타전공 대학원생의 데이터 직무 취업 도전기
1.[제로베이스 데이터 스쿨] OT_230703

대학원을 졸업하고 백수와 취준생의 기로에 선 상태에서 만난 제로베이스 데이터 스쿨.꽤나 상세하게 설명되어 있는 커리큘럼이 다른 어디서 본 프로그램보다 더 알차다고 느껴져서, 며칠 고민 안하고 바로 등록을 해버렸다. 오티 자료를 쭉 보다보니, 커리큘럼이 물샐 틈이 없다.
2.[파이썬 기초문법] 변수, 자료형, 입출력, 연산자, 조건문 등 230704

<학습내용 요약>개요PyCharm변수자료형데이터 입출력format()과 형식문자연산자조건식, 조건문워낙 예전부터 파이썬을 건드려 봤다가 한눈 판 시간이 많아서 파이썬 강의 초반부는 큰 무리없이 복습하는 개념으로 공부를 진행했다. 아래는 개념적인, 또는 실용적인 부
3.[파이썬 기초문법] 연습문제

연산자거스름돈 계산기연습문제 코드를 아래와 같이 조금 수정했음.1) 돈이 모자라면 잔돈 파트를 출력하지 않고 '모자란 돈' 금액을 출력.2) {:,} .format() 함수를 사용해서 화폐단위 출력.방법1(수업에서 배운 방법)이 더 간단해 보이기는 하는데, 만약 여러
4.[파이썬 기초문법] 연습문제2 (fin)
강의자료에 남아있는 몇 가지 반복문 연습문제를 더 풀어봤다. 1\. 1부터 100까지 숫자 중 10의 자리와 1의 자리 숫자의 홀짝 판단다양한 숫자 조합 출력별모양 만들기(개인적으로 제일 까다로웠다)버스 시간표맞물린 톱니바퀴<후기>파이썬의 가장 기초적인 문법이라고
5.[파이썬 기초문법] List Comprehension
리스트 컴프리헨션은 파이썬에서 리스트를 간결하고 표현적으로 생성하는 방법입니다. 이는 기존의 이터러블(리스트, 튜플, 문자열 등)의 각 요소에 표현식을 적용하여 새로운 리스트를 생성하며, 필요에 따라 조건을 이용하여 요소를 필터링할 수 있습니다. 이를 통해 한 줄의 코
6.[파이썬 중급] 사용자 함수, 모듈, 패키지, 객체지향 프로그래밍 외
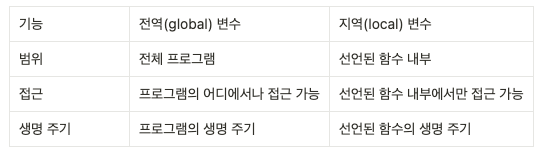
함수란input → calculation → output내장함수 vs 사용자함수내장함수 예시numbers.sort()numbers.reverse()numbers.clear()함수의 명명은 동사형으로 알아보기 쉽게 (code convention)선언(define)만 하면
7.[파이썬 중급] 얕은복사/깊은복사, 클래스 상속, 생성자, 다중 상속/오버라이딩, 추상클래스, 예외 처리 외
21\_얕은복사(shallow copy)와 깊은복사(deep copy)얕은복사란, 객체 주소를 복사하는 것. 객체 자체의 복사는 아님.어제 공부한 레퍼런스 변수; 2개의 변수는 같은 메모리 주소를 가지게 됨깊은복사란, 객체 자체를 복사하여 또 하나의 객체가 생성.2개의
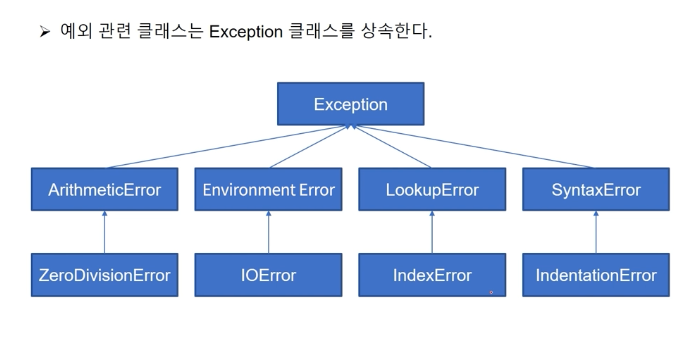
8.[파이썬 중급문법 fin] 사용자 Exception class, 텍스트 파일 쓰기/읽기/열기, with ~ as, writelines(), readlines(), readline()
9.[파이썬 중급] 연습문제1
40\_함수 1: 계산기41\_연습문제 함수2: 거리 계산43\_연습문제 함수4: 재귀함수를 이용한 팩토리얼 계산단리/복리 계산기044\_함수 5등차수열045\_함수 연습문제 6등비수열46\_모듈 연습문제1Pass or Fail실행코드49\_모듈 연습문제4: 순열(pe
10.[파이썬] 클래스에서 'self'는 무엇인가
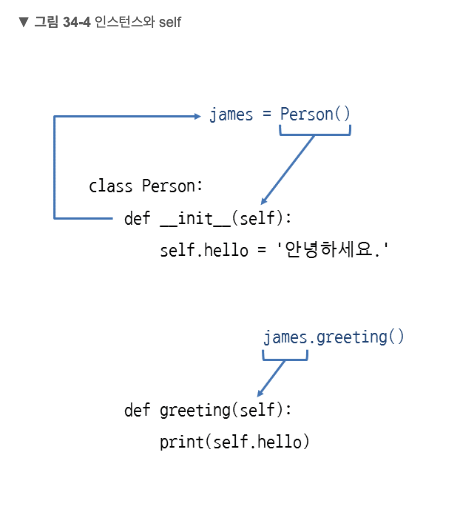
https://www.youtube.com/watch?v=oaiQ5hYKHTE(위 영상을 기반으로 작성한 요약 글입니다)파이썬 초보자로서 클래스와 메소드의 개념 중 하나인 'self' 매개변수가 이해하기 어려웠습니다. 위 링크의 영상을 참고하여 self 개념에
11.[파이썬 연습문제] 피보나치 수열
12.[파이썬 자료구조] Intro
<파이썬의 자료구조>1\. 리스트(list)2\. 튜플(tuple)3\. 집합(set)4\. 딕셔너리(dictionary)5\. 문자열(string)파이썬에서 데이터 구조(data structure)란 데이터를 특정 형식으로 구성하고 저장하는 방법으로, 데이터를
13.[파이썬 자료구조] 리스트 List
파이썬에서 리스트는 특정 순서로 요소들을 저장하는 다재다능하고 기본적인 데이터 구조입니다. 리스트는 가변적이며, 생성된 후에도 내용을 수정할 수 있습니다. 이러한 유연성과 사용 편의성으로 인해 리스트는 파이썬에서 가장 자주 사용되는 데이터 구조 중 하나입니다.파이썬의
14.[파이썬 자료구조] 튜플 Tuple
파이썬에서 튜플은 순서가 있는, 변경이 불가능한 요소들의 모음입니다. 튜플은 리스트와 매우 유사하지만, 튜플은 한 번 생성되면 수정할 수 없다는 점이 다릅니다. 이러한 불변성은 데이터의 무결성을 보장하고 실수로 발생하는 변경을 방지하는데 유용합니다.튜플은 괄호 ()를
15.[파이썬 자료구조] 딕셔너리 Dictionary
파이썬에서 딕셔너리는 키-값 쌍으로 데이터를 저장하고 조직화하는 다재다능하고 강력한 데이터 구조입니다. 딕셔너리의 각 요소는 고유한 키와 해당하는 값을 가집니다. 키는 딕셔너리 내에서 고유해야 하며, 해당하는 값을 효율적으로 접근하는 데 사용됩니다.다음은 예제 코드와
16.[알고리즘 기초] Why 알고리즘?
알고리즘은 특정한 문제를 해결하거나 특정 작업을 수행하기 위해 사용되는 단계별 절차 또는 규칙의 집합입니다. 알고리즘은 입력을 받아 처리하고 출력을 생성하는 잘 정의되고 명료한 명령어의 순서입니다. 알고리즘은 자연어, 의사코드 또는 프로그래밍 언어로 표현될 수 있습니다
17.[알고리즘 기초] 선형 검색 Linear Search
선형 검색 알고리즘은 간단한 검색 알고리즘으로, 목표 요소를 리스트나 배열에서 순차적으로 확인합니다. 시작부터 리스트의 각 요소를 확인하며 목표 요소를 찾거나 리스트의 끝에 도달할 때까지 계속됩니다. 알고리즘은 리스트의 처음부터 시작하여 각 요소를 목표 요소와 비교합니
18.[알고리즘 기초] 이진 검색 Binary Search
이진 탐색은 정렬된 리스트나 배열에서 목표 요소를 효율적으로 찾기 위해 사용되는 검색 알고리즘입니다. 이 알고리즘은 검색 간격을 반으로 계속 나누어가며 중간 요소를 목표와 비교합니다. 만약 중간 요소가 목표와 같다면 검색은 성공적으로 끝나고, 알고리즘은 목표 요소의 인
19.[알고리즘 기초] 버블 정렬 Bubble Sorting
버블 정렬 알고리즘은 간단한 정렬 알고리즘으로, 반복적으로 정렬할 리스트를 훑어가면서 인접한 요소들을 비교하고, 만약 순서가 잘못되어 있다면 이를 교환합니다. 이 알고리즘은 각 패스마다 더 작은 요소들이 리스트의 위쪽으로 이동하는 모습이 흡사 거품이 일어나는 모습과 흡
20.[알고리즘 기초] 삽입 정렬 Insertion Sorting
삽입 정렬 알고리즘은 한 번에 하나의 항목을 추가하여 최종으로 정렬된 배열을 구축하는 간단한 정렬 알고리즘입니다. 이는 입력 리스트를 반복하면서 각 요소를 이미 정렬된 리스트 부분 내에 올바른 위치에 "삽입"하여 작동합니다.삽입 정렬 알고리즘의 단계별 설명은 다음과 같
21.[알고리즘 기초] 최대값/최솟값
리스트에서 최대 숫자를 찾는 알고리즘은 간단합니다. 리스트를 반복하면서 현재까지 찾은 최대 숫자를 추적하는 방식으로 동작합니다. 다음은 Python으로 설명된 알고리즘입니다:변수 maxNum을 리스트의 첫 번째 요소로 초기화합니다.두 번째 요소부터 마지막 요소까지 리스
22.[알고리즘 기초] 최빈값
다음은 숫자 리스트의 최빈값(mode)을 찾는 간단한 알고리즘입니다. 우리는 각 숫자의 등장 횟수를 세는 방식으로 최빈값을 찾을 수 있습니다.아래는 숫자 리스트의 최빈값을 찾기 위한 알고리즘입니다:빈 딕셔너리를 생성하여 각 숫자의 등장 횟수를 저장합니다.숫자 리스트를
23.[알고리즘 기초] 재귀 알고리즘 Recursive Algorithm
재귀 알고리즘은 함수가 자신을 호출하여 원래 문제의 더 작은 버전을 해결하는 알고리즘 접근 방식입니다. 다시 말해, 문제는 원래 문제와 동일한 성질을 가지지만 어떤 면에서는 더 단순한 작은 하위 문제로 분할됩니다. 이 하위 문제 각각은 같은 함수를 호출하여 해결되며,
24.[제로베이스] 데이터 취업 스쿨 팀스터디 노트 1주차
목표:데이터 직무 채용공고 스크랩 후 직무 내용, 요구 역량 정리하기1) 데이터 취업 스쿨에 참여하는 여러분들의 다짐과 입과 계기대학원을 다니며 공부하던 분야에서 박사과정까지 도전하는 것은 저에게 맞지 않는다는 사실을 깨닫고 석사과정을 마친 후 뒤늦게 취업길에 들어섰습
25.[알고리즘 기초] 하노이의 탑 Tower of Hanoi
하노이의 탑은 유명한 수학 퍼즐로, 1883년에 프랑스 수학자 에두아르 루카스에 의해 발명되었으며, 재귀 개념을 설명하는데 자주 사용됩니다. 세 개의 기둥(탑)과 서로 다른 크기의 n개의 원판들로 이루어져 있습니다. 초기 상태에서는 원판들이 크기가 감소하는 순서로 기둥
26.[알고리즘 기초] 병합 정렬 Merge Sort
병합 정렬(merge sort)은 입력된 요소들의 리스트를 정렬하는데 사용되는 인기있고 효율적인 정렬 알고리즘입니다. 이 알고리즘은 분할 정복(divide-and-conquer) 접근 방식을 사용하여 입력 리스트를 두 부분으로 나누고, 각 부분을 재귀적으로 정렬한 후,
27.[알고리즘 기초] 퀵 정렬 Quick Sort
QuickSort(퀵 정렬)는 배열 또는 리스트를 효율적으로 정렬하기 위해 분할 정복(Divide and Conquer) 방식을 사용하는 널리 사용되는 정렬 알고리즘입니다. 이 알고리즘은 배열에서 피벗(pivot) 요소를 선택하고, 다른 요소들을 피벗과 비교하여 두 개
28.[pandas 기초] Series 데이터 형식
시리즈(Series)는 1차원의 레이블이 지정된 배열로, 정수, 실수, 문자열 등 어떤 종류의 데이터든지 보유할 수 있습니다. 그러나 중요한 점은 시리즈의 각 요소는 동일한 데이터 타입이어야 하며, 판다스가 이를 강제하여 일관성과 효율적인 데이터 처리를 보장합니다.예제
29.[pandas 기초] 시간 데이터 생성하기 date_range()
판다스에서 daterange()는 균등하게 간격을 두고 날짜 또는 시간 기간을 포함하는 날짜-시간 인덱스를 생성하는 강력한 함수입니다. 주로 시계열 데이터 분석을 위해 날짜 시퀀스를 생성하는 데 사용됩니다. daterange() 함수는 다양한 매개변수 조합과 함께 사용
30.[pandas 기초] DataFrame
판다스(Pandas)에서 데이터프레임(DataFrame)은 스프레드시트나 SQL 테이블과 유사한 2차원 표 형태의 데이터 구조입니다. 이는 파이썬의 판다스 라이브러리에서 제공하는 핵심 데이터 구조 중 하나로, 데이터를 유연하고 효율적으로 저장하고 조작할 수 있도록 합니
31.[pandas 기초] loc(), iloc()를 활용한 색인법
판다스에서 loc() 메서드와 iloc() 메서드는 데이터프레임(DataFrame)에서 데이터를 선택하고 접근하는데 사용되는 방법입니다. 이들은 행과 열의 라벨(loc()) 또는 정수 위치(iloc())를 기반으로 특정 데이터를 가져올 수 있도록 해줍니다. 각 메서드에
32.[numpy 기초] np.linspace와 np.arange의 차이(번역)
Numpy 기초를 공부하면서 linspace와 arange 함수가 헷갈려서 이를 잘 정리해준 Statology의 영문글을 기계 번역하여 포스팅합니다. (원본: https://www.statology.org/numpy-linspace-vs-arange/)NumP
33.데이터 사이언스에서 API란?
파이썬을 활용한 데이터 분석을 공부하면서 처음으로 API (Application Programming Interface)를 활용해 데이터에 접근하는 방법을 연습해봤다. 구체적으로는 Google Maps API를 활용해 서울에 위치한 약 30개의 경찰서의 주소를 추출하는
34.[BeautifulSoup] find 함수
Beautiful Soup은 HTML 및 XML 문서를 파싱하고 웹 스크래핑하는 데 사용되는 파이썬 라이브러리다. 이 라이브러리는 웹사이트에서 데이터를 추출하고, 복잡한 HTML 코드를 처리하며, 웹 페이지의 구조를 효과적으로 탐색하는 데 널리 활용된다. Beautif
35.[BeautifulSoup] find_all() 함수
Beautiful Soup의 find_all() 메서드는 파싱된 문서 내에서 특정한 HTML 또는 XML 요소의 모든 발생을 검색하는 데 사용된다. 이는 지정한 조건을 충족하는 모든 일치하는 요소의 리스트(list)를 반환한다. 이 메서드는 동일한 태그 이름, 속성 또
36.[Beautiful Soup] Requests 모듈을 이용한 HTML 스크래핑
스크래핑에 흔히 사용되는 Requests 모듈과 BeautifulSoup을 사용해 HTML 데이터를 불러오는 연습을 해보았다. Python의 requests 모듈은 웹 리소스와 상호작용하기 위해 HTTP 요청을 보내는 데 사용되는 편리한 라이브러리다.1\. 설치Requ
37.Selenium과 BeautifulSoup를 함께 사용하기
동적 웹사이트와 같이 BeautifulSoup만을 사용해서는 접근 불가능한 컨텐츠가 있을 때가 꽤나 있다. 예를 들어, 특정 내용을 검색한 결과를 출력하는 창을 띄우기 위해 다음의 단계를 거쳐야 한다고 가정해보자:1\. 홈페이지에서 검색을 위한 아이콘을 클릭2\. 검색
38.Batch/executemany()/fetchmany() 를 활용한 파이썬-SQL 작업
주피터 노트북에서 MySQL DB와 연동 작업을 하는 과제를 수행 중에 난관에 부딪혔다. 대량의 데이터를 DB에 입력, 혹은 불러오는 과정에서 처리 시간이 상당히 오래걸린다는 것.한줄 한줄 쿼리를 입력하는 연습을 하는 초급자 입장에서는 단순히 반복문을 사용해 inser
39.[opencv] 맥북 카메라 연결하기
40.처음해 본 머신러닝 프로젝트 회고
ㄹ
41.[YOLO] convolutional layer filter와 class number의 관계

'사과'와 '멜론' 2개의 클래스가 존재하는 이미지의 학습을 수행하던 도중, 이런 에러가 떴다.대충 해석해보면 convolutional layer의 필터 개수가 class의 숫자와 상응하지 않는다는 것. 모델을 구성해주는 config 파일을 다시 들여다 봤다.여기가 바