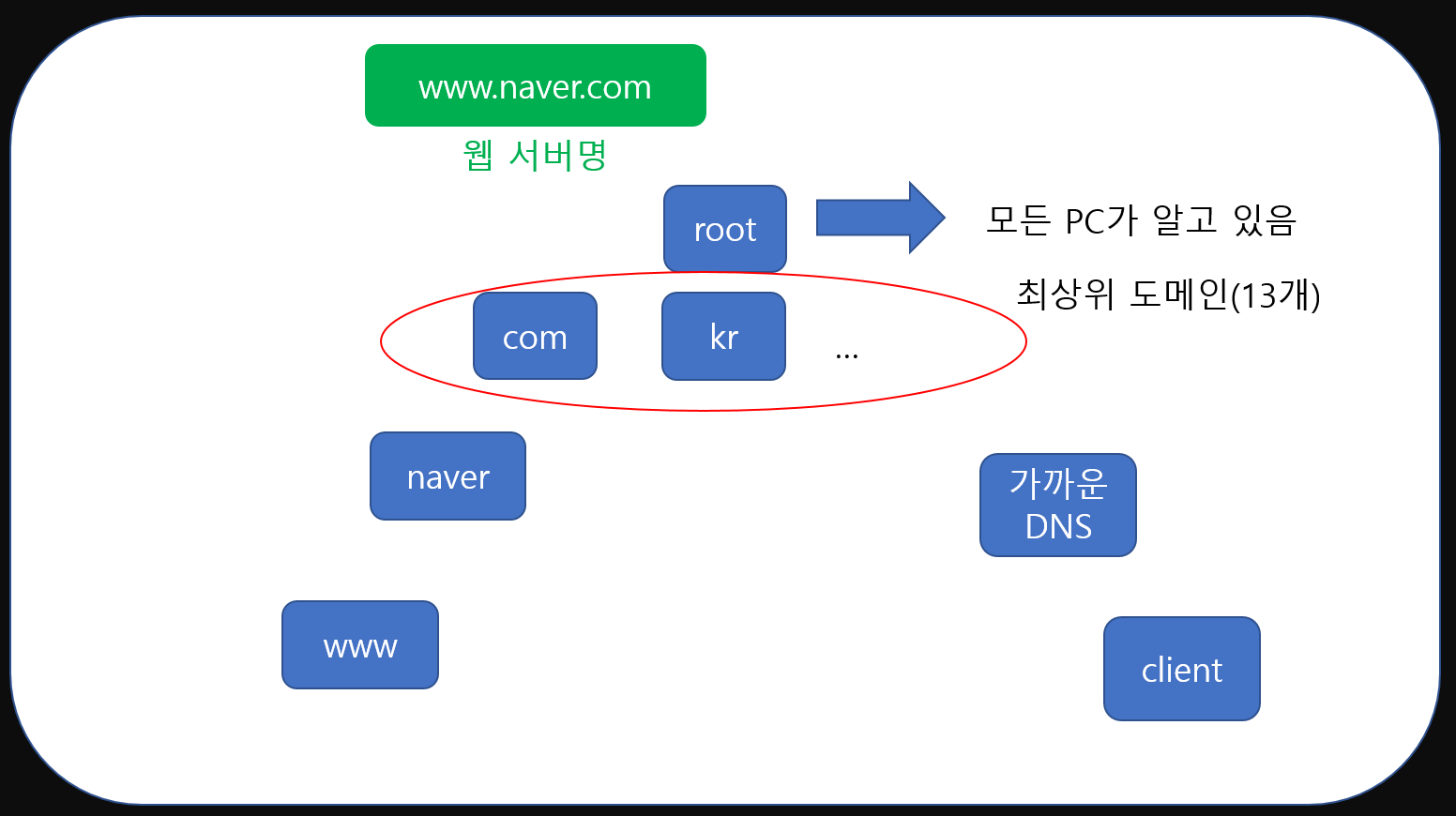
이후 com에 해당하는 DNS는 다시 여러개의 com과 관련된 정보들을 가진 DNS를 기억합니다. 예를 들면 naver.com, google.com등의 정보가 해당되겠죠.
즉, DNS구조의 결론은 한 DNS에서 모든 정보를 저장할 수 없으니 여러개의 DNS를 계층 구조로 관리하고 트리형식으로 만들어 root DNS만 알면 모든 정보에 접근할 수 있는 형태라고 볼 수 있습니다. 그럼 이런 구조에서 실제 DNS를 어떻게 가져오는지 확인해보겠습니다.
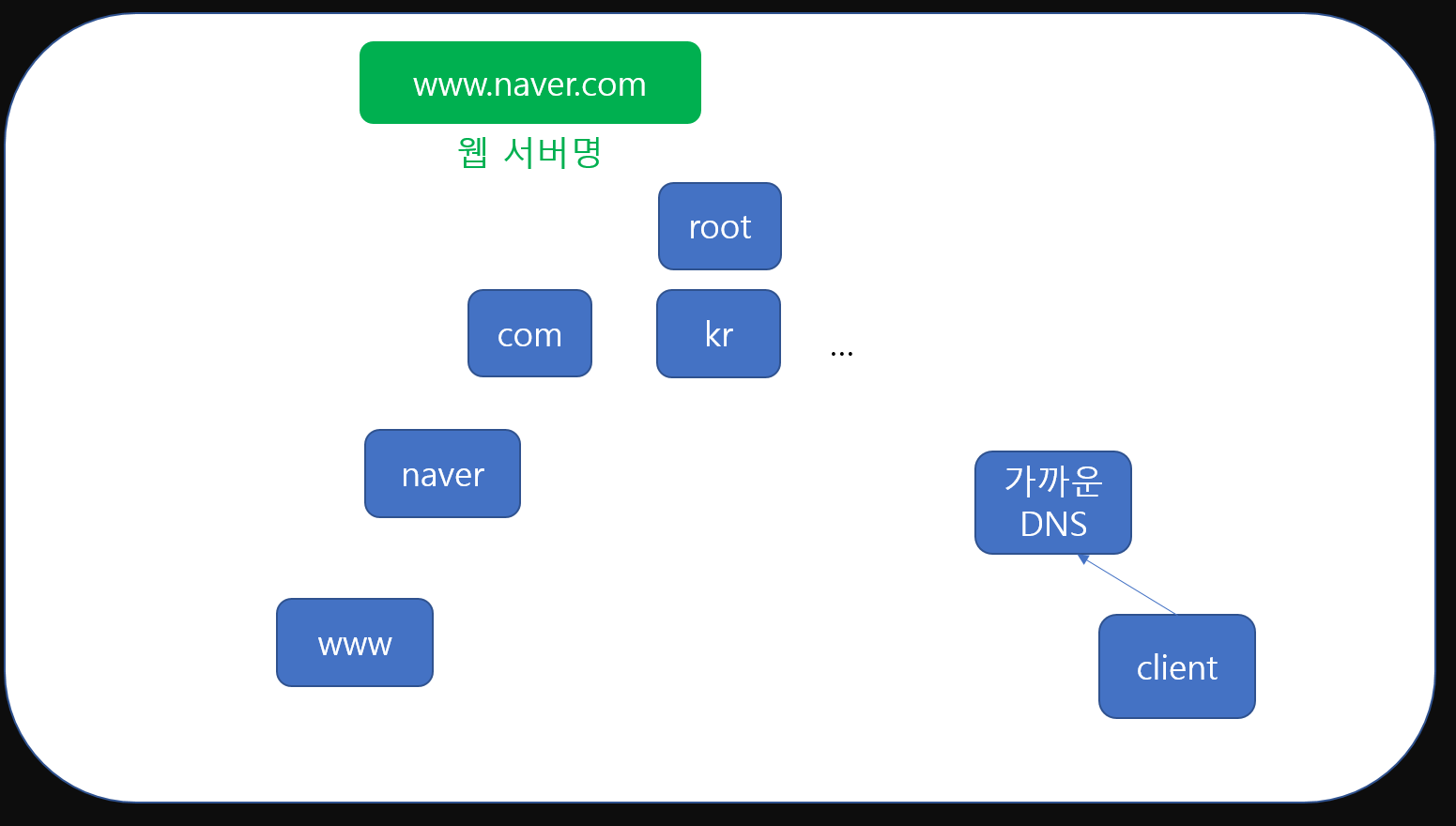 먼저 client는 가장 가까운 DNS에 ip정보를 요청합니다. 'www.naver.com'이라는 도메인명과 함께 말이죠.
먼저 client는 가장 가까운 DNS에 ip정보를 요청합니다. 'www.naver.com'이라는 도메인명과 함께 말이죠.
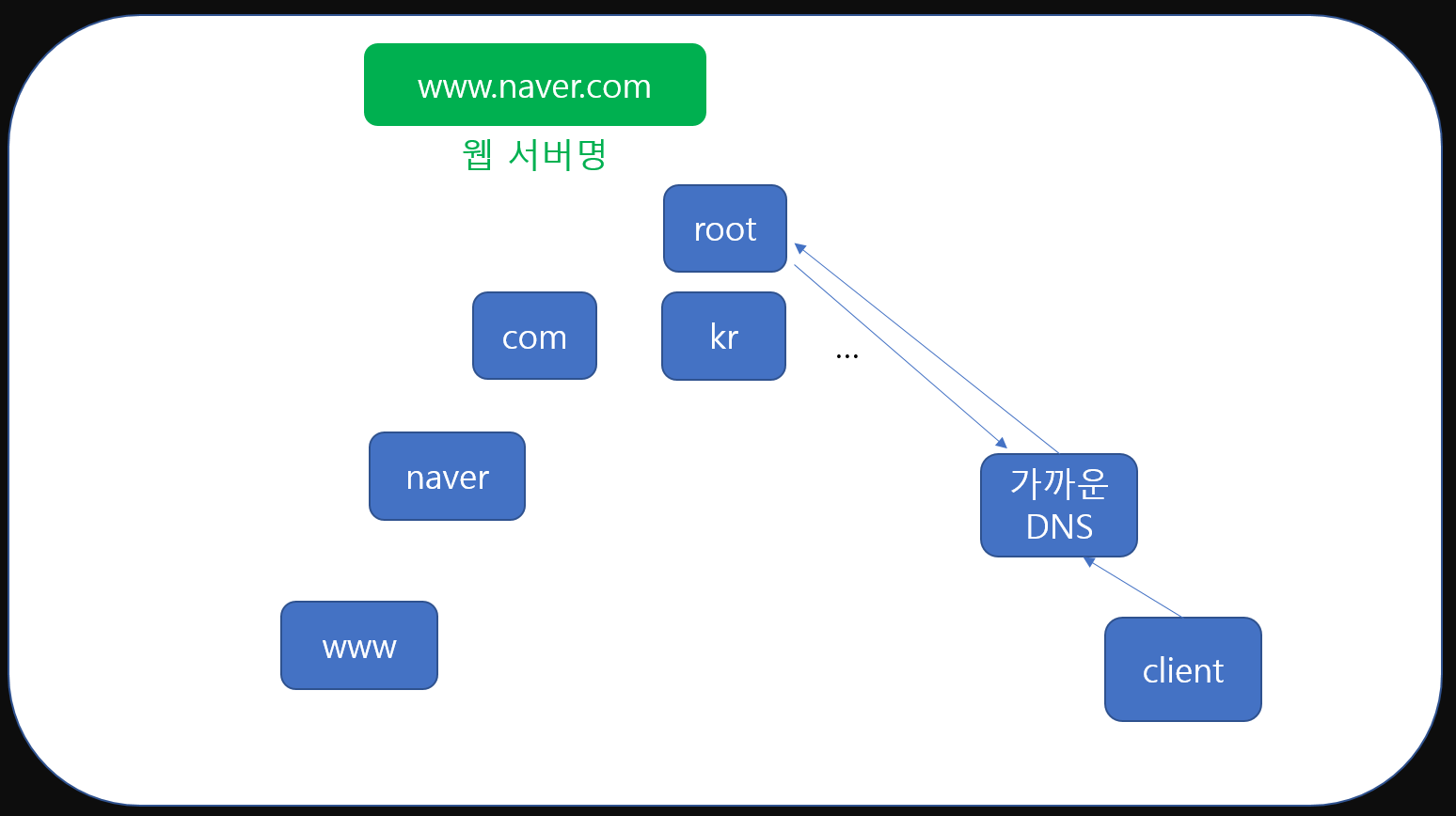 root DNS는 ip는 모르지만 www.naver.com을 보고 자신이 알고 있는 com정보를 가진 DNS정보를 응답해줍니다.
root DNS는 ip는 모르지만 www.naver.com을 보고 자신이 알고 있는 com정보를 가진 DNS정보를 응답해줍니다.
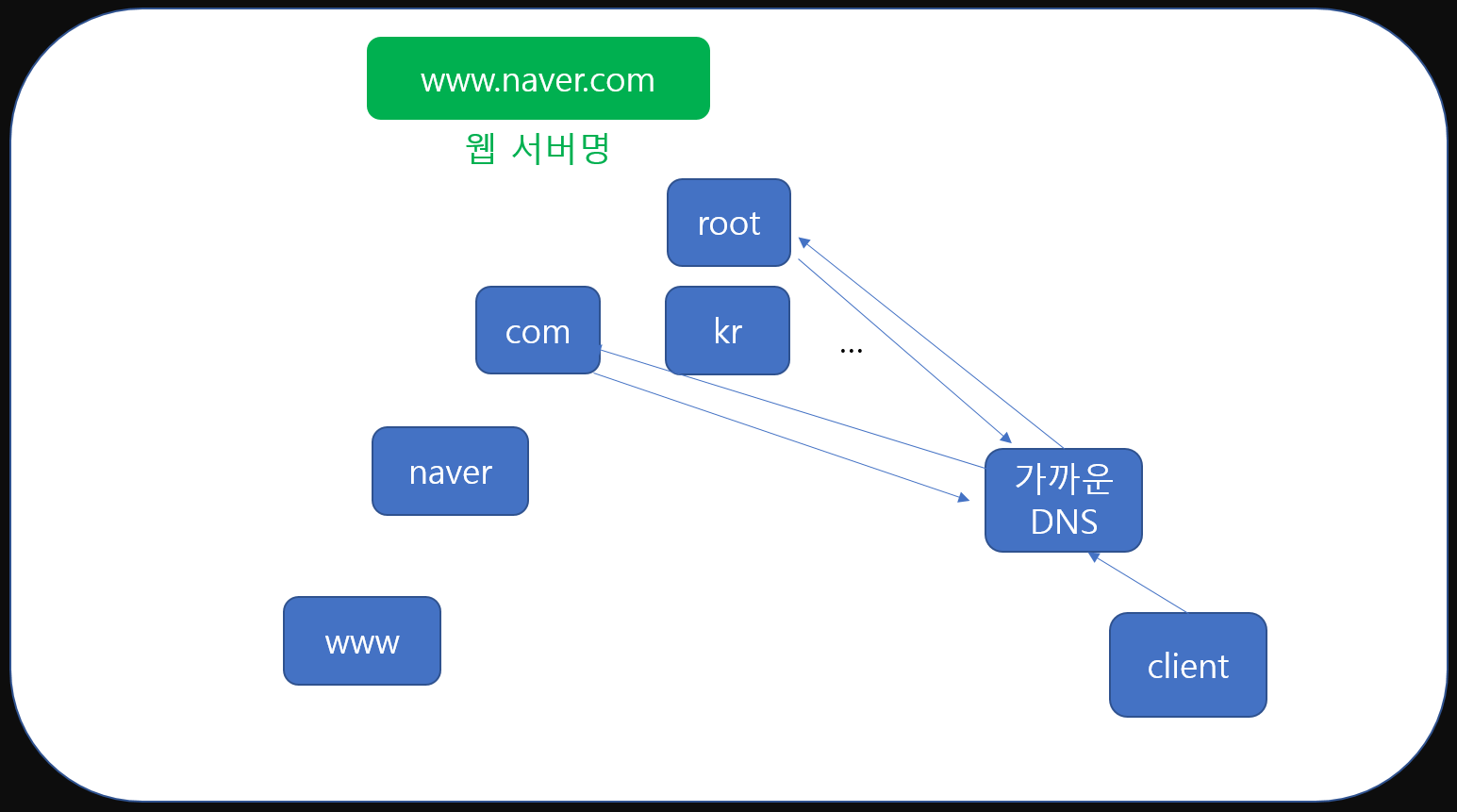 그럼 DNS는 다시 com정보를 가진 DNS에 ip정보를 요청하는거죠. com역시 www.naver.com정보가 없을 수 있습니다. 이럴 경우 com DNS는 대신 naver.com의 정보를 알고 있는 DNS를 응답으로 알려줍니다.
그럼 DNS는 다시 com정보를 가진 DNS에 ip정보를 요청하는거죠. com역시 www.naver.com정보가 없을 수 있습니다. 이럴 경우 com DNS는 대신 naver.com의 정보를 알고 있는 DNS를 응답으로 알려줍니다.
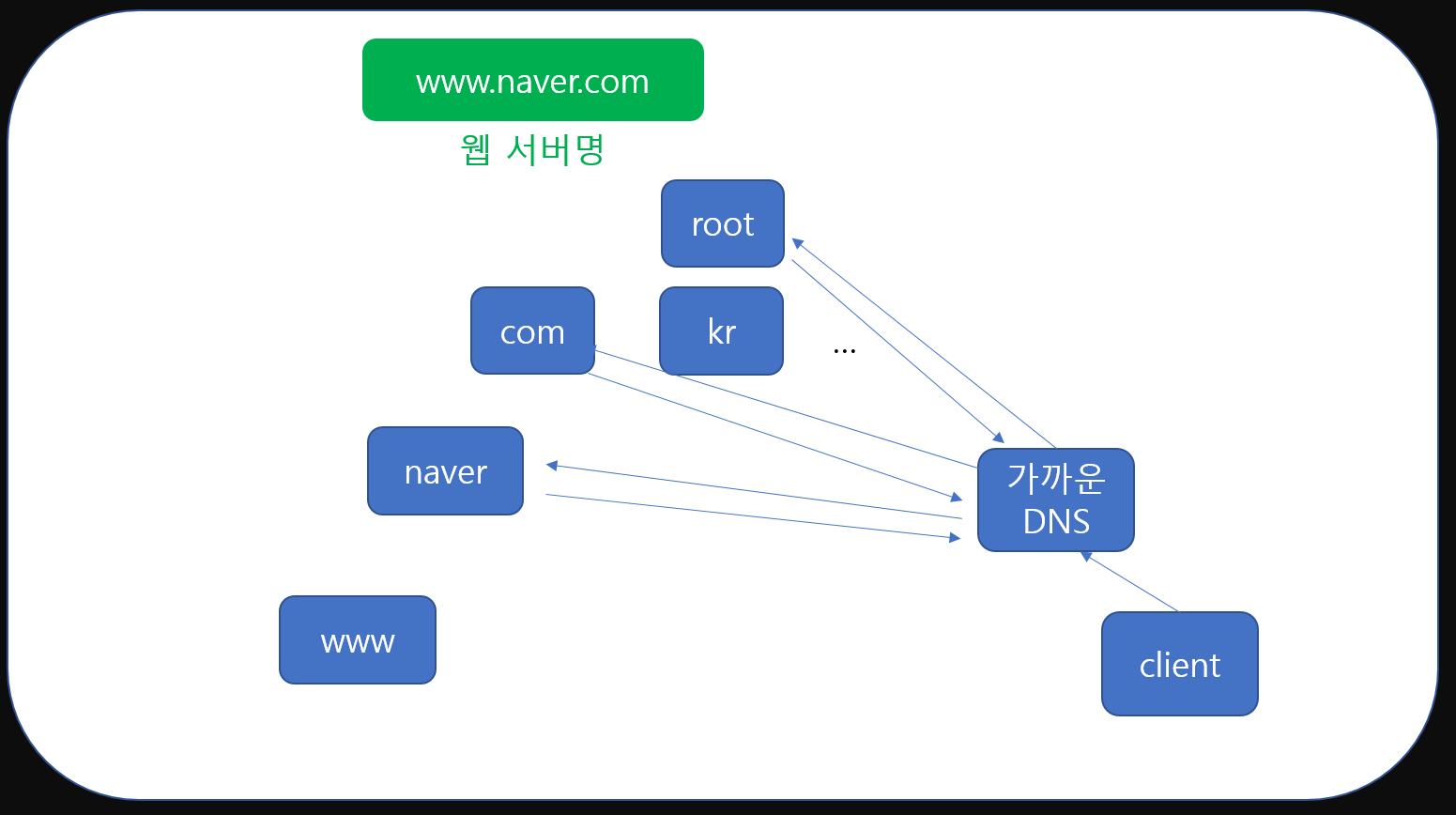 이런 식으로 같은 과정이 반복되는 것이죠. 도메인이 아무리 많더라도, 계층구조로 관리되고 있기 때문에 몇 번의 통신을 진행하면 우리는 원하는 DNS의 ip정보를 가진 DNS에 접근할 수 있게 됩니다.
이런 식으로 같은 과정이 반복되는 것이죠. 도메인이 아무리 많더라도, 계층구조로 관리되고 있기 때문에 몇 번의 통신을 진행하면 우리는 원하는 DNS의 ip정보를 가진 DNS에 접근할 수 있게 됩니다.
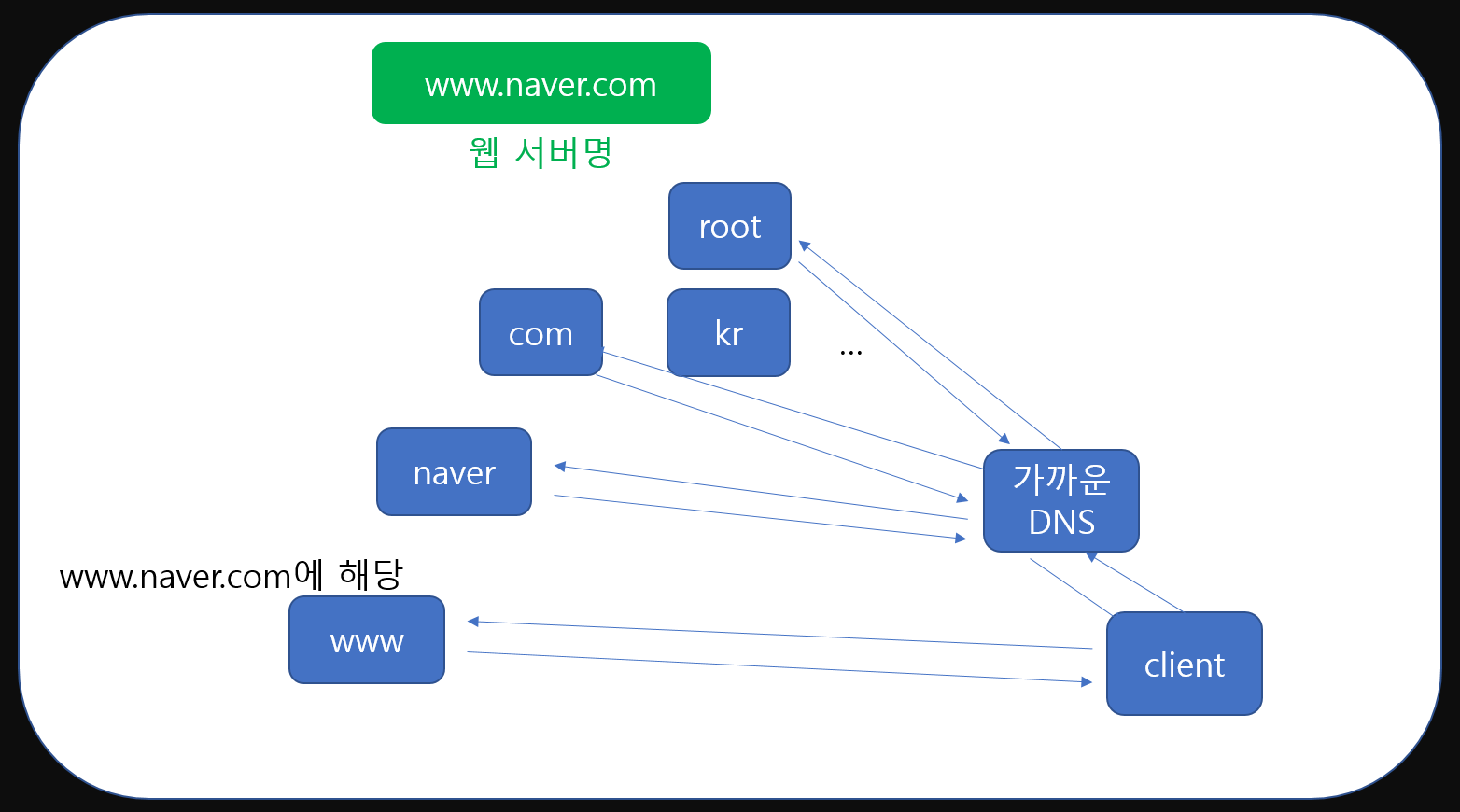 이제 마지막 DNS에서 ip를 전달 받은 가까운 DNS는 client에게 ip정보를 응답해줍니다. 그럼 client는 그 ip를 이용해 www.naver.com에 해당하는 서버와 통신을 할 수 있게 되는 것이죠. DNS는 이렇게 많은 서버가 연동하여 동작합니다.
이제 마지막 DNS에서 ip를 전달 받은 가까운 DNS는 client에게 ip정보를 응답해줍니다. 그럼 client는 그 ip를 이용해 www.naver.com에 해당하는 서버와 통신을 할 수 있게 되는 것이죠. DNS는 이렇게 많은 서버가 연동하여 동작합니다.
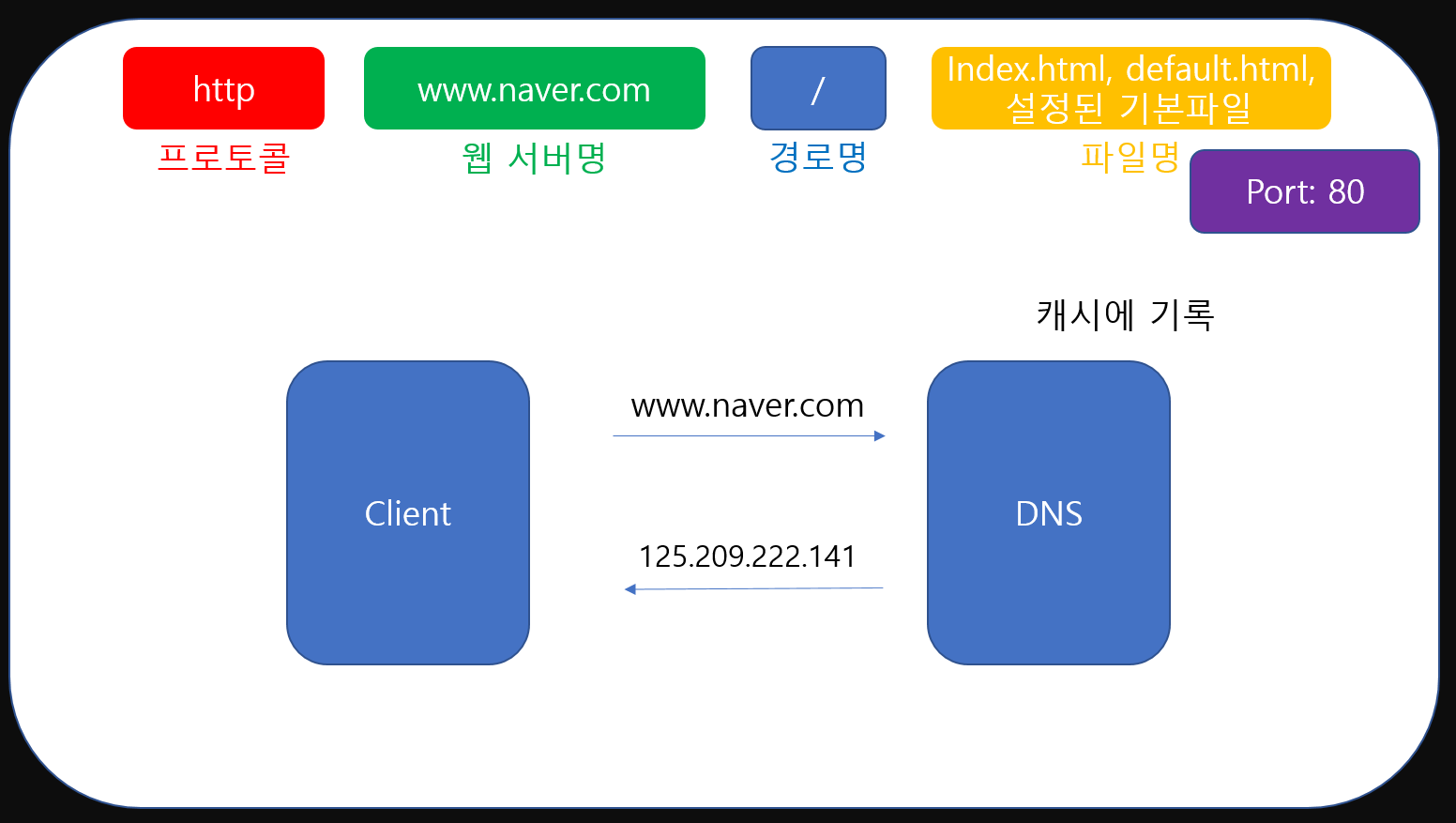 또한 DNS는 새로운 정보를 캐시에 기록할 수 있습니다. 위에서 살펴본 것 처럼 알지 못하는 도메인의 ip를 알아내기 위해선 전 세계의 DNS서버와 연동해야 하는데 비용이 들기 때문이죠. DNS는 캐시서버를 이용해 성능을 향상시킵니다.
또한 DNS는 새로운 정보를 캐시에 기록할 수 있습니다. 위에서 살펴본 것 처럼 알지 못하는 도메인의 ip를 알아내기 위해선 전 세계의 DNS서버와 연동해야 하는데 비용이 들기 때문이죠. DNS는 캐시서버를 이용해 성능을 향상시킵니다.
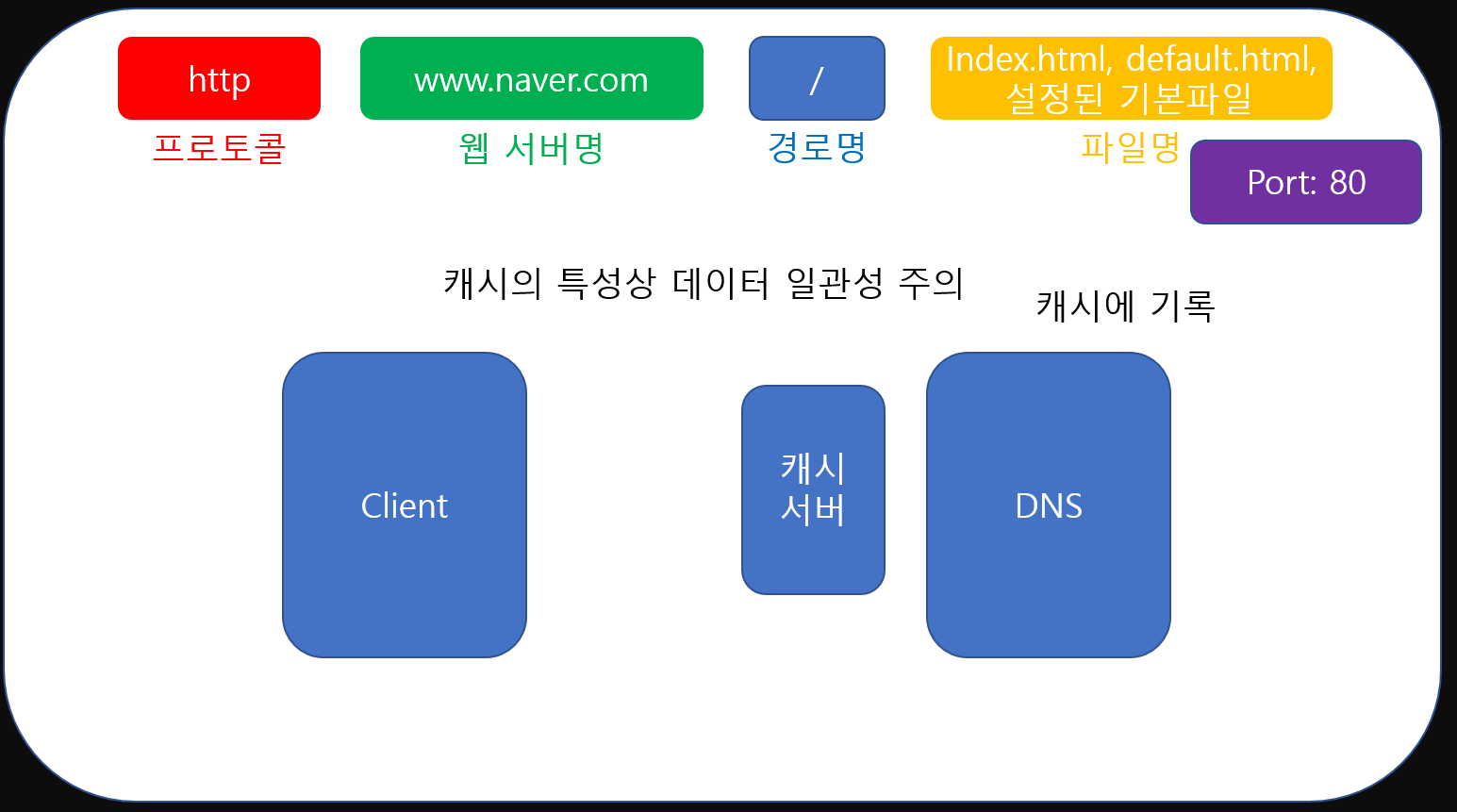 물론 캐시라는 특성상 실제 데이터와 일치하지 않을 가능성이 있죠. 따라서 일정 주기를 따르며 폐기하거나 업데이트 하는 방식을 사용합니다.
물론 캐시라는 특성상 실제 데이터와 일치하지 않을 가능성이 있죠. 따라서 일정 주기를 따르며 폐기하거나 업데이트 하는 방식을 사용합니다.
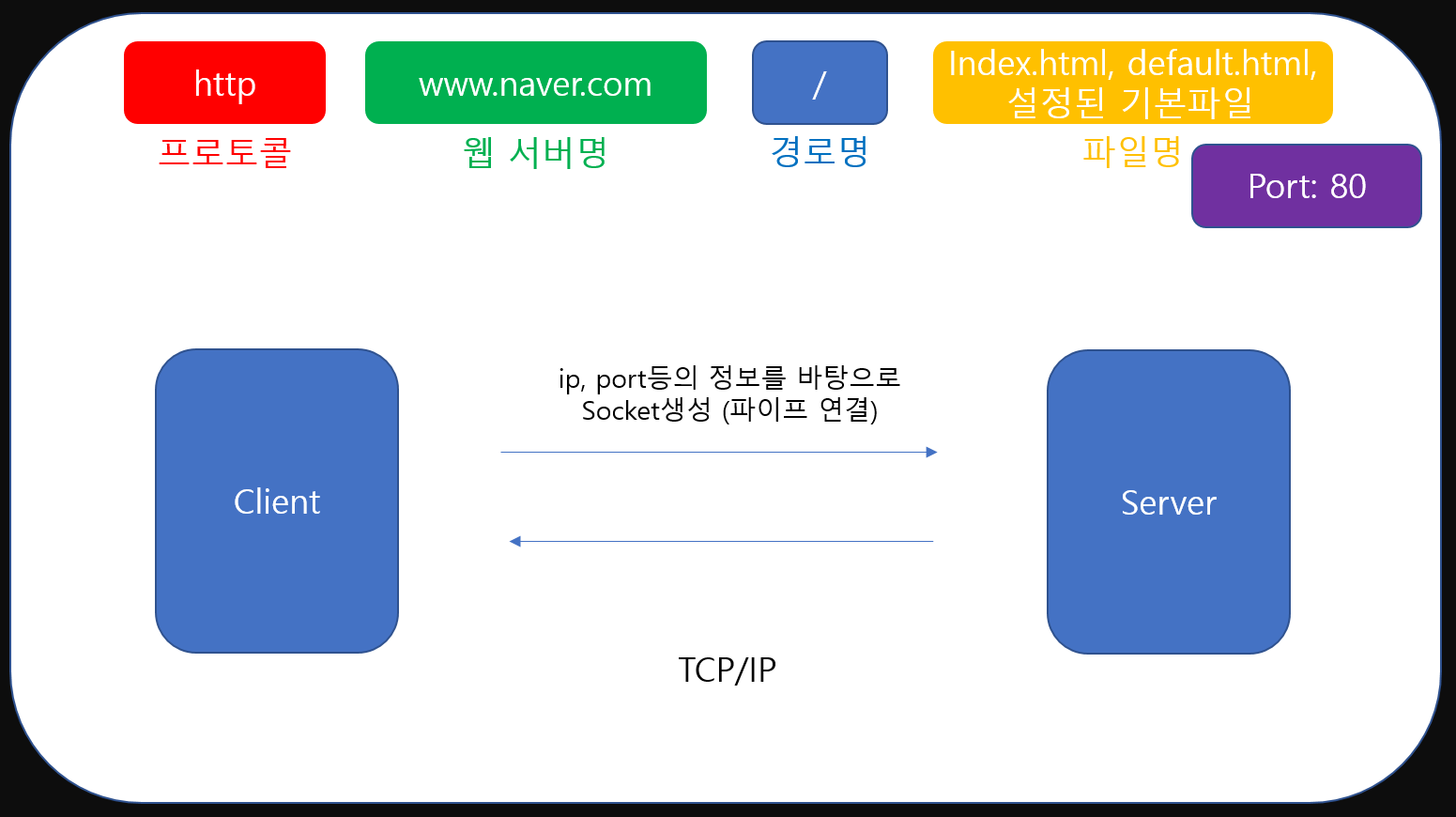 이제 우리는 원하는 서버의 ip주소를 알아냈습니다. 이 서버에 HTTP Message를 전달하고 HTTP Message를 응답 받는 것이 우리의 목표입니다.
이제 우리는 원하는 서버의 ip주소를 알아냈습니다. 이 서버에 HTTP Message를 전달하고 HTTP Message를 응답 받는 것이 우리의 목표입니다.
그런데 이런 메시지를 전달할때는 일종의 네트워크 규칙이 필요합니다. 다음 시간에 우리는 TCP/IP라는 규칙을 알아보겠습니다.

