Statistical Learning
1.Linear Regression
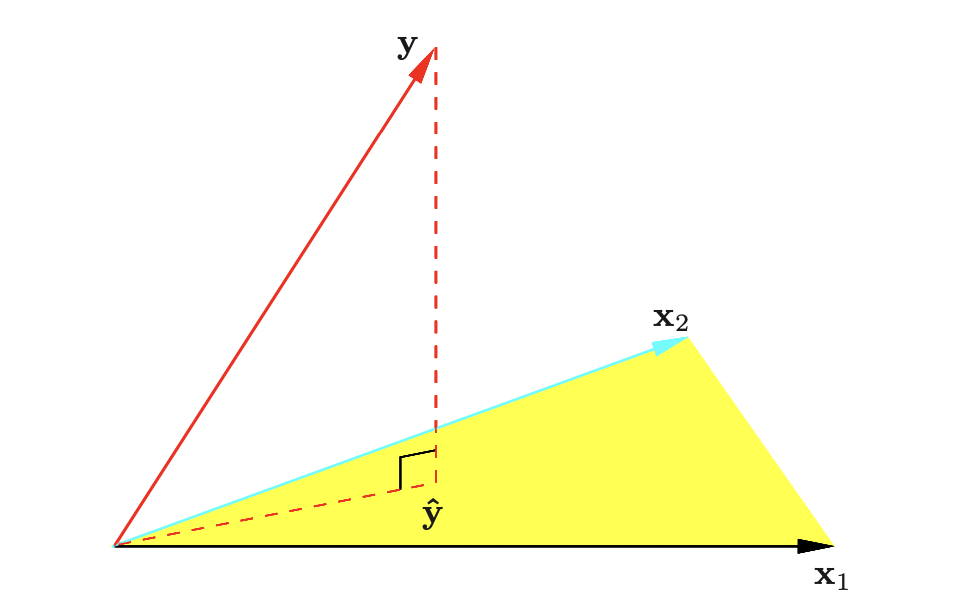
선형회귀는 통계적 학습의 고전적인 방법이다. 하지만 문학에서의 고전 명작과 마찬가지로 현대의 수많은 머신러닝 기법들의 가장 기초가 된다. 또한 Simple is best 라는 말과 같이, 때로는 선형관계가 명확한 데이터에서 가장 효율적으로 작동하기도 한다. 이번 포스팅
2.Linear Regression - PCR, CCA

이전 포스트에서는 주어진 변수들을 그대로 사용하여 회귀분석하는 다양한 방법을 다루었다. 이번 포스팅에서는 주어진 변수들을 기반으로 새로운 변수들을 만들어 회귀분석을 진행하는 방법을 다루어보도록 한다. 주성분(Principal Components)의 본래 의미는 In
3.LDA
Linear Classification 이번 포스트부터는 선형 방법으로 분류 문제를 해결하는 방법들에 대해 살펴보고자 한다. 여기서 분류classification 문제란, 종속 변수와 예측값 $G(x)$ 가 이산집합 $\mathcal{G}$의 원소를 갖는 문제를 의미한
4.LDA (2)
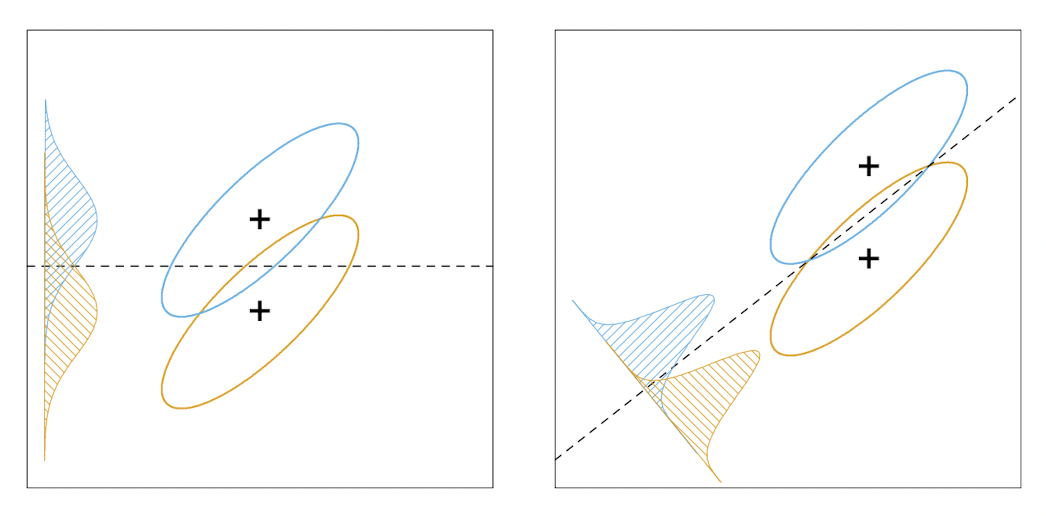
LDA의 다른 관점이전 포스트에서 살펴본 것 처럼, LDA는 데이터셋의 정규성을 가정하여 분류하는 방법이다. 이를 제한된 가우시안 분류기restricted gaussian classifier라는 관점으로 본다면, 이번에 다룰 내용은 LDA가 데이터를 저차원으로 투영시켜
5.Logistic Regression
로지스틱 회귀분석은 회귀분석의 일종으로 보기 쉽지만, 사실 분류문제의 사후확률을 선형함수로 표기한것에서 비롯되기 떄문에 분류기법으로 보는 것이 더 정확하다. 즉, 각 데이터 $X=x$ 가 클래스 $G=k\\;(k=1\\cdots K)$ 를 가질 확률을 비율로 치환(한개
6.Splines
기저 확장이란 데이터셋 $\\mathbf{X}$의 각 벡터 $X\\in\\mathbf{X}$에 새로운 변수를 추가하거나, 기존 변수를 대체하는 방법으로 새로운 모형을 구성하는 것이다. 총 M개의 변환이 존재한다고 하고, 이떄 $m$번째($m= 1,\\ldots,M$)
7.Model Assessment
우리가 어떤 머신러닝 모델을 만들었을 때, 모델의 성능은 어떻게 측정할 수 있을까🤔? 간단히 생각해보면, 서로 다른 데이터셋들에 대해 모델의 정확도를 측정하고, 이들을 종합해서 지표화하면 될 것이다. 이때 데이터셋들은 확률적으로 독립이어야 할 것이다. 모델의 성능을
8.Model Assessment
우리가 어떤 머신러닝 모델을 만들었을 때, 모델의 성능은 어떻게 측정할 수 있을까🤔? 간단히 생각해보면, 서로 다른 데이터셋들에 대해 모델의 정확도를 측정하고, 이들을 종합해서 지표화하면 될 것이다(이때 데이터셋들은 확률적으로 독립이어야 할 것이다). 모델의 성능을
9.Bootstrap
Bootstrap 방법은 정확도(accuracy)를 측정하기 위해 사용되는 일반적인 방법이다. Cross-validation과 마찬가지로 bootstrap은 (conditional) test error $\\text{Err}\_\\mathcal T$ 를 추정하기 위해
10.Tree
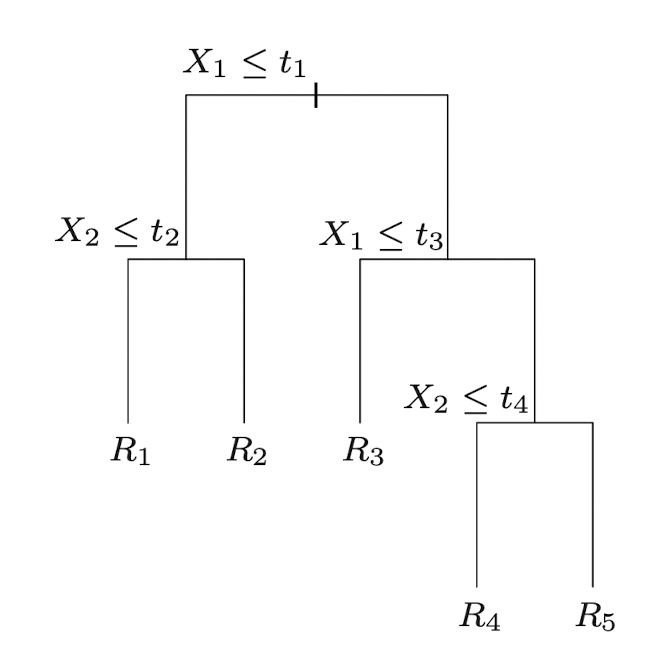
Tree를 이용한 알고리즘은 기본적으로 Feature space특성공간을 직사각형들의 집합으로 분할partition하고, 각 집합들에 대해 매우 간단한 모델(e.g. constant)을 적용하는 원리이다. Tree를 기반으로 한 알고리즘에는 CART, ID3, C4.5
11.Boosting
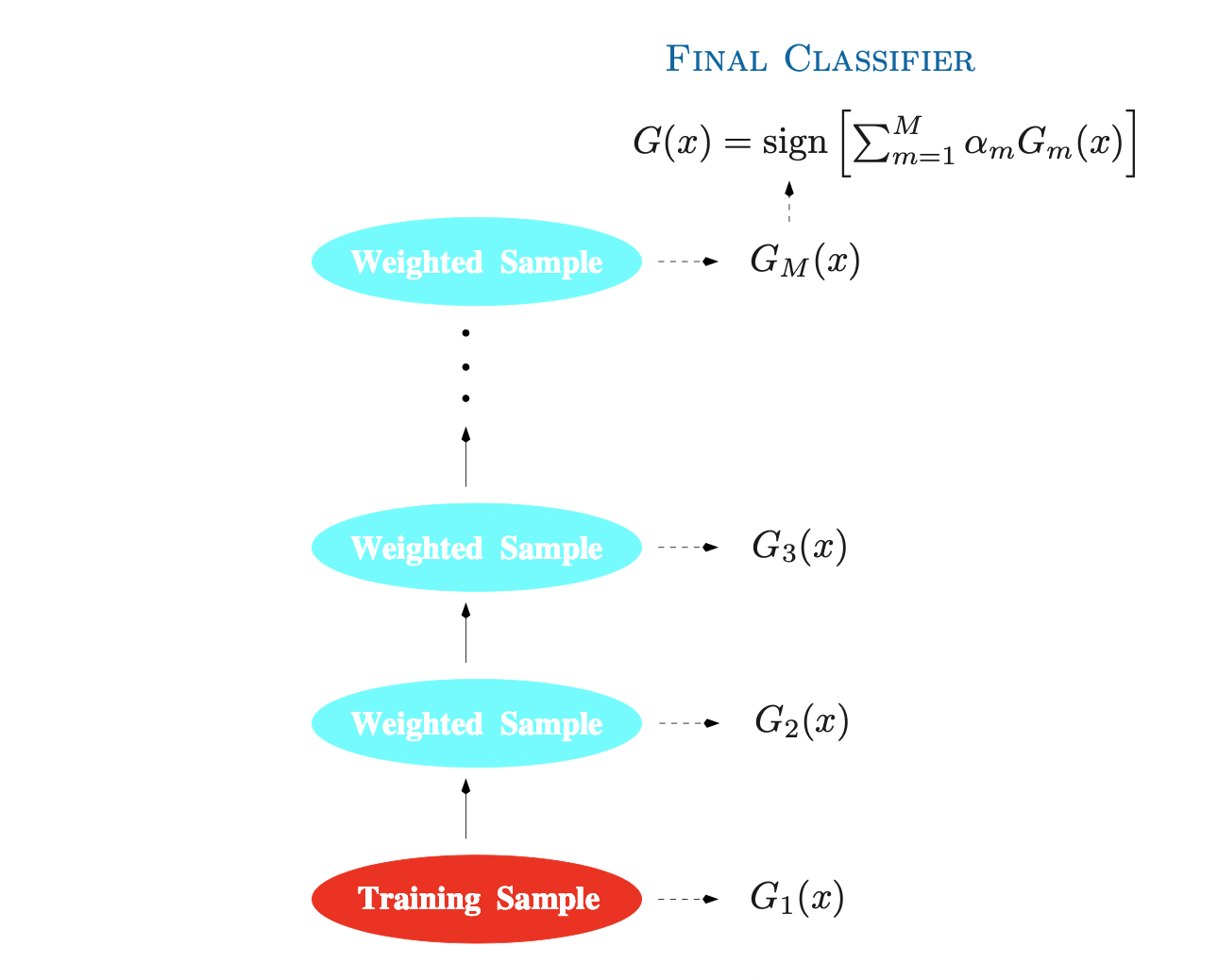
Boosting부스팅 은 21세기부터 statistical learning의 주요한 모델로 사용되고 있는 방법이다. 초기에는 분류 모델에 주로 이용되었으나, 회귀 문제에까지 확장되어 사용된다. Boosting 방법들의 핵심 아이디어는 기본적인 Ensemble 기법, 즉
12.Gradient Boosting Machine

이번 글에서는 Boosting 알고리즘과 관련하여, 특히 함수추정과 예측 문제에서 뛰어난 성능을 보이는 Gradient Boosting Machine에 대해 살펴보고자 한다. 여기서는 GBM을 제안한 Jerome H. Friedman의 Greedy Function Ap
13.Random Forest
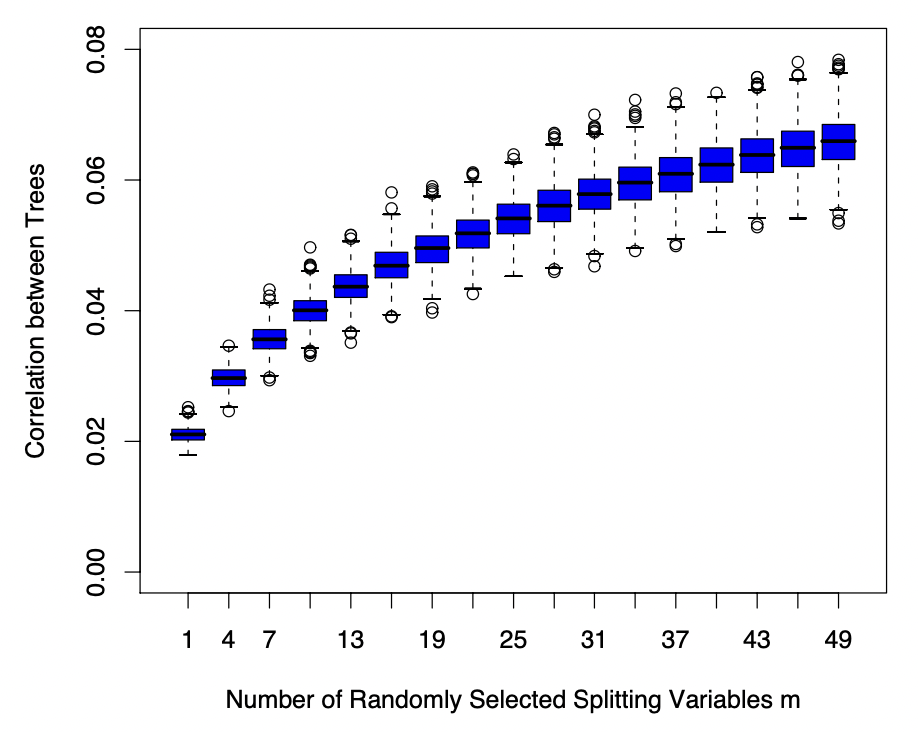
Random Forest는 Bagging배깅 방식을 이용한 Tree algorithm의 일종이다. 즉, 서로 상관관계가 없는(de-correlated, randomized) tree들을 매우 많이 생성하여, 이들의 평균값을 바탕으로 분류 혹은 회귀를 진행하는 알고리즘이
14.Support Vector Machine
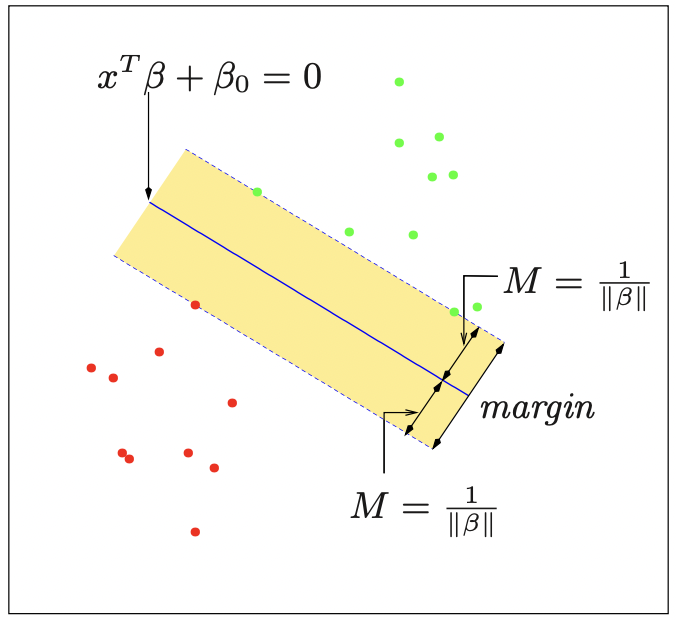
이전에 Linear Classification에서 Fischer's LDA에 대해 다룬 적 있었다. 이는 특성공간에서 데이터들을 분류하기 위한 선형 경계를 만드는 것인데, support vector classifier/machine은 이와 유사하나 비선형인 결정경계를