Learning Cause-Effect Models
통계적 학습이론(Statistical Learning)의 관점에서 살펴보면, 가장 간단한 케이스인 cause-effect model을 학습하는 것 조차 어려움이 존재한다. Statistical Learning은 소위 주어진 관측값 들로부터(observation) 의 joint distribution을 추정하는 과정이다. 반면, 인과관계추론애서는 여기서 더 나아가 어떤 변수가 원인이고 어떤 변수가 결과인지를 파악해야한다. 그런데, 사실 joint distribution을 추정했다고 해도 만일 X,Y의 데이터에 대한 사전정보(ex. 변수의 의미, 측정 방법, 과정 등)가 존재하지 않는다면 관측값들은 단순한 실수 순서쌍에 불과하다. 즉, real-world information이 없다면 우리는 이 모델이 인지 인지 알 겨를이 없다는 것이다.
이를 파악하게 해주는 개념이 바로 Identifiability(식별가능성)이다. 이는 확률변수의 joint distribution으로부터 cause-effect model이 와 의 두 모델 중 하나의 모델로 구별해낼 수 있는 특성을 말한다. 여기서는 식별가능성에 필요한 조건 및 가정 모델들을 다루어보도록 하겠다.
Assumptions
Non-Uniqueness of graph structures
Prop. 확률변수 가 실수값을 가지면 모든 종류의 joint distribution 에 대해 다음 SCM
로 나타낼 수 있다(는 가측함수이고 는 실확률변수). 그런데, 사실상 가 교환된 형태의 SCM 역시 가능하므로, 위 명제의 의미는 모든 joint distribution에 대해 양방향 모두로의 SCM이 존재한다는 것이다. 따라서, 구조의 식별가능성(structure identifiability)을 위해 추가적인 가정이 필요하다. 어떤 종류의 가정을 부여해야할 지 생각해보면, 우선 머신러닝에서 사용하는 관점을 빌려와 model의 class(집합)를 사전에(a priori) 제한하는 방법을 고려할 수 있다. 즉, SCM이 취할 수 있는 함수들의 집합을 라고 하고, cause variable의 marginal distribution을 로 정의하면 이러한 function class에 규제를 부여하는 방식으로 식별가능성을 이끌어 낼 수 있을 것이다. 이전에 다룬 cause와 mechanism의 독립성을 이용할 수도 있다. 즉, cause variable과 mechanism(noise variable 포함)이 단순히 statistically independent한 것이 아니라, 서로에 대한 정보가 없는 모델을 고려한다면 이러한 모델은 식별가능성의 토대로 작용할 수 있다. 역으로, 독립성이 보장되지 않는다면 의 SCM을 허용하는 것이다. 이제 다양한 모델을 살펴보며 구체적으로 식별가능성이 어떻게 얻어지는지 공부해보도록 하자.
Linear Models with Non-Gaussian Additive Noise
여기서 다루고자 하는 모델은 Linear Non-Gaussian Acyclic(비순환) Model이다. 이는 다음과 같은 모델 가정을 바탕으로 한다.
(는 실수), 이때 Noise variable 가 Gaussian distribution을 따르지 않으면, 이는 identifiability의 충분조건이 된다. 다음 정리를 통해 이를 알 수 있다.
Theorem
정리. Joint distribution 가 다음 선형모델을 허용하면(admit)
(는 continuous random variable), 실수 과 random variable 가 존재하여
일 필요충분조건은 와 가 Gaussian 분포를 따른다는 것이다.
즉, 위 정리로부터 식별불가능함과 gaussian additive noise가 동치이므로 non-Gaussian additive noise model은 식별가능하다는 결론이 도출된다. 다음 예시를 살펴보면 이해가 쉽다.
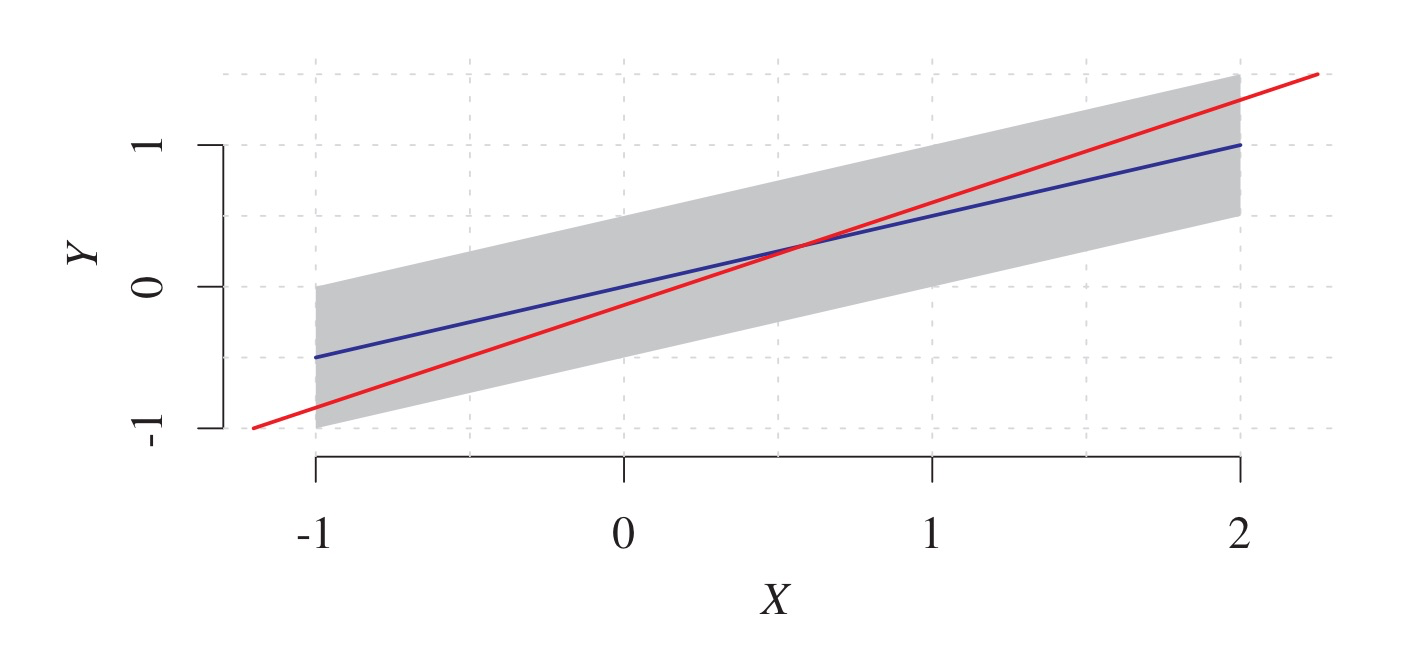
위 plot에서 회색 영역은 두 확률변수 의 joint distribution에 대한 support를 영역으로 나타낸 것이다. 파란색 선은
모델을 나타낸 것인데, 이때 노이즈 변수 는 위 그림에서도 알 수 있다시피 균등분포를 따른다(non-Gaussian). 반면, 빨간색 선은 최소제곱법, 즉
의 그래프를 나타낸 것이다. LSE 모델 혹은 위 파란색 선 자체가 이 정방향 모델(forward model)의 역방향 모델(backward)로 작용할 수 있는지 생각해보자. 즉, 위 그래프의 축을 서로 바꾸는 게 가능할지 생각해보면 각 Y에 대해 가 취할 수 있는 값의 영역(회색)이 균등하지 않다. 파란색 선을 기준으로 살펴보아도, 인 경우 는 부터 1까지의 값만 취할 수 있는 반면, 인 경우 는 -1부터 1까지의 값을 취할 수 있다. 따라서 가 와 독립이지 않으므로 이는 타당한 SCM이 될 수 없다.
정리 4.2의 증명은 다음 Darmois-Skitovic 정리의 bivariate 형태로 얻을 수 있다.
Darmois-Skitovic THM
확률변수 가 독립이고 non-degenerate 하다고 하자. 만약 non-vanishing하는 계수 와 (각 에 대해 가 모두 0을 취하지 않음)로 이루어진
두 선형결합이 독립이라면, 각 는 모두 정규분포를 따른다.
여기서 확률변수가 non-degenerate하다는 것은 로 만드는 (차원 확률벡터일때)가 존재하지 않는다는 것을 의미한다. 위 Darmois-Skitovic 정리로부터 앞선 정리 4.2를 증명할 수 있는데, 자세한 증명내용은 여기서 생략하도록 하겠다.
Nonlinear Additive Noise Models
앞선 내용에서는 선형모형을 살펴보았는데, 이번에는 일반적인 함수 로 이루어진 nonlinear한 경우에 대해 식별가능성을 살펴보도록 하자. 우선, 다음과 같이 Additive Noise Model(ANM)을 정의하기로 하자.
ANM
결합분포 가 의 ANM을 허용(admit)하기 위해서는 다음을 만족하는 가측함수 와 noise variable 가 존재해야 한다.
편의상 이 경우 가 ANM을 admit한다고 표기한다(방향성을 condition으로 표기함).
Smoothness
ANM (1)이 smooth하다는 것은 가 strictly positive한 밀도함수 를 가지고 가 3번 미분가능함을 의미한다.
위 정의를 바탕으로 일반적인(generic) 경우에 대한 식별가능성을 다음과 같이 얻을 수 있다.
Theorem
가 X에서 Y로의 smooth ANM을 admit하고, all but countably many인 에 대해
인 이 존재한다고 하자. 그러면 역방향 의 smooth ANM을 admit하는 에 대한 로그확률밀도함수의 집합은 3차원 affine space에 포함된다.
위 정리에서 만일 가 가우시안 분포인 경우 가 linear한 경우만 backward ANM을 허용, 즉 non-identifiable하다(앞선 Non-Gaussain model 정리 참고). 위 정리의 증명은 생략하나, 정리의 핵심은 결국 결합분포가 정방향 ANM을 허용하면 generic한 경우(위 정리의 조건을 만족하는 경우) 역방향 ANM은 존재하지 않는다는 것이다.
Discrete ANM
이번에는 noise variable이 이산변수인 경우를 살펴보도록 하자. 즉, 가 정방향 ANM()인 를 허용하고, 이때 또는 가 유한 support를 가진다고 하자(이산확률변수). 이때 역방향 ANM을 허용할(non-identifiable) 필요충분조건은 다음과 같다.
X의 support에 대한 disjoint decomposition 이 존재하여 다음 세 조건을 만족한다.
각 들은 서로 shift된 집합이다. 즉,
또한 함수 는 각 영역 에서 상수함수 이다.
들에 대한 확률분포도 서로 shift 및 scaled 된 형태이다. 즉, 에서 확률분포는
집합
들은 서로소이다.
위 정리와 유사하게, modulo 연산(나머지 동치 연산)에 대해서도 비슷한 결과를 얻을 수 있다. 간단히 다음 ANM
을 생각하자(는 균등이산분포). 이 경우 noise variable와 나머지 연산으로 인해 X,Y의 함수관계 가 무관해지며 독립이 된다. 따라서 역방향 ANM이 존재하여 non-identifiable하다.
Post-nonlinear model부터의 chapter 내용은 다음 게시글에 정리하도록 하겠다.
Reference
- Elements of Causal Inference, Jonas Peters et al.
