
1) 선 그래프
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_excel('시도별 전출입 인구수.xlsx', fillna = 0, header = 0)
df = df.fillna(method = 'ffill')
# null값을 바로 앞 데이터로 채움
mask = (df['전출지별'] == '서울특별시') & (df['전입지별'] != '서울특별시')
# 전출지가 '서울특별시'이고 전입지가 '서울특별시'가 아닌 것
df_seoul = df[mask]
df_seoul = df_seoul.drop(['전출지별'], axis = 1)
# 전출지별 열 drop
df_seoul.rename({'전입지별':'전입지'}, axis = 1, inplace = True)
# 전입지별 열을 전입지로 컬럼명 변경
df_seoul.set_index('전입지', inplace = True)
# 전입지 열을 인덱스로 설정
df_seoul.head()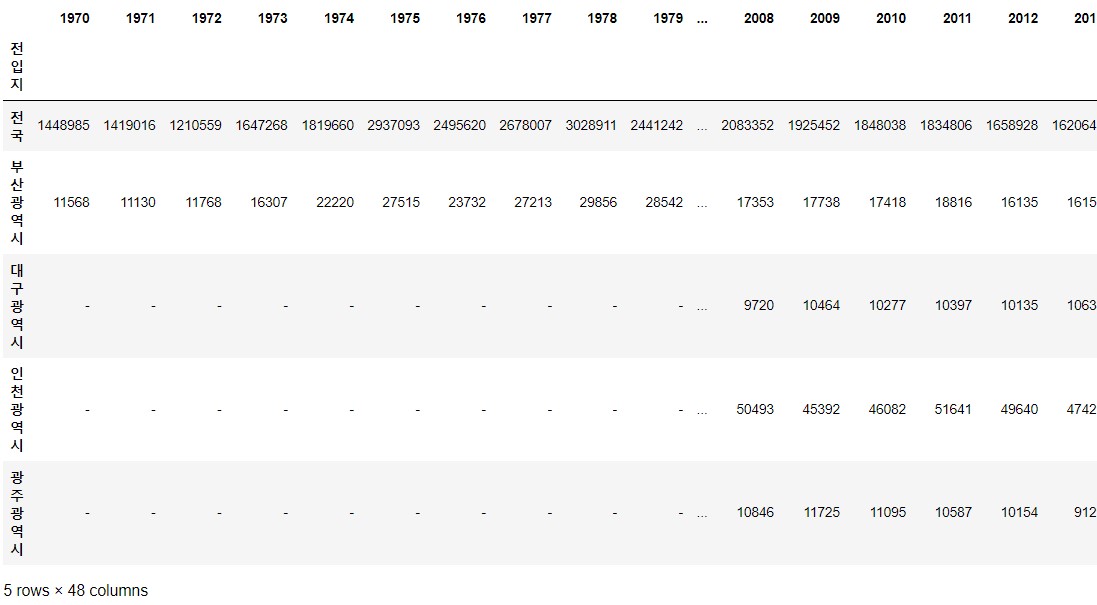
sr_one = df_seoul.loc['경기도']
#전입지가 경기도인 것만 포함하는 sr_one
sr_one.head()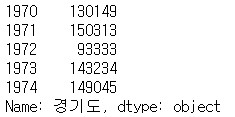
plt.plot(sr_one.index, sr_one.values)
# x축은 년도
# y축은 서울에서 경기도로 이동한 인구 수
# plt.plot(sr_one) 을 해도 같은 그래프가 반환됨
from matplotlib import font_manager, rc
font_path = './malgun.ttf'
font_name = font_manager.FontProperties(fname = font_path).get_name()
rc('font', family = font_name)
# 한글 폰트 깨지는 현상 수정
sr_one = df_seoul.loc['경기도']
plt.plot(sr_one.index, sr_one.values)
plt.title('서울에서 경기도로 이동한 인구 수')
# 차트 제목 추가
plt.xlabel('기간')
# x축 이름 추가
plt.ylabel('이동 인구수')
# y축 이름 추가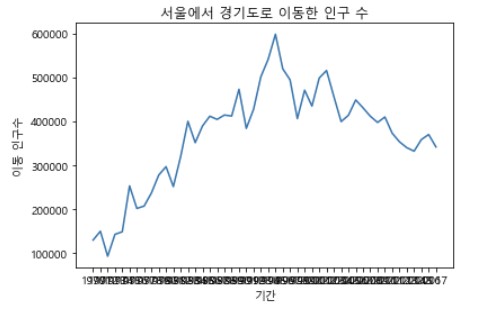
sr_one = df_seoul.loc['경기도']
plt.figure(figsize = (14, 5))
# 그래프 사이즈 지정
plt.xticks(rotation = 'vertical')
# x축 라벨 반시계방향으로 90도 회전
plt.plot(sr_one.index, sr_one.values)
plt.title('서울에서 경기도로 이동한 인구 수')
plt.xlabel('기간')
plt.ylabel('이동 인구수')
plt.legend(labels = ['서울 -> 경기'], loc = 'best')
# 범례 표시
plt.show()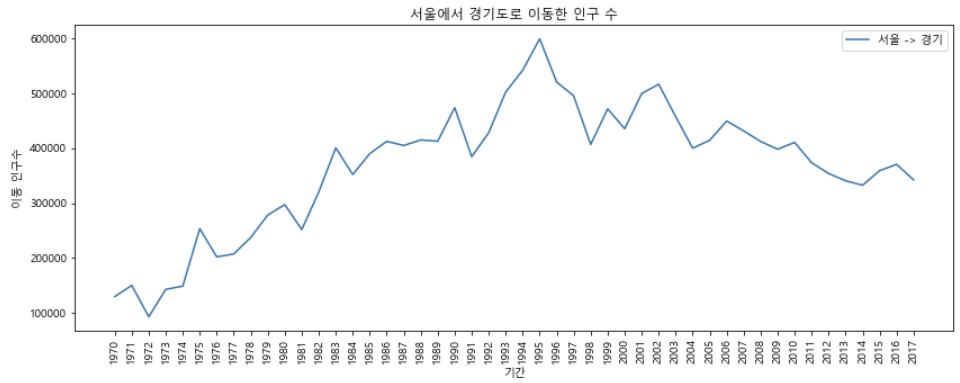
sr_one = df_seoul.loc['경기도']
plt.style.use('ggplot')
# 그래프 스타일 지정
plt.figure(figsize = (14, 5))
plt.xticks(rotation = 'vertical')
plt.plot(sr_one.index, sr_one.values, marker = 'o', markersize = 10)
# 마커 표시 추가
plt.title('서울에서 경기도로 이동한 인구 수')
plt.xlabel('기간')
plt.ylabel('이동 인구수')
plt.legend(labels = ['서울 -> 경기'], loc = 'best', fontsize = 15)
# 범례 표시
plt.show()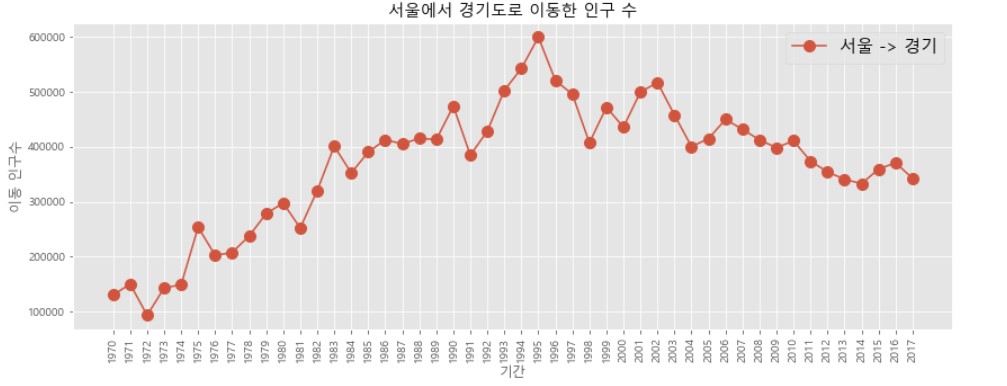
plt.ylim(50000, 800000)
# y 축 최소, 최대 값 지정
plt.annotate('',
xy = (20, 620000), # 화살표의 머리 부분 (끝점)
xytext = (2, 290000), # 화살표의 꼬리 부분 (시작점)
xycoords = 'data', # 좌표체계
arrowprops = dict(arrowstyle = '->', color = 'skyblue', lw = 5), )
# 화살표 추가
plt.annotate('인구 이동 감소 (1995-2017)',
xy = (40, 560000),
rotation = -11,
va = 'baseline', # 글자를 위아래 세로 방향으로 정렬
ha = 'center',
fontsize = 15, ) # 글자를 좌우 가로 방향으로 정렬
# 글자 추가
plt.show()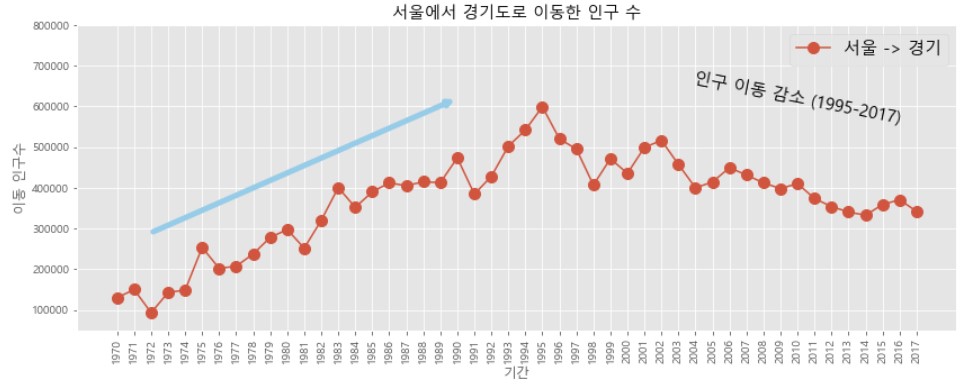
sr_one = df_seoul.loc['경기도']
fig = plt.figure(figsize = (10, 10))
# 그래프 객체 생성 (figure에 2개의 서브 플롯 생성)
ax1 = fig.add_subplot(2,1,1)
ax2 = fig.add_subplot(2,1,2)
ax1.plot(sr_one, 'o', markersize = 10)
ax2.plot(sr_one, marker= 'o', markerfacecolor = 'green', markersize = 10, color = 'olive',
linewidth = 2)
ax1.set_ylim(50000, 800000)
ax2.set_ylim(50000, 800000)
ax1.set_xticklabels(sr_one.index, rotation = 75)
ax2.set_xticklabels(sr_one.index, rotation = 75)
plt.show()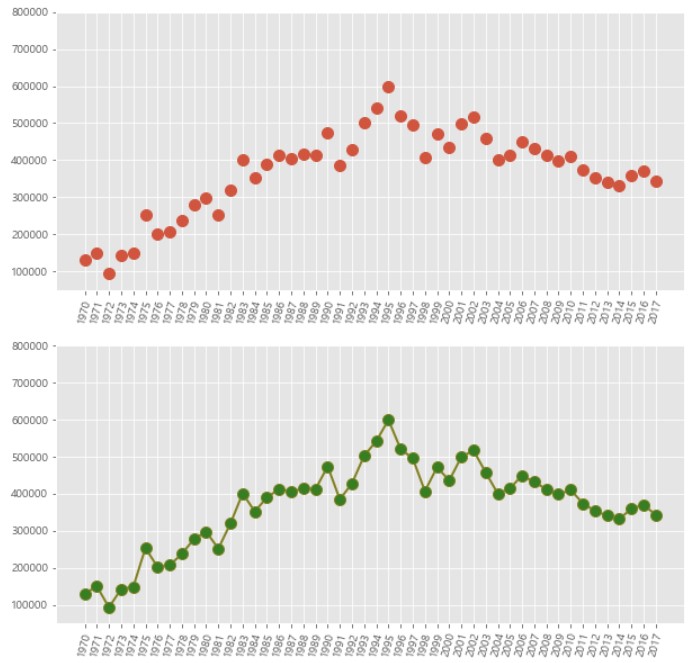
col_years = list(map(str, range(1970, 2018)))
df3 = df_seoul.loc[['충청남도', '경상북도', '강원도'], col_years]
plt.style.use('ggplot')
fig = plt.figure(figsize = (20,5))
ax = fig.add_subplot(1,1,1)
# subplot을 하나 만들고 그 위에 모든 그래프를 그림
ax.plot(col_years, df3.loc['충청남도',:], marker = 'o', markerfacecolor = 'green', markersize = 10,
color = 'olive', linewidth = 2, label='서울 -> 충남')
ax.plot(col_years, df3.loc['경상북도',:], marker = 'o', markerfacecolor = 'red', markersize = 10,
color = 'magenta', linewidth = 2, label='서울 -> 경북')
ax.plot(col_years, df3.loc['강원도',:], marker = 'o', markerfacecolor = 'blue', markersize = 10,
color = 'skyblue', linewidth = 2, label='서울 -> 강원')
ax.legend(loc = 'best')
ax.set_title('서울 -> 충남, 경북, 강원 인구 이동', size = 20)
ax.set_xlabel('기간', size = 12)
ax.set_ylabel('이동 인구수', size = 12)
ax.set_xticklabels(col_years, rotation = 90)
ax.tick_params(axis = "x", labelsize = 10)
ax.tick_params(axis = "y", labelsize = 10)
plt.show()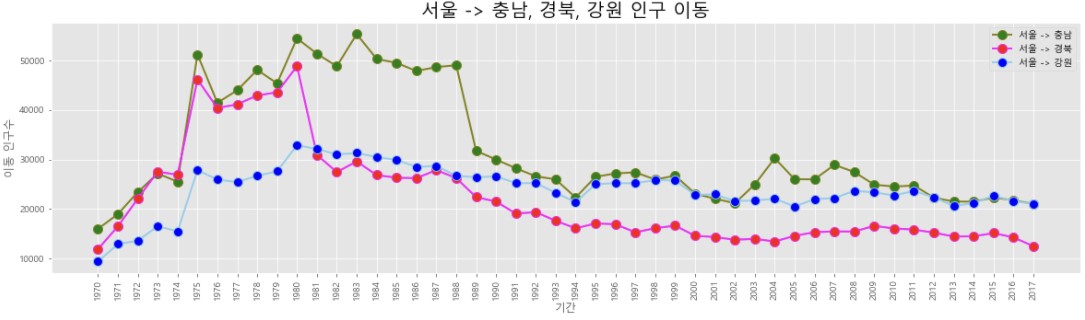
col_years = list(map(str, range(1970, 2018)))
df4 = df_seoul.loc[['충청남도', '경상북도', '강원도', '전라남도'], col_years]
plt.style.use('ggplot')
fig = plt.figure(figsize = (20,10))
ax1 = fig.add_subplot(2,2,1)
ax2 = fig.add_subplot(2,2,2)
ax3 = fig.add_subplot(2,2,3)
ax4 = fig.add_subplot(2,2,4)
# subplot을 4개 만들고 각각의 그래프에 각 도로의 이동을 표현함
ax1.plot(col_years, df4.loc['충청남도',:], marker = 'o', markerfacecolor = 'green', markersize = 10,
color = 'olive', linewidth = 2, label='서울 -> 충남')
ax2.plot(col_years, df4.loc['경상북도',:], marker = 'o', markerfacecolor = 'red', markersize = 10,
color = 'magenta', linewidth = 2, label='서울 -> 경북')
ax3.plot(col_years, df4.loc['강원도',:], marker = 'o', markerfacecolor = 'blue', markersize = 10,
color = 'skyblue', linewidth = 2, label='서울 -> 강원')
ax4.plot(col_years, df4.loc['전라남도',:], marker = 'o', markerfacecolor = 'orange', markersize = 10,
color = 'yellow', linewidth = 2, label='서울 -> 전남')
ax1.legend(loc = 'best')
ax2.legend(loc = 'best')
ax3.legend(loc = 'best')
ax4.legend(loc = 'best')
ax1.set_title('서울 -> 충남 인구 이동', size = 15)
ax2.set_title('서울 -> 경북 인구 이동', size = 15)
ax3.set_title('서울 -> 강원 인구 이동', size = 15)
ax4.set_title('서울 -> 전남 인구 이동', size = 15)
ax1.set_xticklabels(col_years, rotation = 90)
ax2.set_xticklabels(col_years, rotation = 90)
ax3.set_xticklabels(col_years, rotation = 90)
ax4.set_xticklabels(col_years, rotation = 90)
plt.show()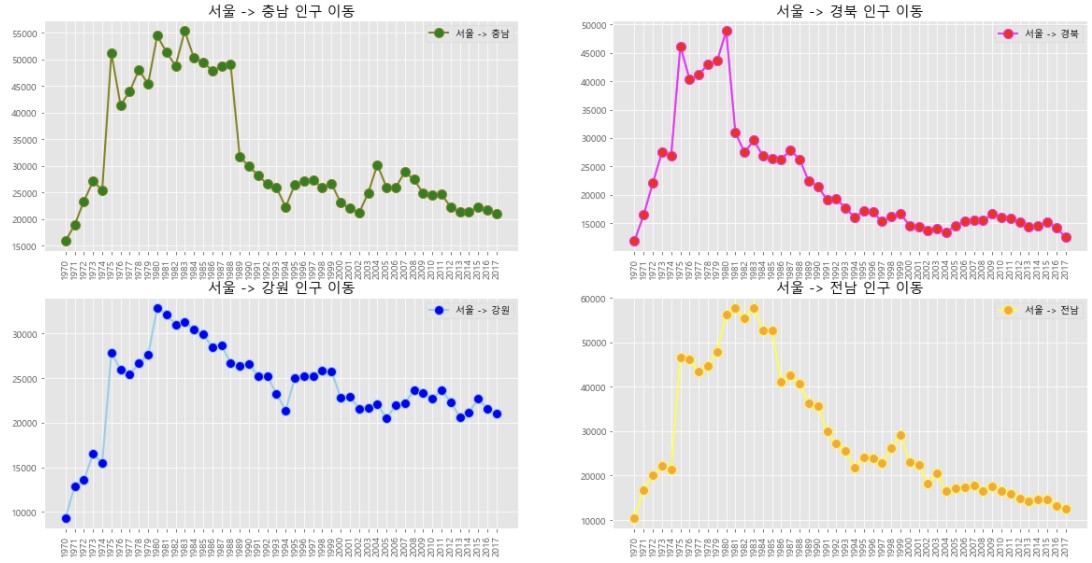
2) 면적 그래프
col_years = list(map(str, range(1970, 2018)))
df4 = df_seoul.loc[['충청남도', '경상북도', '강원도', '전라남도'], col_years]
df4 = df4.transpose()
df4.plot(kind = 'area', stacked = False, alpha = 0.2, figsize = (20,10))
# stacked = True를 하면 '누적'
# 겹친 부분이 잘 보이도록 alpha 값을 0.2로 설정 (기본값은 0.5)
plt.title('서울에서 타시도로의 인구 이동', size = 30)
plt.ylabel('이동 인구 수', size = 20)
plt.xlabel('기간', size = 20)
plt.legend(loc = 'best', fontsize = 15)
plt.show()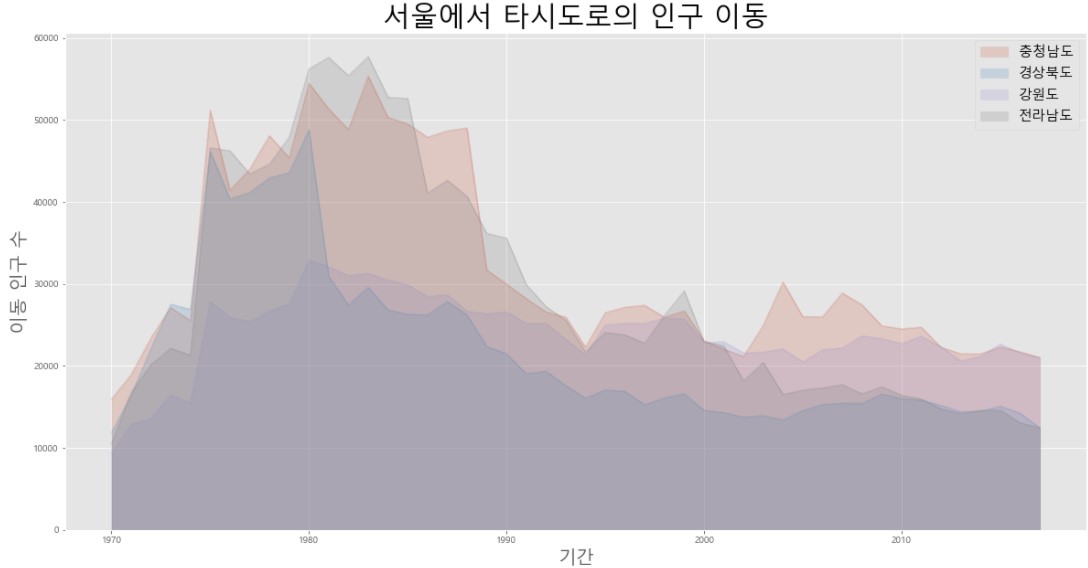
col_years = list(map(str, range(1970, 2018)))
df5 = df_seoul.loc[['충청남도', '경상북도', '강원도', '전라남도'], col_years]
df5 = df5.transpose()
df5.plot(kind = 'area', stacked = True, alpha = 0.2, figsize = (20,10))
# stacked = True를 하면 '누적'
# 겹친 부분이 잘 보이도록 alpha 값을 0.2로 설정 (기본값은 0.5)
plt.title('서울에서 타시도로의 인구 이동', size = 30)
plt.ylabel('이동 인구 수', size = 20)
plt.xlabel('기간', size = 20)
plt.legend(loc = 'best', fontsize = 15)
plt.show()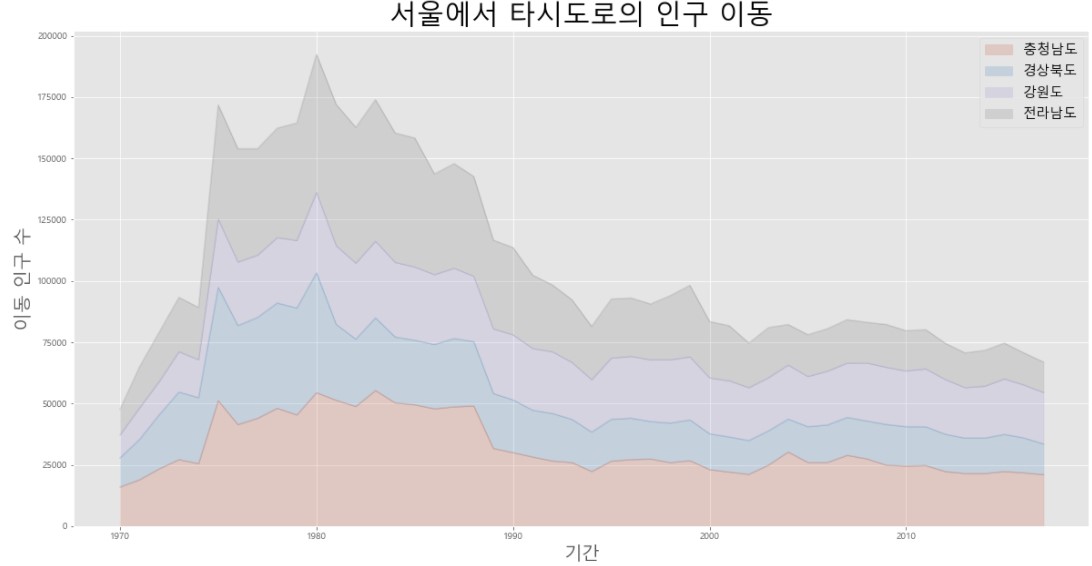
col_years = list(map(str, range(1970, 2018)))
df5 = df_seoul.loc[['충청남도', '경상북도', '강원도', '전라남도'], col_years]
df5 = df5.transpose()
ax = df5.plot(kind = 'area', stacked = True, alpha = 0.2, figsize = (20,10))
# stacked = True를 하면 '누적'
# 겹친 부분이 잘 보이도록 alpha 값을 0.2로 설정 (기본값은 0.5)
ax.set_title('서울에서 타시도로의 인구 이동', size = 30, color = 'brown', weight = 'bold')
ax.set_ylabel('이동 인구 수', size = 20, color = 'blue')
ax.set_xlabel('기간', size = 20, color = 'blue')
ax.legend(loc = 'best', fontsize = 15)
plt.show()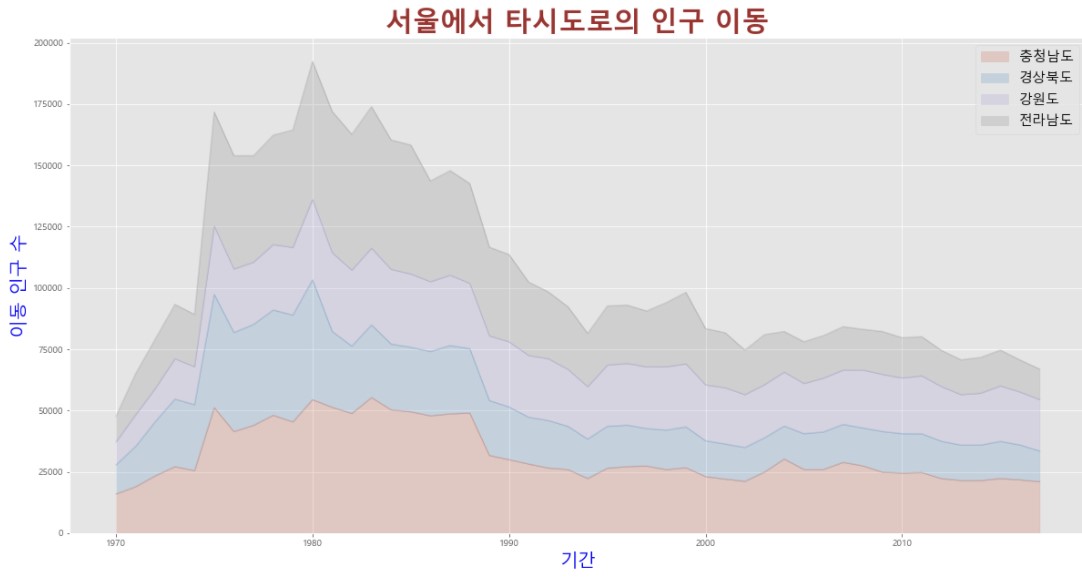
3) 막대 그래프
col_years = list(map(str, range(2010, 2018)))
df5 = df_seoul.loc[['충청남도', '경상북도', '강원도', '전라남도'], col_years]
df5 = df5.transpose()
df5.plot(kind = 'bar', figsize = (20,10), width = 0.7,
color = ['orange', 'green', 'skyblue', 'blue'])
plt.title('서울에서 타시도로의 인구 이동', size = 30)
plt.ylabel('이동 인구 수', size = 20)
plt.xlabel('기간', size = 20)
plt.ylim(5000, 30000)
plt.legend(loc = 'best', fontsize = 15)
plt.show()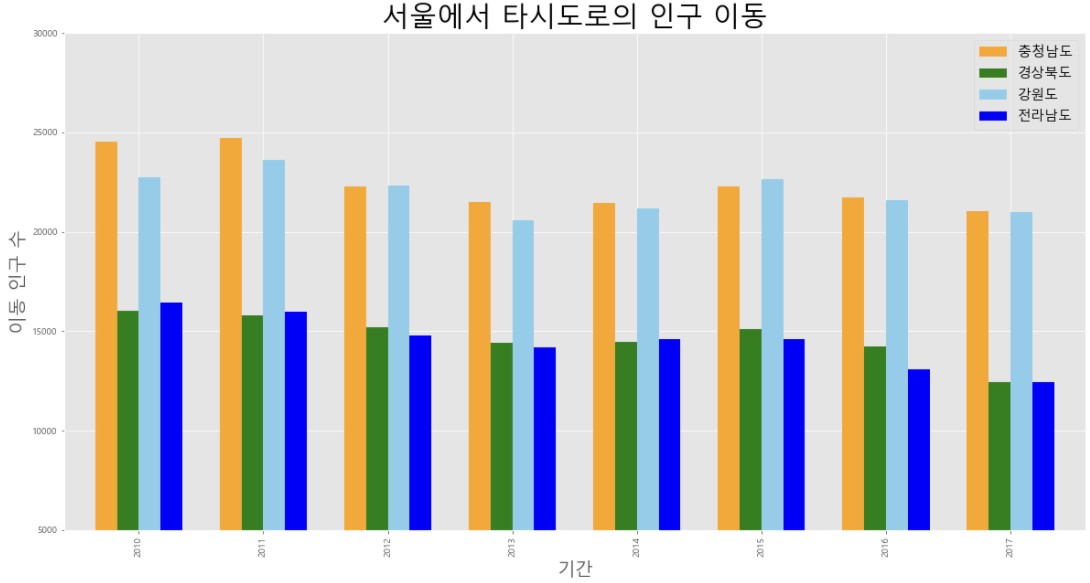
col_years = list(map(str, range(2010, 2018)))
df5 = df_seoul.loc[['충청남도', '경상북도', '강원도', '전라남도'], col_years]
df5['합계'] = df5.sum(axis = 1)
df6 = df5[['합계']].sort_values(by = '합계', ascending = True)
df6.plot(kind = 'barh', color = 'cornflowerblue', figsize = (10,5), width = 0.5)
plt.title('서울에서 타시도로의 인구 이동')
plt.ylabel('전입지')
plt.xlabel('이동 인구 수')
plt.show()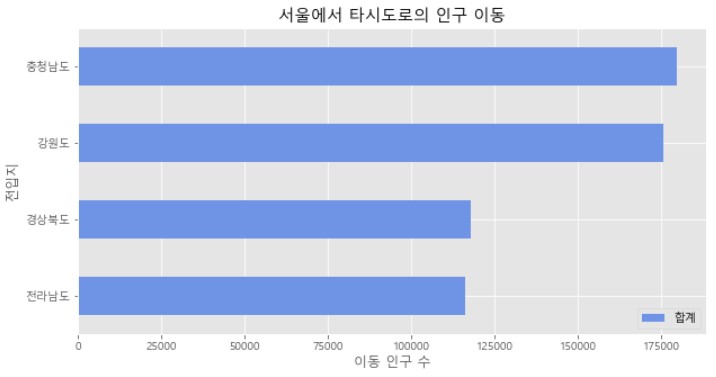
4) 히스토그램
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('classic')
df = pd.read_csv('./auto-mpg.csv', header = None)
df.columns = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration',
'model year', 'origin', 'name']
df['mpg'].plot(kind = 'hist', bins = 10, color = 'coral', figsize = (10,5))
plt.title('Histogram')
plt.xlabel('mpg')
plt.show()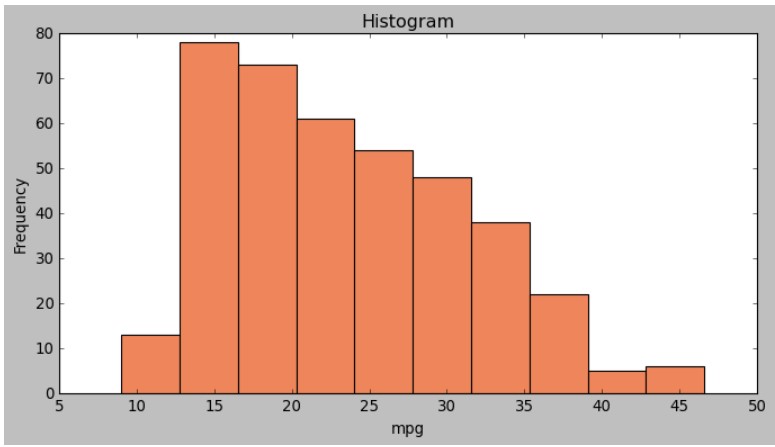
5) 산점도
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('default')
df = pd.read_csv('./auto-mpg.csv', header = None)
df.columns = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration',
'model year', 'origin', 'name']
df.plot(kind = 'scatter', x = 'weight', y = 'mpg', s = 10, color = 'coral', figsize = (10,5))
plt.title('Scatter Plot - mpg vs weight')
plt.show()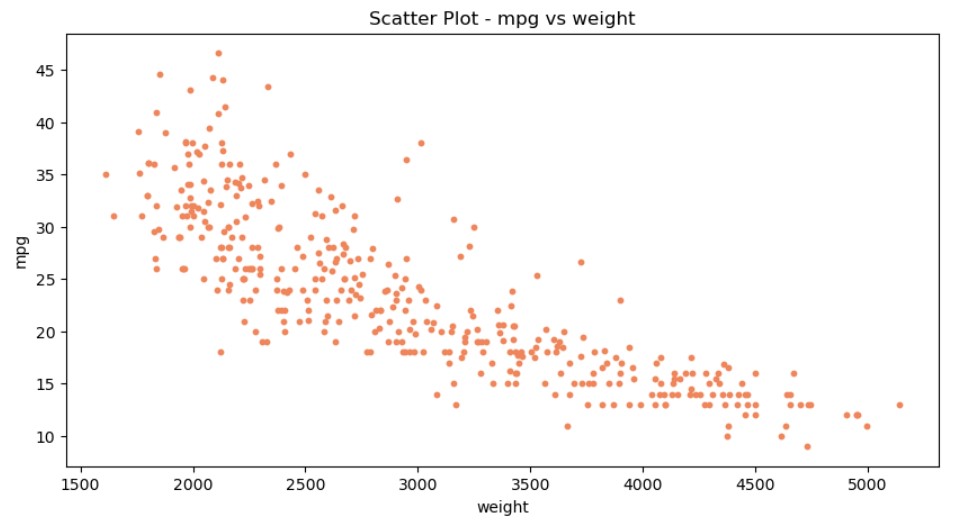
cylinders_size = df.cylinders/df.cylinders.max() * 300
df.plot(kind = 'scatter', x = 'weight', y = 'mpg', c = cylinders_size, s = 50,alpha = 0.2, marker = '+', cmap = 'viridis', figsize = (10,5))
# 색상을 정하는 cmap 으로 viridis 옵션 사용
plt.title('Scatter Plot : mpg-weight-cylinders')
plt.savefig("./scatter.png")
# 그래프 저장
# transparent = True를 추가하면 그림 배경을 투명하게 지정하여 저장
plt.show()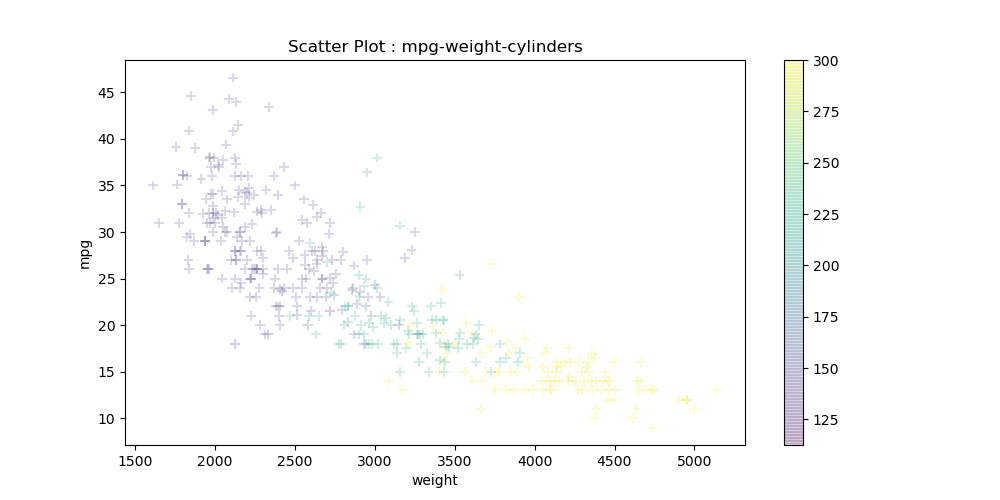
6) 버블 차트
해당 열의 최대값 대비 상대적 크기를 나타내는 비율 계산
점의 크기를 값에 따라 다르게 표시
cylinders_size = df.cylinders/df.cylinders.max() * 300
df.plot(kind = 'scatter', x = 'weight', y = 'mpg', s = cylinders_size, alpha = 0.2, color = 'coral', figsize = (10,5))
plt.title('Scatter Plot : mpg-weight-cylinders')
plt.show()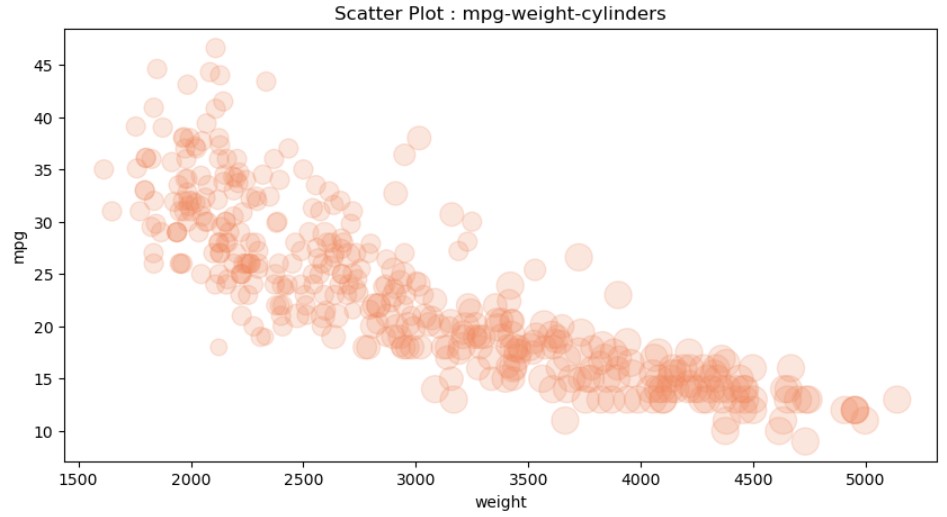
7) 파이 차트
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('default')
df = pd.read_csv('./auto-mpg.csv', header = None)
df.columns = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration',
'model year', 'origin', 'name']
df['count'] =1
# 전체 데이터 수를 세기 위한 컬럼
df_origin = df.groupby('origin').sum()
# origin 별로 그룹화 및 합계
df_origin.index = ['USA', 'EU', 'JPN']
df_origin['count'].plot(kind = 'pie',
figsize = (7,5),
autopct = '%1.1f%%', # 퍼센트 표시
startangle = 10, # 파이 조각을 나누는 시작점 (각도)
colors = ['chocolate', 'bisque', 'cadetblue']) # 색상 리스트
plt.title('Model Origin', size = 20)
plt.axis('equal')
# 파이 차트의 비율을 같게 (원에 가깝게) 조정
plt.legend(labels = df_origin.index, loc = 'upper right')
# loc 값은 범례 위치 조정
plt.show()
8) 박스 플롯
박스 플롯은 최소값, 1분위값, 중간값, 3분위값, 최대값 제공
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
font_path = './malgun.ttf'
font_name = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family = font_name)
plt.style.use('seaborn-poster')
df = pd.read_csv('./auto-mpg.csv', header = None)
df.columns = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration',
'model year', 'origin', 'name']
fig = plt.figure(figsize = (15,5))
ax1 = fig.add_subplot(1,2,1)
ax2 = fig.add_subplot(1,2,2)
ax1.boxplot(x = [df[df['origin']==1]['mpg'],
df[df['origin']==2]['mpg'],
df[df['origin']==3]['mpg']],
labels= ['USA', 'EU', 'JAPAN'])
ax2.boxplot(x = [df[df['origin']==1]['mpg'],
df[df['origin']==2]['mpg'],
df[df['origin']==3]['mpg']],
labels= ['USA', 'EU', 'JAPAN'],
vert = False)
# vert = False를 통해 수평 박스 플롯 만들기
ax1.set_title('제조국가별 연비 분포 (수직 박스 플롯)')
ax2.set_title('제조국가별 연비 분포 (수평 박스 플롯)')
plt.show()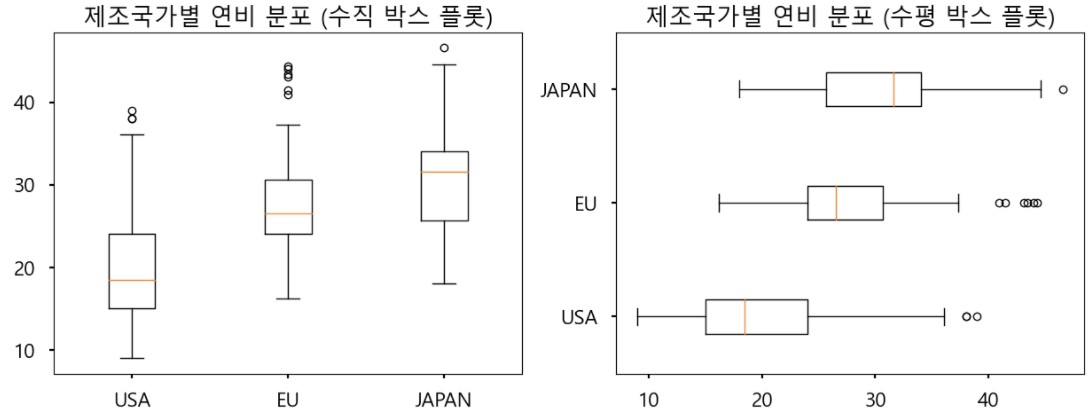

따또의 DA 벨로그