Learning Cause-Effect Models (2)
이번 게시글에서는 저번에 이어 다른 Cause-Effect 모델들과 이들의 식별가능성에 대해 계속 살펴보도록 하고, 실제 데이터에 대해 identification을 진행하는 과정에 대해 구체적으로 알아보자.
Post-nonlinear Models
Post-nonlinear model은 이전에 살펴본 Nonlinear ANM의 일반화된 모델이다. 결합분포 가 X에서 Y로의 post-nonlinear model을 admit한다는 것은 다음 관계
을 만족하는 함수 와 noise variable 가 존재하는 것이다. 이러한 post-nonlinear model에 대해 다음 정리가 성립하는데, 이는 post-nonlinear model이 일반적이지 않은 경우를 제외하고는 identifiable하다는 것을 의미한다.
Theorem
결합분포 가 위 (1)의 post-nonlinear model을 admit하고 가 세번 미분가능하다고 하자. 만일 가 특정 미분방정식을(Zhang and Hyvarinen[2009]) 만족하도록 조절(adjusted)된다면 에서 로의 post-nonlinear model을 admit한다.
Information-Geometric Causal Inference
정의
결합분포 가 다음 조건을 만족하면 에서 로의 IGCI 모델을 admit한다:
- strictly monotonic이고 을 만족하는 diffeomorphism(가 미분가능이고 bijective이며, 역함수도 미분가능함) 에 대해 로 주어진다.
- 의 strictly positive continuous density 가
을 만족한다(independence condition).
이때, 조건 2에서 함수 와 확률밀도함수 는 모두 probability space 에서 균등분포를 갖는 확률변수로 여겨진다. 즉, 위 독립성 조건은
으로 주어진다.
식별가능성
결합분포 가 에서 로의 IGCI model을 admit할 때, 역함수 에 대한 식
이 성립한다. 또한, 함수 가 항등함수(identity)인 것은 위 등호를 만족할 필요충분조건이다.
Structure Identification Methods
Additive Noise Models
RESIT
이전 게시글에서 Additive Noise Model의 식별가능성에 대해 살펴보았는데, 이번에는 주어진 데이터셋에 대해 어떻게 식별(identify)이 이루어지는지 살펴보도록 하자. 첫번째 방법으로는 잔차의 독립성을 검정하는 방법이다. 이를 regression with subsequent independence test, 줄여서 RESIT라고 부르는데, 알고리즘은 다음과 같다.
RESIT Algorithm
1. 를 반응변수로, 를 예측변수로 회귀분석하여, 를 의 함수 와 noise로 나타낸다.
2. 와 가 독립인지 검정한다.
3. 1-2의 과정을 의 역할을 바꾸어 수행한다.
4. 만일 한 방향으로는 독립성 검정이 accept되고 다른 방향으로는 기각된다면 전자의 방향으로 인과방향이 정해진다.
실제로 임의생성된 샘플에 대해 RESIT 알고리즘을 적용해보자. 정방향 ANM이
로 주어지는 Cause-Effect model에 대해 랜덤 샘플 500개를 생성하고, 우선 정방향에 대해 위 알고리즘의 1-2 과정을 실행하면 다음과 같은 결과를 얻을 수 있다.
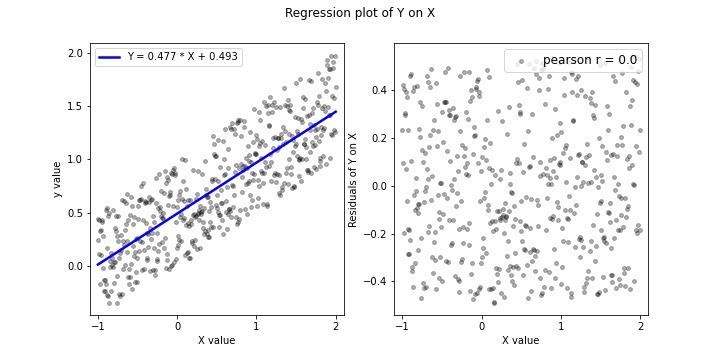
왼쪽 그림은 샘플 산점도 위에 추정된 정방향 선형회귀모형(Y on X)을 그린 것이다. 오른쪽 그림은 정방향 회귀에서 잔차와 예측변수의 상관관계를 나타낸 산점도인데, 실제로 pearson 상관계수가 0에 수렴하고 p-value 역시 0.99 이상으로 나타나 잔차의 독립성이 검증된다(실제로는(practically) Hilbert-Schmidt Independence Criterion 등을 사용한다).
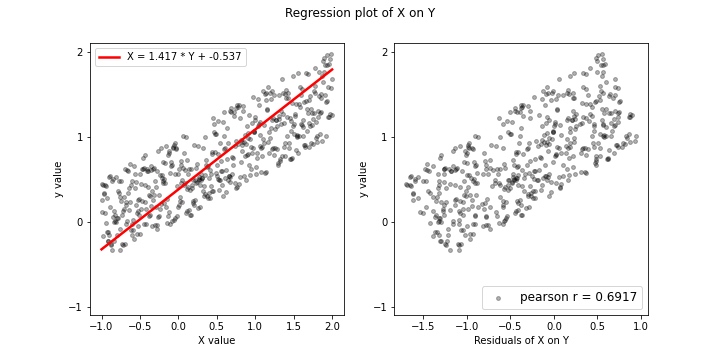
반면, 위 그림은 역방향 모델에 대해 선형모형(X on Y)을 추정하고, 마찬가지로 오른쪽에 잔차 산점도를 그렸다. 이때, 여기서는 잔차와 예측변수 의 관계가 독립적이지 않음을 가시적으로 확인가능한데, 실제로 pearson 상관계수 역시 유의미하게 나타났으며 p-value 역시 0에 수렴하는 것으로 나타났다. 즉, 이를 종합하면 RESIT 알고리즘에 의해 역방향 ANM이 성립하지 않고, 정방향 모델이 유일한 것으로 식별가능하다. (샘플 생성부터 plot까지의 Full code는 github에서 확인가능하다.)
Maximum—Likelihood
RESIT 알고리즘의 대안으로, 최대가능도 기반의 접근법을 사용할 수 있다. 예시로, additive Gaussian error를 갖는 nonlinear SCM을 고려하자(이전 게시글 참고). 이때 와 를 구분하기 위해 Maximum-likelihood 접근법을 사용하는 것은 각 모형의 가능도를 계산하여 비교하는 것이다. 과정은 다음과 같다.
우선, 를 반응변수, 를 예측변수로 하여(정방향) nonlinear regression을 진행한다. 이때 얻은 잔차를 로 정의하자. 그러면 정방향에 대한 로그가능도는
로 정의된다. 역방향에 대해서도 같은 방식으로
를 정의할 수 있다. 그러나 이를 실제로 사용하기 위해서는 위 과정이 정당한지 살펴보아야 하는데, noise가 정규성을 가져야 한다는 것 등의 여러 가정에 대한 검증이 요구된다. 이 방법을 데이터셋에 사용하기 위해서는 dHSIC(d-variable Hilbert Space Independence Criterion) test의 형태로 이용할 수 있는데, 찾아보니 python에서는 이를 제공하는 라이브러리가 없는 것 같고 R에서는 dhisc.test 형태로 이용가능하다.
Supervised Learning Methods
여기서는 좀 더 머신러닝의 관점에서 causal learning을 살펴보도록 하자. 머신러닝 관점에서 causal learning 상황은 다음과 같은 training data로 표현가능하다.
이때 각 는 데이터셋에 대응하는데, 각각의 데이터셋은 확률분포 의 realization이다. 또한, 각 label 은 각 데이터셋 가 에 대응하는지, 에 대응하는지를 설명하는 label이다.
이렇게 문제를 정의해버리면 결국 causal learning은 classical한 지도학습 문제에 대응된다는 것을 확인할 수 있고, train data에 대해 학습시킨 분류기는 관측되지 않은 test 데이터셋에 대해서도 인과관계추론이 가능하다고 가정할 수 있다. 다만, causal learning 영역에서 지도학습이 독자적으로 사용되지는 않고, 이는 추가적인 연구가 필요한 영역이다.
Reference
- Full code on Github : https://github.com/ddangchani/Velog/blob/main/Causal%20Inference/
- Elements of Causal Inference
