개요
왜 ELK stack을 선택했는가?
MySQL만을 사용하여 검색 기능을 구현해도 되는데 왜 ELK를 도입하게 됐을까??
현재 프로젝트는 검색기능이 중요한 도메인이다. 따라서 검색기능을 고도화시킬 필요가 있다고 생각했다.
우선, MySQL을 사용한 검색의 정확도는 상대적으로 떨어진다. % LIKE %(인덱스 X!!) 나 Full-Text-Search를 활용하면 어느 정도 정확도를 향상시킬 수 있지만, 대용량 데이터 검색에서는 성능상의 한계가 존재한다.
이러한 문제를 해결하기 위해, 검색에 특화된 쿼리 전용 DB를 고려하게 되었고, 다른 NoSQL 대비 검색 성능에 탁월한 Elasticsearch를 선택하게 되었다. Elasticsearch는 역 인덱스를 활용하여 대용량 데이터를 신속하게 검색할 수 있는 구조로 되어 있어 이에 적합하다고 판단했다.
또한, Elasticsearch는 추후 대량의 트래픽 분산을 위한 뛰어난 확장성을 제공하고 Kibana를 이용해서 실시간으로 데이터를 모니터링하고 분석하는 등의 다양한 기능을 제공해주기 때문에 적합한 솔루션으로 판단되어 도입했다!
본격적으로 ELK stack을 사용하기 위한 환경 세팅을 해보자!
ELK version 7.17.8
이글에서는 ELK stack 환경을 세팅하는 두 가지 방법을 소개해 볼 예정이다.
-
직접 ELK stack을 설치하고 세팅하기
-
docker compose를 이용해서 빠르고 쉽게 세팅하기
ELK 직접 설치하기
자세한 사항은 reference 참조
elasticsearch: https://www.elastic.co/guide/en/elasticsearch/reference/7.17/deb.html
logstash: https://www.elastic.co/guide/en/logstash/7.17/installing-logstash.html
kibana: https://www.elastic.co/guide/en/kibana/7.17/deb.html
1. 다운로드 세팅
# ELK 패키지를 서명하는 GPG 공개키를 다운로드
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo gpg --dearmor -o /usr/share/keyrings/elasticsearch-keyring.gpg
# HTTPS 프로토콜을 사용하여 패키지 저장소에서 패키지를 다운로드할 수 있도록 apt-transport-https 패키지를 설치
sudo apt-get install apt-transport-https
# ELK 패키지 저장소를 추가 및 GPG 공개키를 사용하여 저장소에서 다운로드한 패키지가 서명 검증
echo "deb [signed-by=/usr/share/keyrings/elasticsearch-keyring.gpg] https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elastic-7.x.list2. Elasticsearch 설치하기
sudo apt-get update && sudo apt-get install elasticsearch3. Logstash 설치하기
sudo apt-get update && sudo apt-get install logstash4. Kibana 설치하기
sudo apt-get update && sudo apt-get install kibanaElasticsearch, Kibana 실행 시키기
Elasticsearch, Kibana 는 5.0버전 이후 부터 root 계정으로 기동할 수 없으므로 일반 계정을 생성해서 소유자를 변경 후 해당 계정으로 기동해야 한다
1. 유저 생성하기
useradd elastic
passwd elastic
# 비밀번호 입력2. 소유자 변경
# 해당 디렉토리와 그 하위 디렉토리들의 소유자를 elastic 사용자로, 그룹을 elastic 그룹으로 변경
sudo chown -R elastic:elastic /usr/share/elasticsearch
sudo chown -R elastic:elastic /usr/share/kibana
sudo chown -R elastic:elastic /etc/elasticsearch
sudo chown -R elastic:elastic /etc/kibana3. 기동
- user 변경
su elastic- Elasticsearch 기동
cd /usr/share/elasticsearch
./elasticsearch- Kibana 기동
cd /usr/share/kibana
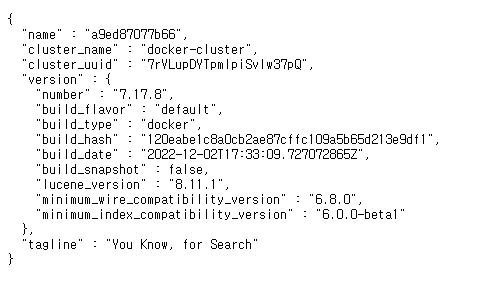
./kibana기동후에는 다음과 같은 화면을 볼수있다.
- Elasticsearch : http://localhost:9200/
- Kibana : http://localhost:5601/
Index 생성하기
이제 MYSQL의 Products 테이블을 Elasticsearch의 Index에 각 필드와 타입을 매핑시켜보자
우리는 product_name 와 product_content로 필드를 이용해서 상품 키워드를 검색할 것이다.
이때 product_name 과 product_content 필드를 검색을 nori 한글 형태소 분석기를 이용해서 한글 검색 결과의 정확도를 높여보자
1. nori 형태소 분석기 plugin 설치하기
sudo bin/elasticsearch-plugin install analysis-nori
2. index 정보 json 만들기
- my_index.json
{
"mappings": {
"properties": {
"@timestamp": {
"type": "date"
},
"@version": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"create_date": {
"type": "date"
},
"file_link": {
"type": "keyword",
"ignore_above": 256
},
"like_count": {
"type": "long"
},
"modify_date": {
"type": "date"
},
"product_as_expiration_date": {
"type": "date"
},
"product_category_no": {
"type": "long"
},
"product_content": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
},
"analyzer": "nori_discard"
},
"product_exchange_status": {
"type": "keyword"
},
"product_name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
},
"analyzer": "nori_discard"
},
"product_no": {
"type": "long"
},
"product_price": {
"type": "long"
},
"product_purchase_date": {
"type": "date"
},
"product_sales_status": {
"type": "keyword"
},
"product_status": {
"type": "keyword"
},
"product_stock": {
"type": "long"
},
"product_thumbnail_no": {
"type": "long"
},
"product_view_count": {
"type": "long"
},
"seller_no": {
"type": "long"
},
"unix_ts_in_secs": {
"type": "float"
}
}
},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "1",
"analysis": {
"analyzer": {
"nori_discard": {
"type": "custom",
"tokenizer": "nori_discard"
},
"nori_mixed": {
"type": "custom",
"tokenizer": "nori_mixed"
},
"nori_none": {
"type": "custom",
"tokenizer": "nori_none"
}
},
"tokenizer": {
"nori_discard": {
"type": "nori_tokenizer",
"decompound_mode": "discard"
},
"nori_mixed": {
"type": "nori_tokenizer",
"decompound_mode": "mixed"
},
"nori_none": {
"type": "nori_tokenizer",
"decompound_mode": "none"
}
}
},
"number_of_replicas": "1"
}
}
}
3. 인덱스생성하기
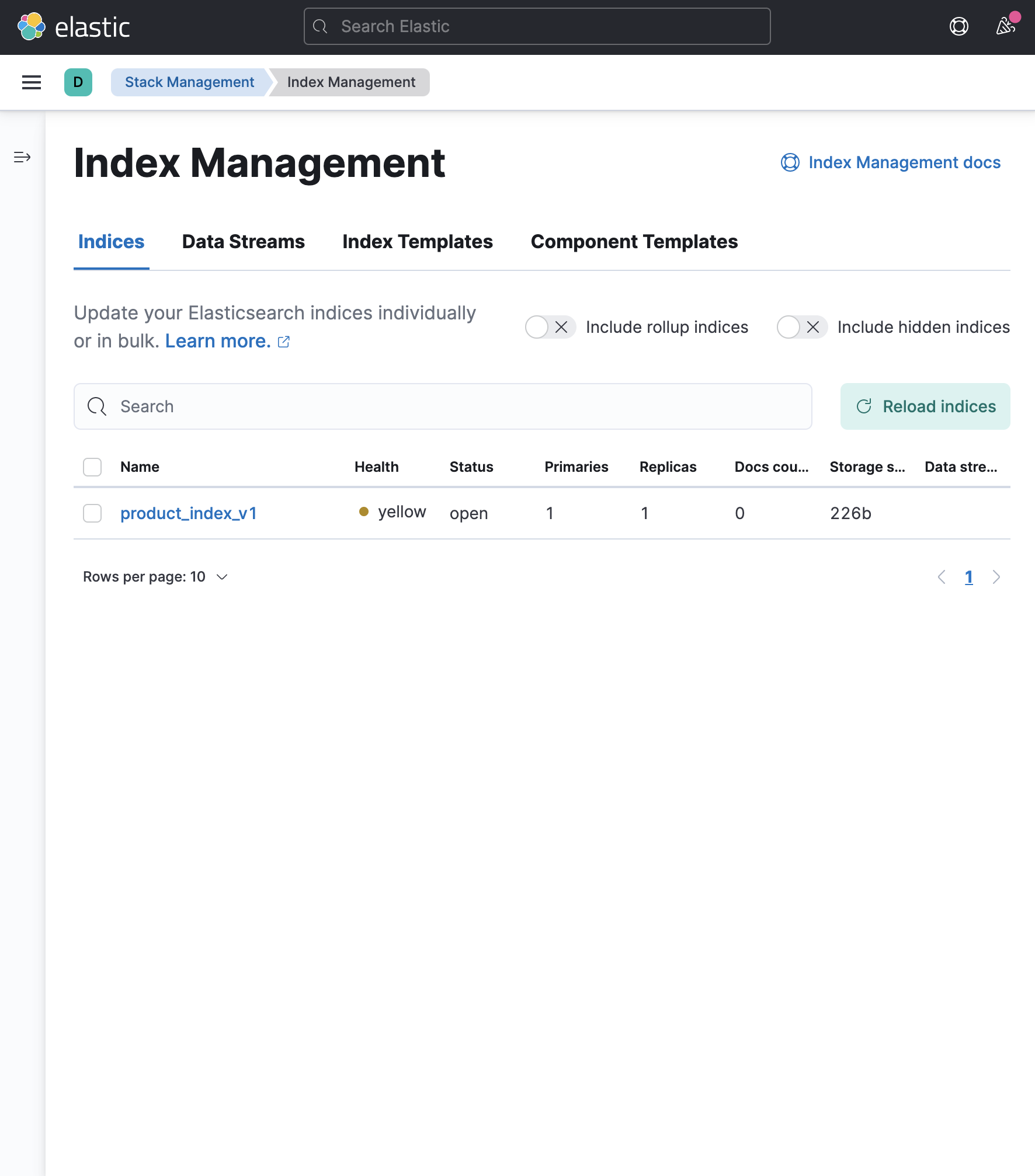
curl -XPUT localhost:9200/product_index_v1?pretty=true -d @my_index.json -H "Content-Type:application/json"4. Index 생성확인하기
- kibana > Stack Management > Index Management 에서 생성된 Index를 볼수있다.
MYSQL 데이터 연동하기
Logstash를 이용해서 Elasticsearch에 데이터를 밀어 넣어보자
먼저 Logstash에서 필요한 jdbc 드라이버를 다운받자
1. mysql-connector-java-8.0.21.jar 다운로드
wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.21/mysql-connector-java-8.0.21.jar2. jdbc 플러그인 설치
pwd
# /usr/share/logstash/bin
./logstash-plugin install logstash-integration-jdbc
# 설치확인
./logstash-plugin list | grep logstash-integration3. Logstash *.conf 파일 생성
conf 파일이란 ?
Logstash 설정파일을 말한다.
.conf 파일에는 입력(input), 필터(filter), 출력(output)에 대한 설정이 포함된다. 입력 설정은 Logstash 데이터를 수집할 소스에 대한 정보를 제공하며, 필터 설정은 데이터를 처리하는 방법을 지정한다. 마지막으로 출력 설정은 처리된 데이터를 전송할 대상에 대한 정보를 제공한다.
input {
jdbc {
#jdbc driver 파일위치
jdbc_driver_library => "/usr/share/java/mysql-connector-java-8.0.21.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://ip:port/mymarket"
jdbc_user => "username"
jdbc_password => "비밀번호"
jdbc_paging_enabled => true
tracking_column => "unix_ts_in_secs"
use_column_value => true
tracking_column_type => "numeric" # numberic , timestamp
statement => "SELECT p.*, pi.file_link, UNIX_TIMESTAMP(p.modify_date) AS unix_ts_in_secs
FROM (SELECT *
from products
WHERE (modify_date > FROM_UNIXTIME(:sql_last_value, '%Y-%m-%d %H:%i:%s') AND modify_date < NOW())
ORDER BY modify_date
limit 1000) p
left join product_images pi on p.product_thumbnail_no = pi.image_no"
# 주기설정 2초마다 한번
schedule => "*/2 * * * * *"
#clean_run => true #sql_last_value 초기화
last_run_metadata_path => "/usr/share/logstash/.logstash_jdbc_last_run"
}
}
filter {
mutate {
copy => {"product_no" => "[@metadata][_id]"}
}
}
output {
# stdout {}
elasticsearch {
hosts => "http://localhost:9200" #"http://elasticsearch:9200"
index => "products_index_v1"
document_id => "%{[@metadata][_id]}"
}
}우리는 Elasticsearch의 최종적 일관성을 보장해 주어야 하므로 다음과 같이
modify_date > FROM_UNIXTIME(:sql_last_value,%Y-%m-%d %H:%i:%s) AND modify_date < NOW()처럼 두 가지의 조건을 함께 사용해야 한다.
추가로 데이터가 많을 때 해당 쿼리 자체가 느려 질 수 있기 때문에 index를 타도록 잘 설계해야 한다.참고
4. Logstash 실행
sudo ./logstash -f my_log.conf 5. Data Stream 확인하기
6. 검색해보기
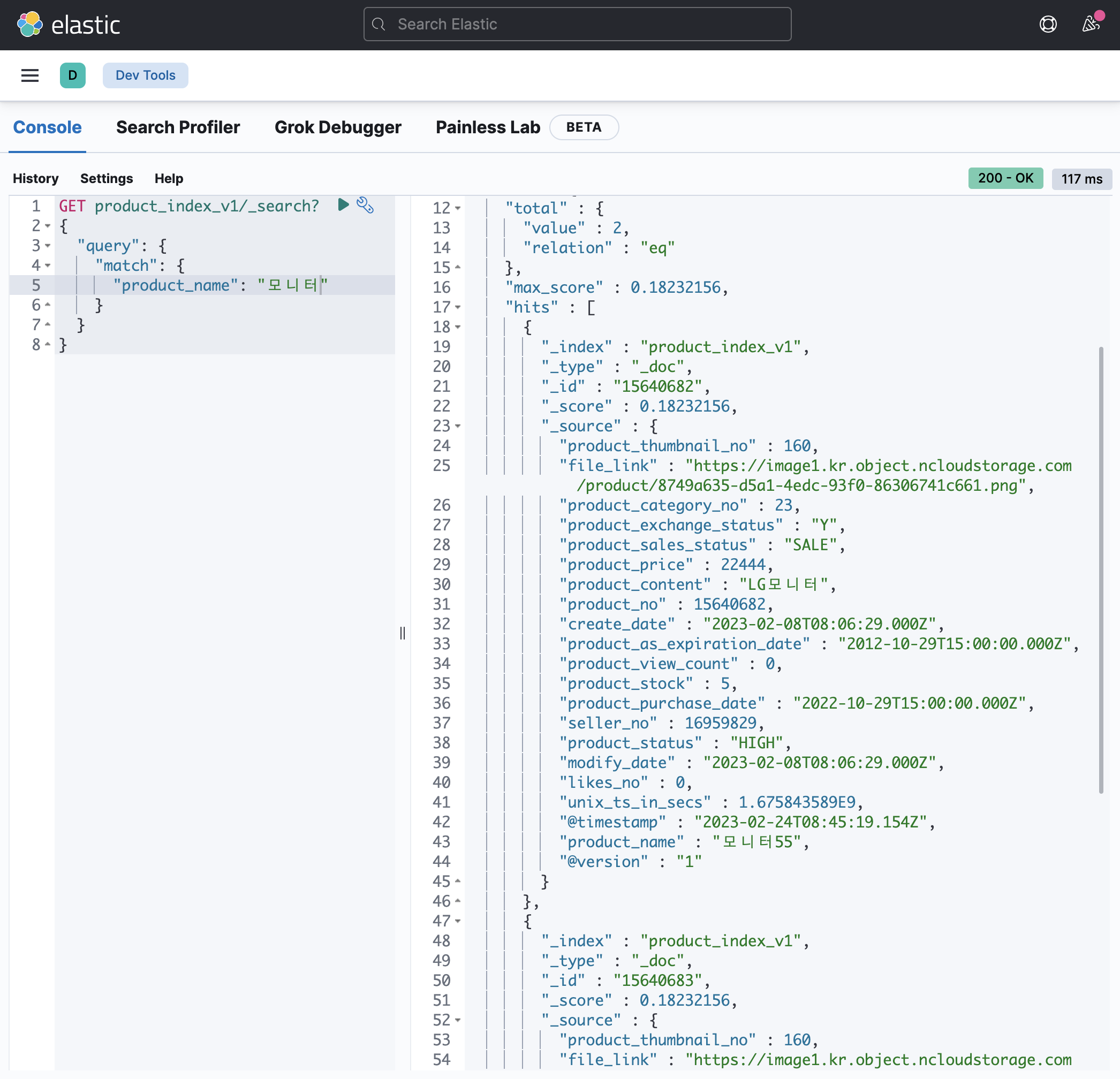
troubleshooting
만약 ELK 기동중에 OOM이 발생하는경우
Elasticsearch, Logstash Heap size를 적절하게 조절해주자참고
https://esbook.kimjmin.net/02-install/2.3-elasticsearch/2.3.1-jvm.options
Docker를 이용해서 간단하게 ELK stack 환경 세팅하기
이번에는 Docker compose를 이용해서 ELK stack 환경을 세팅해보자
해당 repo를 clone 한 후에 필요한 것들을 설정 후에 사용하면된다.
필자는 먼저 위의 세팅과 똑같이 할 것이다.
clone후에 먼저 내가 원하는 설정을 yml과 Dockerfile을 수정하면된다.
1. repo clone하기
git clone https://github.com/ksundong/docker-elk-kor2. 환경변수 변경하기
#.env
ELK_VERSION=7.17.83. 설정 변경하기
-
repo > elasticsearch
- Dockerfile 수정하기
ARG ELK_VERSION FROM docker.elastic.co/elasticsearch/elasticsearch:${ELK_VERSION} #현재 디렉토리에 있는 /my_index.json 파일을 컨테이너 내부 /usr/share/elasticsearch/bin에 copy COPY /my_index.json /usr/share/elasticsearch/bin #nori 형태소 분석기 plugin 설치 RUN elasticsearch-plugin install analysis-nori- index json 파일 Dockerfile과 같은 위치에 놓기
-
repo > logstash
- Dockerfile 수정하기
ARG ELK_VERSION FROM docker.elastic.co/logstash/logstash:${ELK_VERSION} #현재 디렉토리에 있는 mysql-connector-java-8.0.21.jar 을 컨테이너 내부 /usr/share/java에 copy COPY /mysql-connector-java-8.0.21.jar /usr/share/java
- Dockerfile 수정하기
-
repo > logstash > pipeline
- logstash.conf 수정하기
input { jdbc { #jdbc driver 파일위치 jdbc_driver_library => "/usr/share/java/mysql-connector-java-8.0.21.jar" jdbc_driver_class => "com.mysql.cj.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://ip:port/mymarket" jdbc_user => "username" jdbc_password => "비밀번호" jdbc_paging_enabled => true tracking_column => "unix_ts_in_secs" use_column_value => true tracking_column_type => "numeric" # numberic , timestamp statement => "SELECT p.*, pi.file_link, UNIX_TIMESTAMP(p.modify_date) AS unix_ts_in_secs FROM (SELECT * from products WHERE (modify_date > FROM_UNIXTIME(:sql_last_value, '%Y-%m-%d %H:%i:%s') AND modify_date < NOW()) ORDER BY modify_date limit 1000) p left join product_images pi on p.product_thumbnail_no = pi.image_no" schedule => "* * * * * *" #clean_run => true #sql_last_value 초기화 last_run_metadata_path => "/usr/share/logstash/.logstash_jdbc_last_run" } } filter { mutate { copy => {"product_no" => "[@metadata][_id]"} } } output { elasticsearch { #"http://elasticsearch:9200" hosts => "http://localhost:9200" index => "products_index_v1" document_id => "%{[@metadata][_id]}" } }
- logstash.conf 수정하기
-
repo
-
docker-stack.yml 수정하기
version: '3.3' services: elasticsearch: image: docker.elastic.co/elasticsearch/elasticsearch:7.17.8 ports: - "9200:9200" - "9300:9300" configs: - source: elastic_config target: /usr/share/elasticsearch/config/elasticsearch.yml environment: ES_JAVA_OPTS: "-Xmx1G -Xms1G" #ELASTIC_PASSWORD: password discovery.type: single-node networks: - elk deploy: mode: replicated replicas: 1 #index 자동생성 command 실행 command: > bash -c "curl -XPUT localhost:9200/product_index_v1?pretty -H 'Content-Type: application/json' -d @/usr/share/elasticsearch/bin/my_index.json" logstash: image: docker.elastic.co/logstash/logstash:7.17.8 ports: - "5044:5044" - "5000:5000" - "9600:9600" configs: - source: logstash_config target: /usr/share/logstash/config/logstash.yml - source: logstash_pipeline target: /usr/share/logstash/pipeline/logstash.conf environment: LS_JAVA_OPTS: "-Xmx1G -Xms1G" networks: - elk deploy: mode: replicated replicas: 1 kibana: image: docker.elastic.co/kibana/kibana:7.17.8 ports: - "5601:5601" configs: - source: kibana_config target: /usr/share/kibana/config/kibana.yml networks: - elk deploy: mode: replicated replicas: 1 configs: elastic_config: file: ./elasticsearch/config/elasticsearch.yml logstash_config: file: ./logstash/config/logstash.yml logstash_pipeline: file: ./logstash/pipeline/logstash.conf kibana_config: file: ./kibana/config/kibana.yml networks: elk: driver: overlay
-
4. Docker 실행하기
docker-compose up -dELK stack 보안 기능 구성하기
ELK stack에 아무나 접근할 수 없도록 비밀번호를 추가해보자
1. p12 인증서 생성하기
cd /usr/share/elasticsearch/bin/
./elasticsearch-certutil cert -out /etc/elasticsearch/elastic-certificates.p12 pass "" ##pass "" 입력 안할시 비밀번호 입력
# 권한 변경
chmod g+rw elastic-certificates.p12
2. elasticsearch.yml 수정 하기
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: elastic-certificates.p12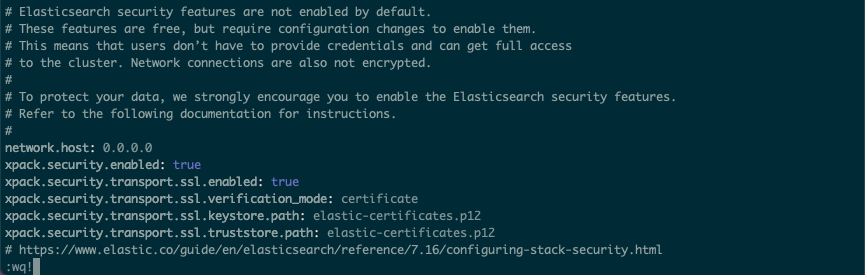
3. service 재실행 하기
cd /usr/share/elasticsearch/bin/
./elasticsearch4. 접속에 사용할 비밀번호 설정하기
cd /usr/share/elasticsearch/bin
./elasticsearch-setup-passwords interactive
# 비밀번호 입력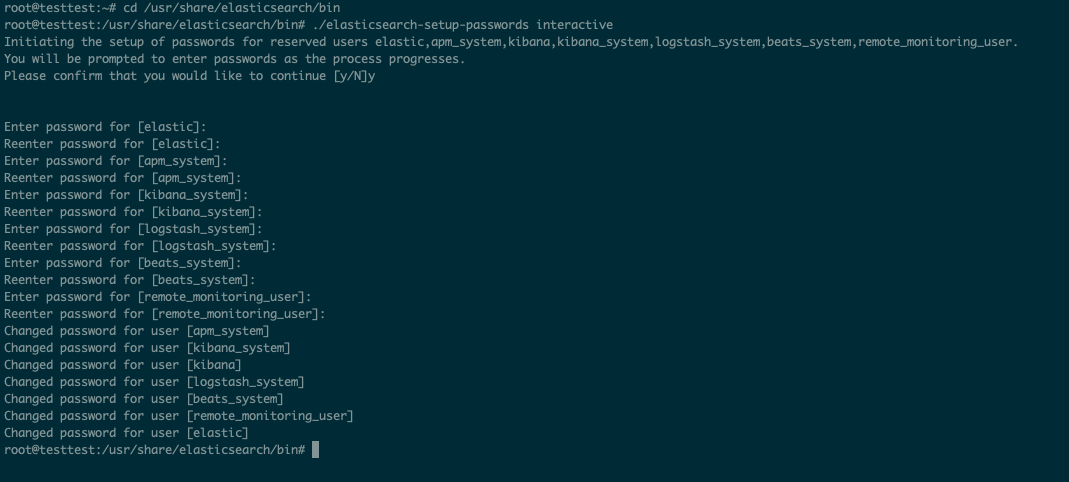
5. 키바나 설정변경
vi /etc/kibana/kibana.yml
# 옵션추가
elasticsearch.username: "elastic"
elasticsearch.password: "비밀번호"6. logstash 설정
# pipe line conf
output {
elasticsearch {
#"http://elasticsearch:9200"
hosts => "http://localhost:9200"
index => "products_index_v1"
document_id => "%{[@metadata][_id]}"
# 아래 옵션 추가
user => "아이디"
password => "비밀번호"
}
}접속시 기본계정은 elastic 이다.
-
elasticsearch 접속시
-
kibana 접속시
마무리
간단하게 ELK stack 환경 세팅을 해보았다.
이렇게 ELK 환경을 구성해서 ELK를 view DB로 이용하여 Query한다면 CQRS의 형태로 발전 시켜나갈 수 있다.
그 때문에 많은 데이터를 검색할 때 유의미한 속도의 차이를 낼 수 있다.
다음 글에서 구체적으로 RDB와 ELK의 검색 속도 차이를 테스트하고 비교해보자
갑자기 docker compose up 명령어 실행 시에
docker endpoint for "default" not found 오류가 뜰 때가 있다
이때 window를 사용한다면 C:\Users\your-username.docker 해당 폴더를 삭제하고 다시 시작하면 된다.
