[DL] Important concepts in Optimization
Generalization
일반화.
네트워크의 성능이 Training Dataset의 학습 결과와 비슷하게 나올 것이라고 보장되는 것.
하지만 일반화 성능이 높다고 해서 model accuracy가 높다는 말은 아니다.
그야말로 "일반화"가 잘 되어 있다는 뜻.
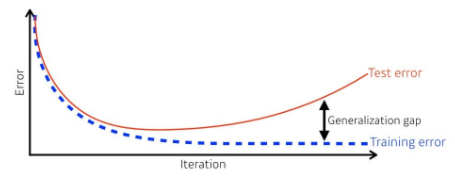
위 사진에서 Generalization gap이 작을수록 일반화가 더 된 모델이라고 할 수 있을 것이다.
Under-fitting & Over-fitting
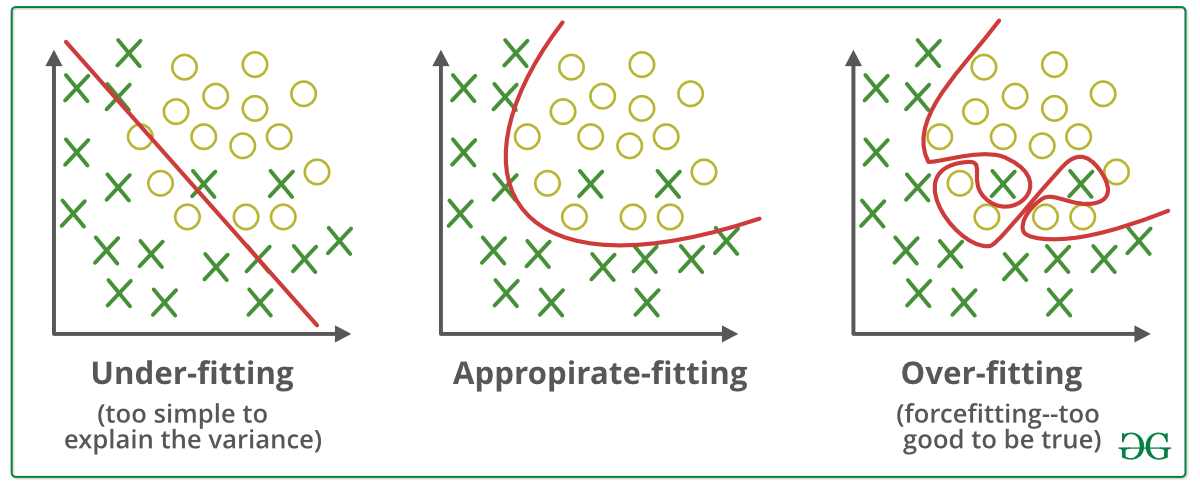
Under fitting
지나친 단순화로 인해 optimize한 결과를 내지 못하는 것.
원인으로는,
- 학습 횟수가 적음
- 데이터 특성에 비해 모델이 너무 간단함
- 데이터 양이 적음
Over fitting
지나치게 training data set에 fit되어서 training data에 대한 정확도는 좋지만 실제 test에서는 에러가 날 수 있는 상황.
일반화가 되지 못했다고 볼 수 있을 것 같다.
과적합 문제를 해결하는 방법으로는,
- Dropout
- Early Stopping
- 정규화 (이건 아직 잘 모르겠음)
- Data Augmentation
- Model Capacity 낮추기 (단순화하기)
Cross validation
이건 조금 더 공부하고 추가하기.
참고하자
적합한 hyper-parameter를 설정하기 위해서 cross validation을 먼저 시행하고, 그 이후에 training을 시작한다고 한다
Bias-Variance trade-off
Bootstrapping
참고
부트스트랩은 Random Sampling을 통해 training data를 늘리는 방법이다.
예를 들어, 어떤 집단에
Bagging & Boosting
여러 개의 모델을 ensemble 하는 것.
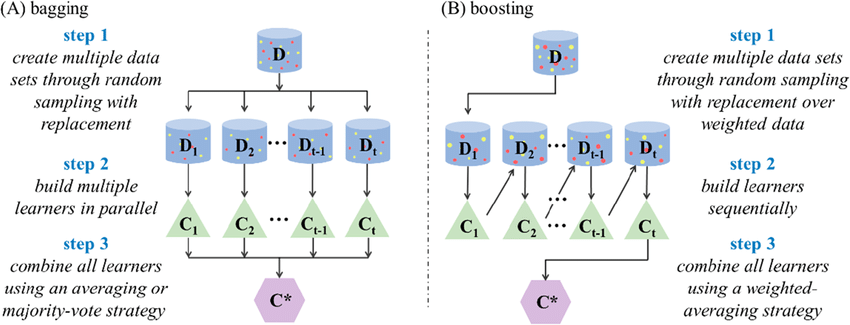

튼튼