이전에 Linear Classification에서 Fischer's LDA에 대해 다룬 적 있었다. 이는 특성공간에서 데이터들을 분류하기 위한 선형 경계를 만드는 것인데, support vector classifier/machine은 이와 유사하나 비선형인 결정경계를 만들 수 있다는 점에서 좀 더 일반화된 개념으로 생각하면 된다.
Support Vector Classifier
Hard Margin
N개의 observation으로 구성된 데이터셋 (x1,y1),(x2,y2),…,(xN,yN)이 주어지고 이때 xi∈Rp, yi∈{−1,1} 이라고 하자. 이때 데이터의 분류를 위한 초평면(hyperplane)을 다음과 같이 정의하자.
{x:f(x)=xTβ+β0=0}
여기서 β 는 ∥β∥=1 인 unit vector이며, f(x)에 의한 클래스 예측값은
G(x)=sgn(xTβ+β0)
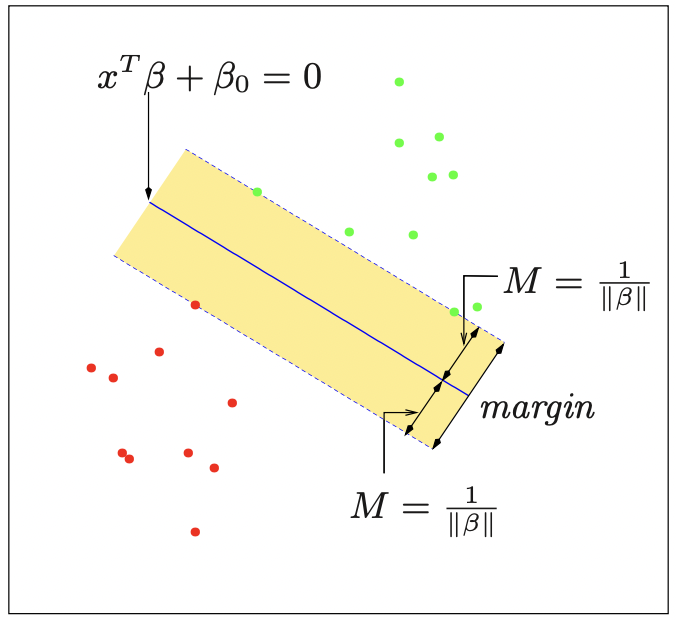
으로 주어진다. 만일 데이터가 선형경계로 분리될 수 있다고(separable) 가정하면, yif(xi)>0 을 만족하는, 즉 실제 클래스와 예측 클래스가 일치하게끔 하는 함수 f(x) 를 찾을 수 있다(아래 그림 참고).
그런데, 이를 만족하는 함수 f는 한 개 이상 존재할 수 있으므로, 최적의 classifier을 선택하기 위해서는 다른 기준이 필요하다. 이때 위 그림과 같이 결정경계에서 가장 가까운 데이터들까지의 거리를 margin이라고 정의하면, margin M을 최대화하는 최적화문제
∥β∥=1maxMsubject toyi(xiT+β0)≥M
를 만족하는 biggest-margin hyperplane f를 찾을 수 있다. 이러한 hyperplane을 만드는 과정은 가장 가까운 데이터들에 의해 결정되므로, 이때 margin 경계에 위치한 데이터들을 support vector라고 정의한다. margin M은 hyperplane에서 각 class의 측면으로의 margin을 의미하므로(그림 참고) 전체적인 margin의 너비는 2M이라고 볼 수 있다. 만일 노음에 대한 규제 ∥M∥=1 을 없애면 위 최적화문제를
β,β0min∥β∥subject toyi(xiTβ+β0)≥1,i=1,…,N
으로 쓸 수 있다. 이때 마진 M은 M=1/∥β∥ 가 된다. 이처럼 support vector들을 기준으로 클래스의 중첩 없이 hyperplane을 구성하는 모델을 support vector classifier 중에서도 Hard Margin classifier라고도 한다(엄격하게 margin을 지킨다는 의미이다).
Soft Margin
이번에는 특성공간에서 클래스의 중첩이 발생하는 데이터셋을 생각해보자. 즉, 앞선 hard margin classifier을 이용해 데이터를 분류할 수 없고 일부 데이터는 분류기의 반대편(wrong side)에 위치하는 경우를 의미한다. 이를 위해서는 hard margin classifier의 최적화 문제에 완화 변수(slack variable) ξ=(ξ1,ξ2,…,ξN),ξi≥0 을 적용하여
yi(xiTβ+β0)≤M(1−ξi),∀i,ξi≥0,i∑ξi≤constant
으로 최적화 문제를 변환할 수 있다. 이렇게 정의한 모델을 support vector classifier의 표준 모델로 사용한다. 여기서 각 완화변수 ξi는 정량화된 값이라기보단 각 예측치가 margin의 wrong side에 위치할 수 있는 완화 조건을 비율적으로 정한 값이다. 그러므로, 완화변수들의 합 ∑iξi 를 일정 상수 이하로 규제함으로써 어느 정도의 비율로 wrong-side positioning을 허가할 것인지 정할 수 있다. 이때 각 관측치가 잘못 분류되는 misclassification은 ξi>1 인 경우 발생하므로, 만일 ∑ξi≤k 로 두면 이는 최대 k개의 관측치가 잘못 분류될 수 있음을 의미한다. 이렇게 완화변수를 이용해 margin의 misclassification을 허용하는 모델을 Soft Margin Classifier라고 하며, 구체적으로 모델이 계산되는 방식을 살펴보도록 하자.
Computing the Support Vector Classifier
여기서는 Soft Margin Classifier(이하 Support Vector Classifier, SVC)가 어떤 방식으로 계산될 수 있는지 살펴보도록 하자. 우선 앞선 최적화 문제를 다시 쓰면 다음과 같다.
여기서 상수 C는 앞서 언급한 완화변수들의 합을 규제하는 상수(constant)의 역할을 대체하는데, Hard margin classifier의 경우 C=∞가 되어 각 slack variable들을 0으로 규제한다. 위 최적화문제를 Lagrangrian form으로 쓰면 Lagrange primal function은
과 같다. 최적화 문제를 풀기 위해 β,β0,ξi 에 대한 편미분계수를 0으로 하여 방정식을 구하면 다음과 같다.
β=i=1∑Nαiyixi,0=i=1∑Nαiyi,αi=C−μi,∀i(2)
위 세 식들을 앞선 식 (1)에 대입하면 다음과 같은 dual objective function
LD=i=1∑Nαi−21i=1∑Nj=1∑NαiαjyiyjxiTxj
을 얻을 수 있다. 이때 최적화는 0≤αi≤C, ∑i=1Nαiyi=0 조건 하에서 LD를 최대화하는 문제로 주어지게 된다. 또한 식 (2)의 세 식에 더불어 KKT(Karush-Kuhn-Tucker) 조건은 각 i=1,…,N에 대해 다음 제약조건들로 주어지는데,
제약조건 (2)와 (3)들을 모두 적용하면 dual problem에 대한 해는 다음과 같이 유일한 형태로 구해진다.
β^=i=1∑Nα^iyixi
이때 KKT condition (3)의 첫번째, 세번째 식으로부터, 세번째 부등식의 좌변이 0이 아닌 경우 첫번째 식에 의해 각 계수 α^i는 0으로 주어진다. 반대로, 세번째 부등식을 등식으로 만족하는 관측값들에 대해서는 계수 α^i가 0이 아닌 값을 가지게 되고 이는 초평면 결정에 영향을 미치게 된다. 즉, 이러한 관측값들이 앞서 설명한 support vector가 된다.
Support Vector Machines and Kernels
앞서 설명한 support vector classifier는 Input feature space에서 선형 결정경계를 구현하는 모델이었다. 하지만 굳이 Input feature space에 얽매이지 않고, feature space에 basis expansion 또는 Kernel Method를 적용하여 결정경계를 좀 더 유연하게 확장할 수 있다. Support Vector Machine classifier(SVM)은 이처럼 feature space의 변형을 통해 차원을 확장, 혹은 축소하여 분류기를 만드는 방식을 의미하며, 일반적으로는 커널을 사용해 만든 support vector classifier/regressor을 의미한다고 보면 될 것이다.
Computation of SVM
앞서 SVC를 계산하는 과정에서, Lagrange dual function을 다음과 같은 형태로 정의했다.
LD=i=1∑Nαi−21i=1∑Nj=1∑NαiαjyiyjxiTxj
SVM에서는 위 식의 내적(xiTxj) 대신에 feature transformation h(x)의(참고) inner product을 이용해 다음과 같이 정의한다.
으로 주어진다. 하지만 굳이 feature transformation의 내적을 구할 필요 없이, Kernel Trick을 이용하여 내적의 형태를
K(x,x′)=⟨h(x),h(x′)⟩
으로 정의해버리면 된다. 이때 커널 함수 K로는 d차원 다항커널(polynomial kernel), 가우시안 방사커널(radial basis kernel) 등이 주어진다. 만일 두 Input X1,X2 에 대해 2차원 다항커널(K(x,x′)=(1+⟨x,x′⟩)d)을 적용하면
가 되는데, 이를 basis expansion으로 나타내기 위해서는 M=6 으로 설정하여(basis function의 개수) h1(X)=1,h2(X)=2X1,…,h6(X)=2X1X2 로 다소 복잡한 설정이 필요하다. 이러한 방식으로 커널을 사용함으로써, SVM classifier의 solution function은 다음과 같이 주어진다.
f^(x)=i=1∑Nα^iyiK(x,xi)+β^0
SVM Regression
SVM은 앞서 살펴보았듯이 근본적으로 초평면을 이용해 관측 데이터셋을 분류하는 모델이다. 그러나 분류 과정에서 SVM classifier의 몇몇 아이디어들을 어느 정도 차용한다면, SVM을 회귀 문제에도 적용시킬 수 있다. 우선 다음과 같은 선형회귀모형을 생각하고
f(x)=xTβ+β0
이를 바탕으로 nonlinear한 일반화 과정을 다루어보도록 하자. 즉, β를 추정하는 과정에서 linear한 방법을 사용하는 것이 아닌 비선형함수 V를 이용해 다음과 같은 함수 H를 최소화하는 것이다.
H(β.β0)=i=1∑NV(yi−f(xi))+2λ∥β∥2
이때 비선형함수 V는 회귀모형에서 실제값과 예측값을 측정하는 일종의 손실함수인데, 이중 하나로 다음과 같은 ϵ-insensitive error measue
Vϵ(r)=(∣r∣−ϵ)⋅I[∣r∣≥ϵ]
을 사용할 수 있다. 이는 말 그대로 특정 값(epsilon) 이하의 오차를 무시하는 계산 방식인데, 앞서 살펴본 SVM classifier가 support vector를 제외한(결정경계로부터 멀리 떨어져있는) 관측값들을 무시하는 계산방식으로부터 유추된 것이다. 그런 의미에서 이를 support vector error measure라고도 부른다. 반면, Huber에 의해 제안된 error measure VH는
VH(r)={r2/2c∣r∣−c2/2if∣r∣≤c∣r∣>c
로 주어지는데 이는 정해진 상수 c보다 큰 절대오차를 감소시켜 전체적으로 f(x)의 fitting 과정을 outlier들에 덜 민감하게끔 해준다. 이러한 방식들을 이용해 함수 H를 최소화하는 minimizer β^,β^0을 구하면