📌 RAG란?
RAG는 LLM의 한계를 극복하기 위해 제안된 새로운 자연어 처리 기술이다. RAG의 개념을 알아보기 전에 LLM의 한계를 먼저 알아보도록 하자.
📍 LLM의 한계
- 지식의 유효성 부족
LLM은 사전 학습 데이터에 의존적이다. 즉, 학습 시점 이후의 정보를 반영하지 못하고, 학습하지 않은 데이터에 대해서는 제대로 대답하지 못한다. - 생성된 정보의 신뢰성 문제
LLM은 가끔 실제로 존재하지 않는 정보나, 잘못된 정보를 만들어내는 "할루시네이션(hallucination)" 문제가 있다. - 도메인 전문성 부족
LLM은 일반적인 답변을 제공하기 때문에, 심도있는 도메인 지식이 필요한 곳에서는 부족한 결과를 만들 수 있다.
RAG(Retrieval Augmented Generation)는 LLM이 기존 학습 데이터소스 이외에 외부 지식을 참조해서 답변을 생성하도록 하는 것이다.
RAG를 통해 LLM이 외부 지식을 통해 데이터를 최신으로 유지할 수 있으며, 응답 소스를 외부 지식으로 제한하게 되면 잘못된 정보를 제공할 가능성이 줄어들고, 특정 도메인의 지식과 결합하여 전문성을 보장할 수 있다.
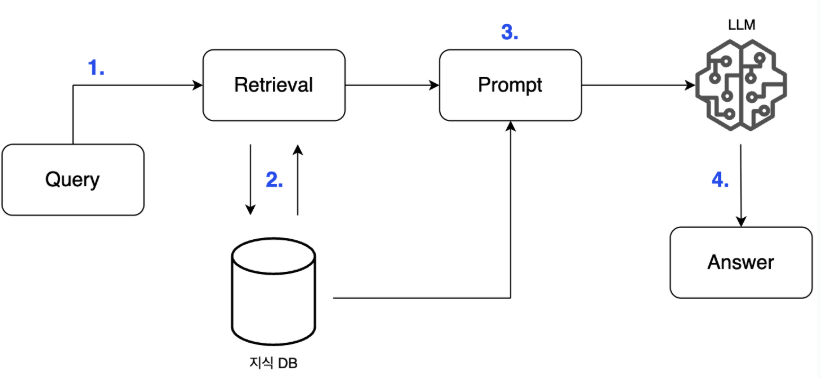
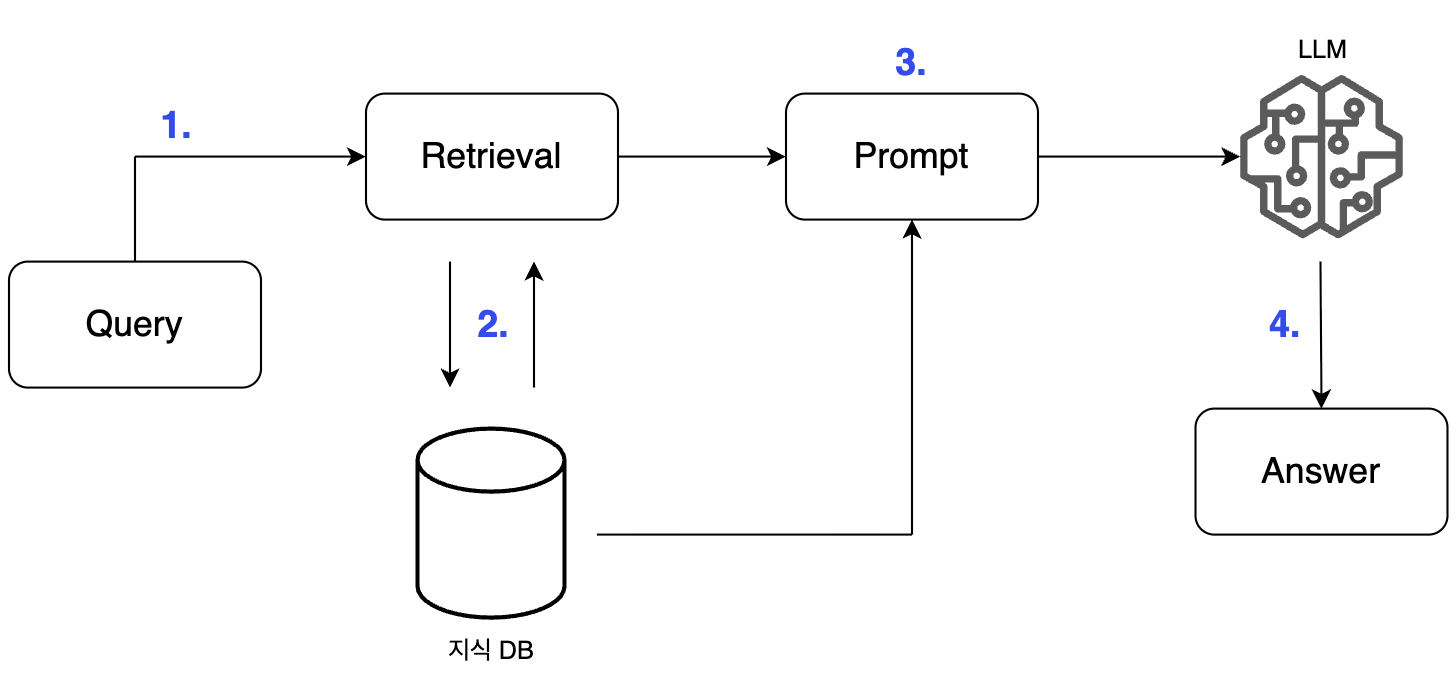
📌 LLM with RAG의 절차
- 사용자의 질문을 받는다.
- 지식DB에서 답변에 필요한 문서를 검색한다.
- 필요한 문서를 포함한 프롬프트를 생성한다.
- LLM이 답변을 생성한다.
📌 Vector DB
Vector DB(Vector Database)는 데이터를 벡터로 표현하고 이를 효율적으로 저장, 검색, 분석할 수 있는 데이터베이스이다.
RAG 절차의 2번에서, [질문 벡터]와 DB 내에 저장된 [문서 벡터]와 유사도를 계산하여 가장 유사도가 높은 문서 n개를 찾아내는 과정이 이루어진다. 여기서 Vector DB는 고차원 벡터 데이터를 검색하고 유사성을 비교하기 위한 데이터베이스라고도 할 수 있다.
따라서 Vector DB를 어떻게 구성하느냐가 RAG의 성능을 좌우한다.
📍 Vector DB 구축 절차
1️⃣ 텍스트 추출 (Loader)
Loader는 다양한 소스에서 문서를 불러오고 처리하는 과정을 담당한다.
Loader의 특징은 다음과 같다.
- 웹페이지, PDF, 데이터베이스, CSV 등 다양한 소스에서 문서를 불러올 수 있다.
- 불러온 문서 데이터를 분석하고 처리하여, 랭체인의 다른 모듈이나 알고리즘이 처리하기 쉬운 형태로 변환한다.
- 불필요한 데이터를 제거하거나 구조를 변경할 수 있다.
- 대량의 문서 데이터를 효율적으로 관리하고, 필요할 떄 쉽게 접근할 수 있게 한다.
-> 검색 속도 향상, 전체 시스템의 성능 향상
TextLoader, PDFLoader, CSVLoader 등이 있다.
-
PDFLoader 예시코드
from langchain.document_loaders import PyMuPDFLoader # PDF 파일 로드 pdf_path = "2025년 사이버 위협 전망 보고서.pdf" pdf_loader = PyMuPDFLoader(path + pdf_path) # 문서 로드 실행 documents_pdf = pdf_loader.load()documents_pdf는 Document 객체를 요소로 가지는 list이다.
하나의 Document 객체는 한 페이지의 내용을 담고 있다. 따라서documents_pdf의 크기는 pdf파일의 페이지 수이다.
이러한 구조 덕분에, pdf에 없는 추가하고 싶은 내용이 있다면 Document 객체를 구성해서 추가할 수 있다.
2️⃣ 텍스트 분할 (Splitter)
Splitter는 긴 문서를 청크(chunk)로 나누는 텍스트 분리 도구이다.
청킹(chunking)을 하는 이유는 다음과 같다.
- LLM 모델의 입력 토큰의 개수가 정해져 있기 때문이다.
(예를 들면 500 토큰씩 나눠 100개의 청크로 저장 → Vector DB에서 상위 5개의 유사 청크만 LLM에 입력 → 제한 내에서 효율적 처리 가능) - 텍스트가 너무 길면, 핵심 정보 이외에 불필요한 정보가 포함되어 RAG의 품질을 저하시킨다.
분할을 할 때 고려해야할 사항은 다음과 같다.
-
텍스트 분할 의미
청크가 독립적으로 의미를 갖도록 나눠야 한다. (ex. 문장, 구절, 단락 등 문서 구조 기준) -
청크 크기
LLM 모델의 입력 크기와 비용 등을 종합적으로 고려하여 최적 크기를 결정해야 한다. (ex. 단어 수, 문자 수 등 기준)
-
RecursiveCharacterTextSplitter 예시코드
from langchain.text_splitter import RecursiveCharacterTextSplitter # 텍스트 청크 분할 text_splitter = RecursiveCharacterTextSplitter( chunk_size=500, # 한 청크의 최대 길이 chunk_overlap=100, # 문맥 유지를 위한 오버랩 (겹치는 글자수) separators=["\n\n", "\n", ". "," "] # 문단 → 줄바꿈 → 문장 → 단어 순서로 분할 ) split_docs = text_splitter.split_documents(documents_pdf) # document 여러개 있는 list로 넘겨줘도 안에서 알아서 다 처리해줌
3️⃣ 텍스트 벡터화 (Embedding)
텍스트 데이터를 숫자로 이루어진 벡터로 변환하는 과정이다. 이때, 의미적인 정보를 보존하도록 설계되어 있다. 따라서 비슷한 의미를 가진 데이터는 가까운 위치에 놓인다.
-
임베딩 모델
OpenAI:text-embedding-ada-002,text-embedding-3-small
Microsoft:e5-large-v2
-
text-embedding-3-small 모델 선언 예시
from langchain.embeddings import OpenAIEmbeddings embedding_model = OpenAIEmbeddings(model="text-embedding-3-small")
4️⃣ Vector DB로 저장 (Vector Store)
임베딩 벡터들을 효율적으로 저장하고 검색할 수 있는 DB이다.
-
대표적인 Vector DB
Chroma,FAISS항목 FAISS Chroma 개발 주체 Facebook(Meta) ChromaDB(Open Source) 설치 faiss-cpu, faiss-gpu chromadb 벡터 저장 방식 메모리 중심, 영속성은 수동 디스크 기반, 자동 영속성(persist_directory) metadata 검색 불가능 지원 (filtering 조건 검색) 필터링 쿼리 없음 SQL-like filtering 가능 RAG 최적화 빠르고 가볍지만 로직 필요 LangChain과 궁합 좋음 사용 용도 대규모 벡터 빠른 검색 소/중규모 벡터 + RAG + 메타검색 문서 저장 문서 + 벡터 문서 + 벡터 + 메타데이터 -
Chroma 예시코드
from langchain.vectorstores import Chroma # ChromaDB를 만들면서 저장 vectorstore = Chroma.from_texts(split_docs, embedding_model, persist_directory="./chroma_db") -
쿼리로 유사도 확인하기 예시
query = "가장 심각한 사이버 보안 위험은 무엇입니까?" retrieved_docs = vectorstore.similarity_search(query, k=3) // 가장 유사한 3개 # 결과 출력 print("검색 결과:") for doc in retrieved_docs: print(doc.page_content) print('-'*200)질문을 던저서 적절한 문서를 가져오는지 확인해볼 수 있다.
📌 RAG 파이프라인 구축 절차
1️⃣ Retriever 선언
- Vector DB에서 사용자의 질문과 가장 유사한 문서(청크)를 검색
- 코사인 유사도(Cosine Similarity) 기반으로 유사한 문서 검색
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})2️⃣ LLM 모델 지정
- 검색된 문서와 함께 질문을 받아 답변을 생성할 LLM 모델을 지정
llm = ChatOpenAI(model_name="gpt-4o-mini")3️⃣ 메모리 선언
- 대화의 흐름을 유지하고, 이전 질문을 기억하여 문맥을 제공할 수 있도록 함
- 프롬프트 길이를 고려한 메모리 최적화도 필요
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True, output_key="answer")4️⃣ 체인 함수로 엮기
Retriever+LLM+Memory를 하나의 체인으로 연결하여 질문-응답 시스템 완성
a_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=retriever,
memory=memory,
return_source_documents=False # 검색된 문서 출력 옵션
)5️⃣ RAG 파이프라인 사용
# 테스트 실행
query = "랜섬웨어 공격 시 어떻게 대응해야 하나요?"
response = qa_chain({"question": query})
# 응답 출력
print("답변:", response["answer"])