[논문요약] Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting (2021)
데이터 사이언스 이론 노트
목록 보기
2/6

Deep Dive into the Informer Model for Long Sequence Time-Series Forecasting
Introduction to Time Series Forecasting
- Definition & Importance: Predicting future points in a series based on historical data is crucial for decision-making in finance, meteorology, and resource management.
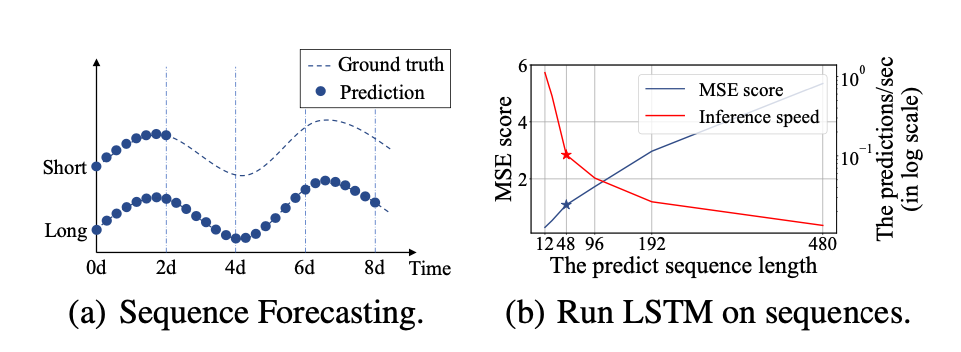
- Challenges in LSTF: Traditional models struggle with long sequence data, leading to a trade-off between sequence length and accuracy.
Traditional Models and Their Limitations
- ARIMA: Handles short, univariate series but lacks in complex patterns and multivariate data.
- LSTM: Better for sequences but struggles with very long sequences and computational power.
The Informer Model: A Paradigm Shift
- Overview: Designed to address the limitations of traditional forecasting models by efficiently processing long data sequences with high accuracy.
- Key Innovations:
- ProbSparse Self-attention: Focuses on the most informative parts of the data, reducing computational load.
- Query Sparsity Measurement: Quantifies the significance of queries, allowing effective prioritization of computational resources.
- Distilling Operation: Compresses the input sequence while retaining critical information, enhancing memory efficiency.
Technical Details of the Informer Model
- ProbSparse Self-attention Mechanism:
- Selective Attention: Targets the most impactful elements, reducing complexity from O(n^2) to O(nlogn).
- Impact on Performance: Faster computation and less memory usage without sacrificing forecast quality.
- Query Sparsity Measurement:
- Functionality: Measures the probability of each query's importance for selective attention.
- Benefits: Ensures attention is distributed effectively, focusing on influential data points.
- Distilling Operation:
- Process: Extracts and condenses relevant information into a shorter sequence.
- Advantages: Handles longer sequences by reducing input length without losing essential information.
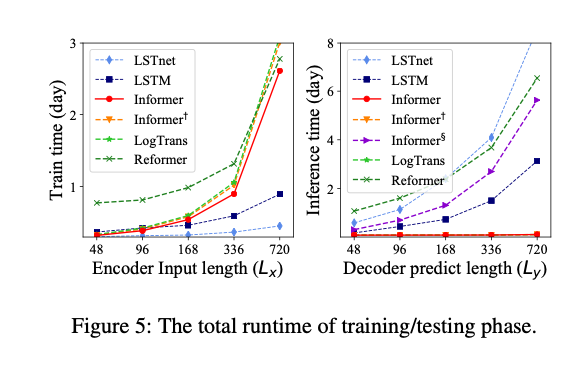
Experiments and Comparative Analysis
- Datasets Used: Tested on datasets like electricity consumption, temperature readings, and weather data.
- Performance Metrics:
- MSE and MAE: Used to evaluate the accuracy, with the Informer showing lower errors.
- Prediction Windows: Consistent performance across different sizes, showcasing robustness.
Practical Implications and Open Source Contribution
- Real-World Applications: Suitable for complex forecasting tasks in various industries due to efficiency and accuracy.
- Open Source Software: Source code available on GitHub for community use and contribution.
Discussion and Future Directions
- Model Complexity vs. Usability: Balancing the power of the Informer with its complexity in understanding and deployment.
- Extension to Other Domains: Applying Informer principles to other machine learning and data analysis areas.
Conclusion
The Informer model represents a significant advancement in time series forecasting, opening new possibilities for large-scale data environments.
