Communication Cost
-
statistical accuracy와 communication efficiency는 trade-off 관계에 있다.
-
참여 클라이언트 수
매 라운드에 참여하는 클라이언트가 많을수록 전체 전송 데이터량이 증가한다. -
round 수, iteration 빈도
글로벌 모델이 수렴하기까지 서버-클라이언트 간에 모델 업데이트를 주고받는 횟수가 많을수록 전체 통신 비용이 커진다. -
데이터 이질성
모델 수렴 속도가 느려져 더 많은 통신 라운드가 필요할 수 있다. -
모델 크기
전송되는 모델 파라미터의 양이 많을수록 통신 비용이 증가한다. -
shared bits
각 global iteration에서 공유되는 비트 수가 클수록 communication overhead가 증가한다.
System Heterogeneity
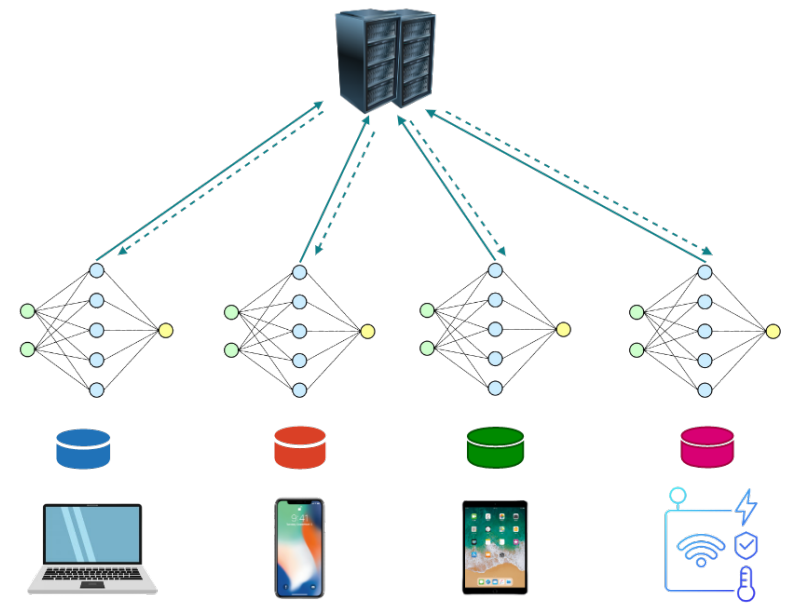
FL에 참여하는 클라이언트들의 기기는 모두 제각각
→ 장치의 역량(CPU, GPU, 메모리, 대역폭, 지연, 카메라 성능, 참여 가능 시간 등)이 서로 다름
→ 데이터 이질성 야기
Statistical Heterogeneity
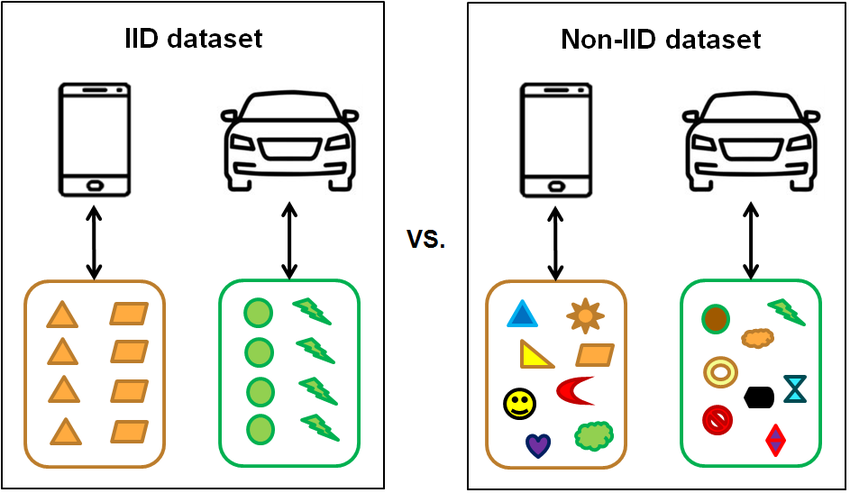
Non-IID한 데이터들
FL은 참여하는 클라이언트들 사이에서 독립적이지 않게 · 동일하지 않게 분포된(Non-Independent and Identically Distributed) 데이터 분포에 직면했을 때 상당한 성능 저하와 낮은 수렴성(convergence) 문제로 어려움을 겪는다.
-
Skew
데이터 분포가 특정 방향으로 치우쳐 있는 정도
non-iid를 구성하는 구체적 형태-
Label Skew
클래스 분포가 클라이언트마다 다름
→ gradient 방향 충돌, FedAvg 성능 ↓- 예시
Client A: 고양이 90%, 개 10%
Client B: 개 90%, 고양이 10%
- 예시
-
Feature Skew
입력 분포가 다르고 라벨은 같음- 예시
병원A: 밝은 CT
병원B: 어두운 CT
- 예시
-
Quantity Skew
데이터 양이 클라이언트마다 다름- 예시
클라이언트A: 10,000개
클라이언트B: 100개
- 예시
-
Non-IId 해결 방법
Data-level 접근
각 로컬 데이터가 global 분포처럼 보이게 만들기
데이터가 무한히 많다면 클라이언트에게 가장 좋은 모델이 되지만 현실적으로 불가능
-
모든 클라이언트가 소량의 데이터 (global anchor 역할) 공유
-
Synthetic Data Generation (Generative Models) ⭐
부족한 분포를 생성한 데이터로 채우면 되지 않을까?
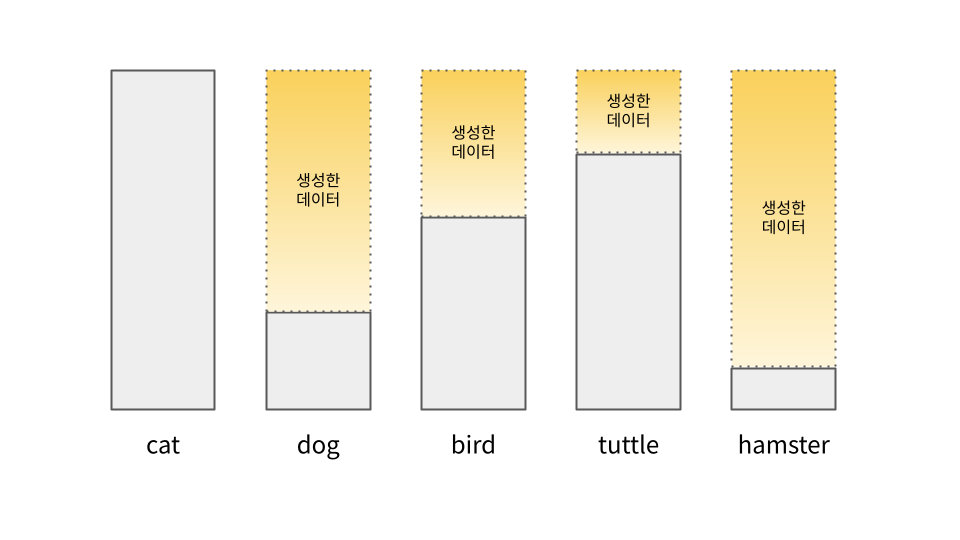
- Diffusion 기반 ⭐
- pretrained generative model 활용
- client가 직접 데이터 생성
- Diffusion 기반 ⭐
Model-level 접근
모델이 local 편향에 덜 흔들리게 만들기
-
Batch Normalization
Optimization-level
non-IID = 각 client의 gradient 방향이 서로 다르다. ()
- gradient variance ↑
- 평균 gradient가 엉뚱한 방향
- 수렴이 느리거나 발산함
'어떻게 업데이트할 것인가'를 바꾸기
Aggregation 개선하기
- FedAvg
- FedSGD
- 기타 등등
-
학습률 / local step 조절
-
FedProx
loss에 'global과 너무 멀어지지 마라'는 항을 추가한다.- : local 모델이 global 모델에서 얼마나 멀어질 수 있는지를 제한하는 하이퍼파라미터
- non-IID 데이터로 인해 로컬 모델 업데이트 방향이 global optimum에서 점점 멀어지는 현상인 client drift 억제

Personalization ⭐
하나의 global 모델이 모든 클라이언트에서 잘 동작하게 하고 싶어 → 근데 클라이언트마다 데이터 분포가 다르네? (non-IID) + 각 클라이언트의 최적 모델이 다르네? → 굳이 하나의 모델을 써야 되나?
https://arxiv.org/abs/2410.08934
Reference
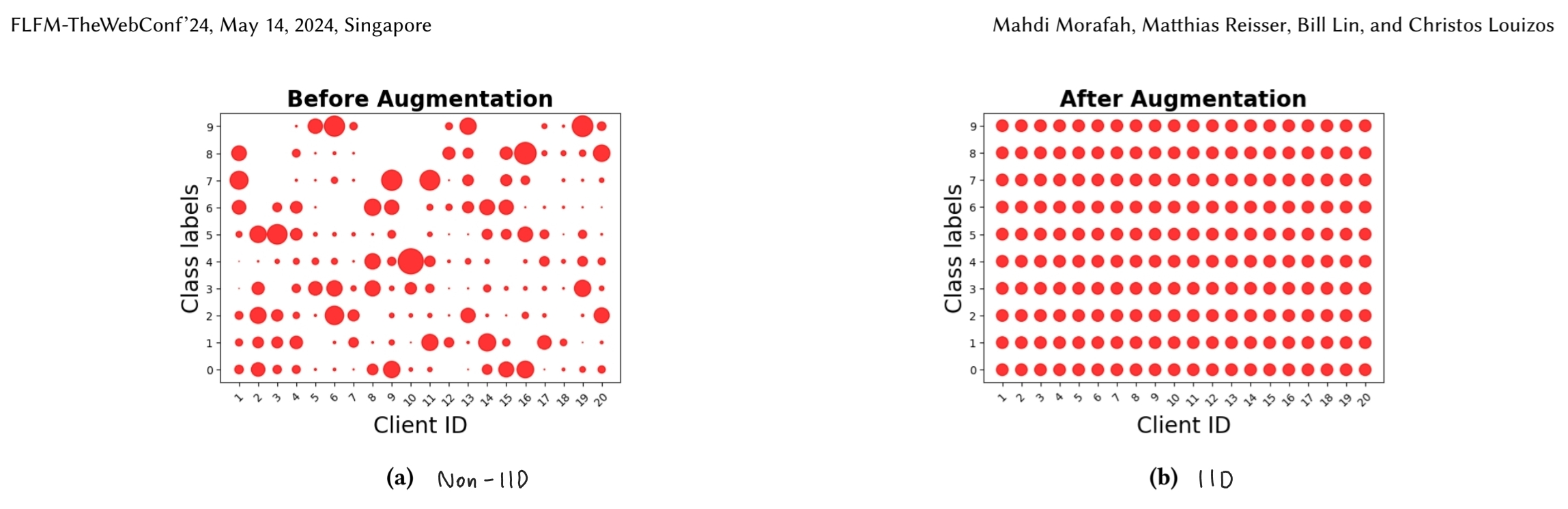
- Morafah, Mahdi, et al. "Stable diffusion-based data augmentation for federated learning with non-iid data." arXiv preprint arXiv:2405.07925 (2024).
- https://kang-studyroom.tistory.com/2
- Wen, Hui, et al. "Communication-efficient federated data augmentation on non-IID data." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
