Data Augmentation(데이터 증강)은 Regularization(정규화)와 마찬가지로 overfitting 문제를 해결하는 방법이다. 다양한 유형의 학습 이미지 데이터 양을 늘리면 과적합 문제를 해결할 수 있다.
| Regularization | Data Augmentation | |
|---|---|---|
| 개입 대상 | 모델 | 데이터 |
| 방식 | loss/weight에 제약 | input을 변경 |
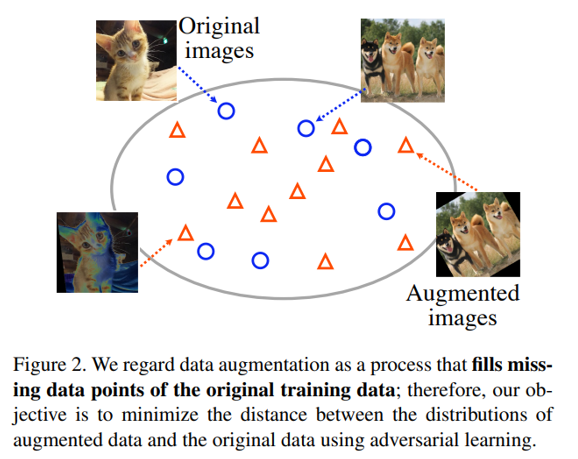
- 모델의 일반화 능력을 향상시키기 위해 INPUT 데이터를 인위적으로 확장
- 원본 학습 이미지 개수를 늘리는 것이 아니라, 학습 시마다 개별 원본 이미지를 변형하여 학습을 수행하는 것
- label은 유지한 채, input distribution을 넓혀서 모델이 invariance를 학습하도록 도움
pixel-level

과하면 semantic 정보가 깨질 수 있어 (예: 숫자 6에 blur을 너무 많이 넣으면 0처럼 보일 수 있음) 강도를 조절하는 하이퍼파라미터가 중요하다.
-
blur

- gaussian blur

- 기본 blur 기법
모든 픽셀 값에 동일하게 영향을 주는 평균 필터 사용
가까이 있는 픽셀과 멀리 있는 픽셀의 가중이 동일하여 결과물의 퀄리티가 떨어질 수 있음 - gaussian blur 기법
가깝게 위치한 픽셀의 가중치를 높게 설정하여 전반적인 이미지 품질을 높임
- 기본 blur 기법
- motion blur

- 무작위 크기를 갖는 커널(필터)를 통해 연산되며, 입력 이미지가 blur와 유사하게 흐리게 나타남
- median blur

- 타겟 픽셀의 근처에 존재하는 픽셀 값들을 갖는 필터를 기반으로 동작하나, 평균 등의 값이 아닌 중앙값을 활용
- gaussian blur
-
color jitter

- brightness, contrast, saturation, hue를 무작위로 변환하는 기법
-
noise
- gaussian noise

- salt & pepper noise

- gaussian noise
spatial-level


- crop
- flip
- affine
- rotate
- scale
- translate
- shear
최근 동향
-
cutout

- 이미지 일부를 사각형 모양으로 검은색을 칠해버리는 기법 (해당 영역을 0으로 채워 넣음)
- 이미지의 덜 중요한 부분까지 집중하게 유도
- 특정 부분에 의존하지 않고 전체 context를 보게 만듦
- 객체 일부가 가려져도 인식 가능하도록 유도
-
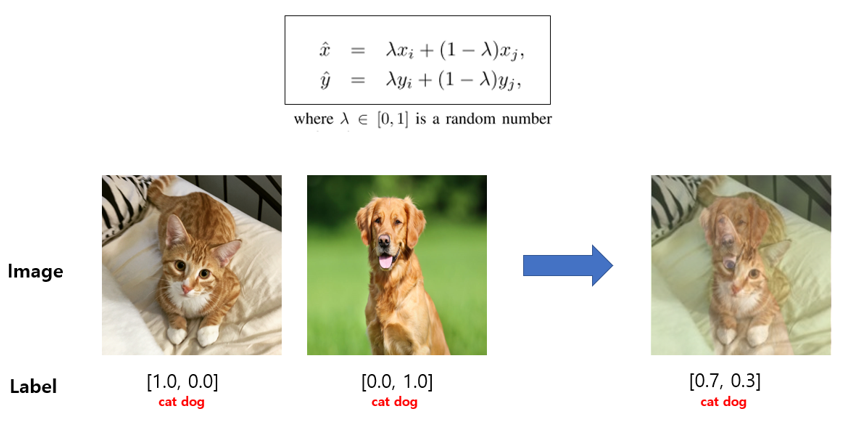
mixup
-
cutmix

- cutout + mixup
- A 이미지에서 box를 쳐서 지운 다음 그 빈 영역을 B 이미지로부터 patch를 추출하여 집어넣음
- patch의 면적의 비례하여 label을 섞어줌
-
augmix

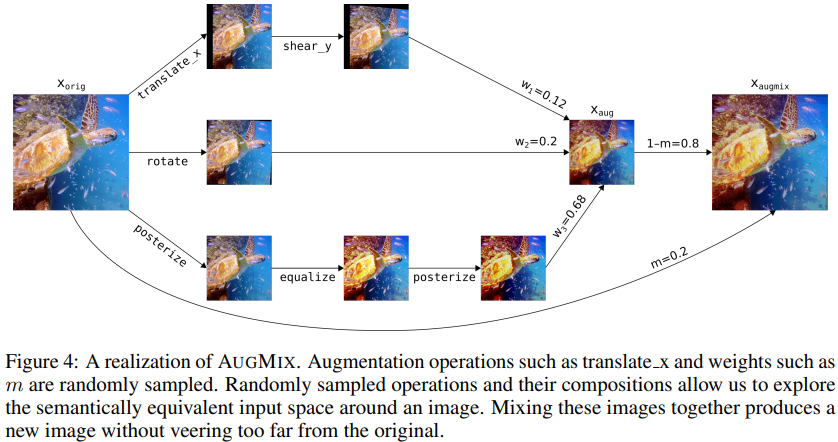
- 한 장의 이미지에 여러 augmentation 기법들을 직렬/병렬로 연결한 뒤 원본과 다시 섞음
Reference
