📌 LangChain이란?
대규모 언어 모델(LLMs)을 활용해 체인을 구성하여, 복잡한 작업을 자동화하고 쉽게 수행할 수 있도록 돕는 라이브러리이다.
그냥 OpenAI나 transformers 직접 쓰면 되지, 왜 굳이 LangChain을사용할까?
1. Chain으로 LLM 사용을 조합하기 위해 (LLM 호출, 프롬프트 구성, 출력 파싱, 메모리등 여러 단계를 연결해서 처리 가능)
2. 구성요소가 모듈화 되어있음 (모델, 프롬프트, 출력 파서, 메모리 등 모두 독립적인 객체로 관리)
3. 메모리, Tool, Agent와 같은 고급기능 제공
4. 복잡한 RAG, 멀티모달, 워크플로우에 유리
📍 LangChain의 구성요소
- 모델
- 프롬프트
- 인덱스: 벡터DB
- 메모리
- 체인
- Agent와 Tools
이번 포스팅에서는 LangChain의 모델, 프롬프트, 메모리에 대해 알아보려고 한다. 그리고 메모리와 모델을 연결하면서 체인도 잠깐 보일 예정이다.
벡터DB는 추후에 RAG를 공부할 때, 그리고 Agent와 Tools는 LangGraph를 공부할 때 다뤄볼 예정이다.
1. 모델
다양한 LLM을 통합하고 상호작용하는 데 사용한다.
이 컴포넌트를 통해 개발자는 여러 모델을 쉽게 전환하고 비교할 수 있다.
- OpenAI에서 제공하는 모델 사용하는 방법
from langchain_openai import ChatOpenAI chat = ChatOpenAI(model_name = 'gpt-4o-mini') - HuggingFace 모델 사용하는 방법
llm = HuggingFaceHub( repo_id="google/flan-t5-base", # 사용할 모델 이름 model_kwargs={"temperature": 0.5, "max_new_tokens": 100}, task = 'text-generation' )
1-1. 답변의 다양성과 무작위성 제어
LLM은 답변을 생성할 때 내부적으로 각 단어 후보마다 로짓(logits)을 계산한 뒤에, 이를 softmax 함수로 확률로 변환하여 확률이 높은 단어를 선택한다.
답변의 다양성과 무작위성을 제어하기 위해 다음과 같은 기법을 사용할 수 있다.
🌡️ temperature
확률 분포 자체를 조절하는 방법이다. 0(날카로움) 혹은 1 이상(넓음)으로 설정하면 된다.
낮은 값(0) : 항상 가장 확률이 높은 단어를 선택한다. -> 출력이 일관되고 예측 가능하다.
높은 값(1 이상) : 확률에 따라 무작위로 단어를 선택하므로 확률이 낮은 단어도 선택할 가능성이 있다. -> 창의적이지만, 결과가 불안정하다.
-
일반적으로 다음과같이 사용한다.
값 의미 사용 예시 0 가장 보수적, 항상 같은 답 논리적 답변, 코드 생성 0.3 ~ 0.7 적당히 창의적 일상 대화, 설명문 1 이상 매우 창의적 시, 이야기, 브레인스토밍 -
코드
모델을 선언할 때temperature파라미터에 지정해주면 된다.llm = ChatOpenAI(model_name = 'gpt-4o-mini', temperature=0.1)
🏆 top_p
후보 단어들의 확률을 내림차순으로 정렬한 뒤, 맨 위에서부터 누적확률이 p이하가 되는 부분까지의 단어를 모아 선택 후보로 삼는다.
-
예시) top_p=0.9 : 상위 확률 단어들을 누적하여 총합이 0.9가 넘기 전까지 후보로 사용
후보 단어 확률 밥을 0.4 학교에 0.25 운동을 0.15 일찍 0.1 고양이를 0.05 빨래를 0.02 잔다 0.02 청소를 0.01 여기에서 밥을(0.4)+학교에(0.25)+운동을(0.15)+일찍(0.1) = 총 0.9이므로 이 4개의 단어가 후보가 된다.
-
코드
llm = ChatOpenAI(model_name = 'gpt-4o-mini', model_kwargs={"top_p": 0.8})추가) top_k
자주 사용하는 OpenAI는 top_p를 사용하기 때문에 top_p만 다루었지만,
확률이 가장 높은 K개의 단어만 후보로 두는 top_k라는 개념도 존재한다는 것을 추가로 알아두자.
2. 프롬프트
인간이 인공지능(LLM)에게 전달하는 지시문으로, 모델의 응답을 결정짓는 핵심 입력이다.
- 프롬프트의 역할
- LLM에게 무엇을 할지 설명한다.
- 질문, 명령, 조건 등을 포함
- LLM의 출력품질을 좌우하는 가장 중요한 요소
📍 PromptTemplate
LangChain에서 프롬프트를 템플릿 형태로 추상화한 클래스
사용자 입력을 동적으로 삽입할 수 있는 문자열 포맷 객체
⌨️ 코드
# 프롬프트 템플릿
prompt = PromptTemplate(
input_variables=["text", "language"], # 변수 이름 정의
template="{language} 언어로 번역해 : {text}"
)
# LLM 연결
llm = ChatOpenAI(model_name = 'gpt-4o-mini' ,temperature = 0)
chain = LLMChain(prompt=prompt, llm=llm)
# 실행
print(chain.run({"text": "I love Gen AI", "language": "일본어"}))- 유동적템플릿 생성 가능
- 변수만 바꿔서 다양한 결과 실험 가능
- 객체화, 재사용, 체인과 결합 가능
- LLMChain이나 AgentChain같은 구조와 연결할 때 핵심 역할
🌟 ChatPromptTemplate
시스템 메세지, 사용자 메세지, AI 메세지 등 역할(role) 구분
다중 메세지 기반의 프롬프트 흐름을 구성할 수 있도록 도와주는 템플릿
메세지를 좀 더 구조화해서 관리 가능
- 메세지 종류
-SystemMessage: AI에게 역할/성격을 지정
-HumanMessage: 사용자 질문 또는 요청
-AIMessage: AI 응답
⌨️ 기본 코드
s_msg = "너는 유능한 영양사야"
h_msg = "요즘 혈당스파이크 때문에 고민이 많아. 혈당스파이크 피하려면 어떤 식단을 짜야할까?"
chat_prompt = ChatPromptTemplate.from_messages([
("system", s_msg),
("human", h_msg),
])
llm = ChatOpenAI(model_name = 'gpt-4o-mini', temperature=1.1, model_kwargs={"top_p": 0.95})
messages = chat_prompt.format_messages() # 실제 메시지 객체 리스트를 생성
response = llm(messages)
print(response.content)2-1. Output Parser
Output Parser로 LLM의 응답을 구조화할 수 있다. 즉, 출력 형식을 지정할 수 있다.
LLM은 기본적으로 문자열(string)을 반환하지만, Output Parser로 리스트, 딕셔너리, JSON 형식으로 받아올 수 있다.
입력 프롬프트를 구성할 때 SystemMessage에 출력 형식에 대한 지시 문장을 포함시키는 방식이다. 따라서LLM이 100% 이 형식으로 가져온다는 보장은 못하지만, 대부분은 형식을 지켜서 반환해준다고 한다.
📍 CommaSeparatedListOutputParser
쉼표로 구분된 문자열로 출력해서, 리스트로 파싱해서 사용할 수 있게 도와주는 파서이다.
코드로 이해하는 게 더 빠르니 코드를 바로 확인해보자.
-
코드
from langchain.output_parsers import CommaSeparatedListOutputParser # 1. 출력 파서 선언 parser = CommaSeparatedListOutputParser() # 2. 입력 프롬프트 구성 prompt = ChatPromptTemplate.from_messages([ ("system", "너는 사용자 취향을 정리해주는 전문가야."), ("human", "10대 남학생들이 좋아하는 음식 5가지를 말해줘."), ("system", "{format_instructions}") ]) # 3. 프롬프트 구성 formatted_messages = prompt.format_messages( format_instructions=parser.get_format_instructions() ) llm = ChatOpenAI(model_name = 'gpt-4o-mini', temperature=0.5, model_kwargs={"top_p": 0.95}) response = llm.invoke(formatted_messages) print(parser.parse(response.content))- 결과

이와 같이 알아서 나의 요청에 대해 콤마(,)로 구분해서 응답한 것을 확인할 수 있다.
- 결과
-
system message로 넘겨준 parser의
get_format_instructions()를 확인해보기parser.get_format_instructions()- 결과

이를 통해 우리가 직접 llm에게 요청으로 '콤마로 구분해줘'라는 명령 없이, 적절한 Output Parser를 선언하고 이미 정의된 지시문을 system message에 넣어주기만 하면 원하는 형식으로 응답을 받을 수 있다.
다른 Output Parser들도 같은 방식으로 작동한다.
- 결과
📍 StructuredOutputParser
LLM의 응답을 지정된 JSON 구조로 유도하고, 그 결과를 Python dict 자료형으로 파싱하도록 도와주는 OutputParser이다.
-
코드
# 1. 출력 스키마 정의 (뉴스 제목, 요약) schemas = [ ResponseSchema(name="headline", description="뉴스 제목"), ResponseSchema(name="summary", description="뉴스 내용을 한 문장으로 요약") ] # 2. 파서 생성 parser = StructuredOutputParser.from_response_schemas(schemas) # 3. 프롬프트 구성 (메시지 기반) prompt = ChatPromptTemplate.from_messages([ ("system", "너는 뉴스 요약 도우미야."), ("human", "2025년도의 흥미로운 IT 뉴스를 하나 소개하고 제목과 요약을 알려줘."), ("system", "{format_instructions}") # 여기서 파서가 제공한 형식 안내문이 들어감 ]) # 4. 실제 메시지 포맷팅 messages = prompt.format_messages( format_instructions=parser.get_format_instructions() ) # 5. 모델 호출 llm = ChatOpenAI(model_name = 'gpt-4o-mini', temperature=0.5, model_kwargs={"top_p": 0.95}) response = llm.invoke(messages) # 6. 결과 파싱 (JSON → dict) result = parser.parse(response.content) print(result)- 결과
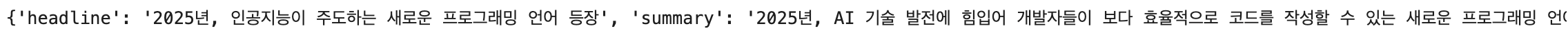
조금 결과가 잘렸지만, python의 dict 형태로 schema의 key와 value가 잘 들어가있는 것을 확인할 수 있다.
- 결과
- 코드 단계1) 출력 스키마 정의는, dict를 구성할 때 key 이름과, value에 담을 내용을 정의하는 부분이다.
- 코드 단계 3, 4) 프롬프트를 구성할 때 system message에 들어가는 안내문을 확인해보자
parser.get_format_instructions()

StructuredOutputParser가 1에서 정의한 schema를 바탕으로 JSON형식으로 구성하라는 지시문을 만들어준다는 것을 알 수 있다.
🌟 PydanticOutputParser
아마 가장 많이 쓰게될 OutputParser일 것이다. (그래서 앞에 🌟을 붙여보았다 ㅎㅎ)
왜냐하면 LLM의 응답 결과를 받을 데이터의 구조(스키마)를 정의하고, 타입에 맞게 잘 들어갔는지 자동으로 검증(validation)까지 수행해주기 때문이다.
-
코드
from pydantic import BaseModel from langchain.output_parsers import PydanticOutputParser # 1. Pydantic 모델 정의 class BookInfo(BaseModel): title: str author: str year: int # 2. 파서 생성 parser = PydanticOutputParser(pydantic_object=BookInfo) # 3. 프롬프트 구성 (ChatPromptTemplate 사용) prompt = ChatPromptTemplate.from_messages([ ("system", "너는 책 추천 전문가야."), ("human", "좋은 책 하나만 추천해줘. 제목과 저자, 출판년도를 알려줘."), ("system", "{format_instructions}") # 파서가 제공한 응답 형식 가이드 ]) # 4. 메시지 생성 messages = prompt.format_messages( format_instructions=parser.get_format_instructions() ) # 5. LLM 호출 및 파싱 llm = ChatOpenAI(model_name = 'gpt-4o-mini', temperature=0.5, model_kwargs={"top_p": 0.95}) response = llm(messages) book = parser.parse(response.content) # 6. 결과 출력 print(book)- 결과

1단계에서 정의했던 Pydantic 모델에 맞게 결과가 잘 파싱된 것을 확인할 수 있다.
- 결과
-
또 parser의
get_format_instructions()확인해보기

이 메세지는 JSON 스키마를 알려주고 그 스키마를 만족시키는 JSON 객체로 응답해달라는 지시문이다. 그리고 불필요한(Pydantic 모델에 정의되지 않은) key를 추가하지 않도록 요구하고 있다.
3. 메모리
대화의 맥락을 이어나가기 위해서는 이전 대화를 기억해야한다. 하지만 메모리가 없으면, LLM은 이전 대화를 기억하지 못한다. 다음과 같은 예시를 보자.
llm = ChatOpenAI(model_name = 'gpt-4o-mini' ,temperature = 0.5)
result = llm.invoke("안녕? 나는 땡글희야.")
print(result.content)
result = llm.invoke("내 이름이 뭐라고?")
print(result.content)
나의 이름을 알려준 뒤에, 아주 바로 나의 이름을 물어봤더니 모르쇠하는 걸 확인할수 있다.
따라서, AI가 나의 이름을 기억하게 만드려면 메모리를 붙여주어야 한다.
챗봇은 이전 질문 답변을 메모리에 저장하고 이를 Prompt에 포함하는 방식으로 이전 대화를 기억한다.
한가지 주의할 점은, 체인으로 LLM과 엮어서 사용해야 한다. 즉, 체인이 있어야만 메모리를 달 수 있다.
그럼 LLM에 달 수 있는 메모리의 종류를 몇가지 알아보자.
📍 ConversationBufferMemory
모든 대화를 순차적으로 저장하는 메모리이다.
대화 길이가 짧고, 단순한 맥락을 유지하는 데에 적합하다.
-
활용 코드
from langchain.chains import ConversationChain from langchain.memory import ConversationBufferMemory # 메모리 선언 memory = ConversationBufferMemory() # llm 선언 llm = ChatOpenAI(model_name='gpt-4o-mini, temperature=0.5) # llm과 메모리 체인으로 엮기 chain = ConversationChain(llm=llm, memory=memory) # 대화 시작 print(chain.run("안녕? 나는 땡글희야.")) print(chain.run("내 이름이 뭐라고?")) -
결과

드디어 나의 이름을 기억해준다.☺️
-
대화하면서 쌓인 메모리 확인하기
# 메모리 확인 memory.chat_memory.messages
모든 대화 내용이 메모리에 그대로 쌓여있는 걸 확인할 수 있다.
📍 ConversationSummaryMemory
대화를 요약해서 저장하는 메모리이다.
긴 대화, 리소스 절약이 필요할 때 사용하기 적합하다.
내부적으로 요약용 LLM이 호출된다. (요약 범위: 이전 요약 + 새 메시지 요약해서 업데이트)
- 활용 코드
from langchain.memory import ConversationSummaryMemory
# 요약 메모리 생성 (요약용 LLM 필요)
llm = ChatOpenAI(model_name = 'gpt-4o-mini' ,temperature = 0.5)
memory = ConversationSummaryMemory(llm=llm)
# 체인 구성
chain = ConversationChain(llm=llm, memory=memory)
# 대화 - 이미지로 첨부

- 메모리에 담긴 내용 확인하기

- 메모리에 요약된 내용 확인하기
memory.load_memory_variables({})["history"]
대화내용을 요약해준 것을 확인할 수 있다.
📍 ConversationBufferWindowMemory
최근 N턴만 기억하는 메모리이다.
최신 문맥만 중요할 때 사용한다. (예시: 챗봇)
from langchain.memory import ConversationBufferWindowMemory
# 최근 2턴만 기억하는 메모리
memory = ConversationBufferWindowMemory(k=2)
chain = ConversationChain(llm=llm, memory=memory)
# 대화 - 사진으로 첨부대화가 좀 잘렸지만, 이해에는 큰 문제가 없을 것같아 그대로 첨부했다.
대화1

대화2

대화3

- 여기서부터 대화1의 내용이 메모리에서 사라진 것을 확인할 수 있다.
대화4

역시나 대화1의 내용인 "남자친구와의 약속시간을" 물어보니 모르겠다고 한다!
이로서 최근 2턴만 기억할 수 있다는 것을 확인할 수 있었다!
