DB 사양, OS 등의 테스트 환경이나 데이터의 분포도에 따라서 결과가 달라질 수 있습니다.
개요
프로젝트에서 검색 기능을 개발하면서 있었던 DB 성능 이슈를 어떻게 해결했는지를 공유하고자 한다.
MYSQL 만으로 검색 기능 개발하기
오로지 MYSQL DB를 이용해서 검색 기능을 개발해 보기로 했다.
MYSQL DB를 이용해서 검색 기능을 개발할 때 아래의 항목들이 주요 성능 개선 포인트였다.
- 정렬 조건으로는 인기순, 날짜순, 가격순이 존재한다. 특히 인기순은 모든 product row에 대해서 like count가 필요하다.
좋아요는 likes 테이블에서 관리하기 때문에 검색된 모든 row에 대해서 Join - Group by를 한 후 각 product row에 대해 좋아요 개수를 구해야 하므로 성능 이슈가 있었다. - PK 외에 FK 와 단일 인덱스가 몇 개 존재했는데 가장 많이 필터링되는 키워드 관련 인덱스가 사용되는 게 아니라 특정 조건에 따라서 다른 인덱스가 사용되는 문제가 있었다. 이는 일정한 응답속도를 유지하지 않는다.
- 단일 인덱스를 사용했었는데 첫 페이지는 차이가 별로 없으나 인기순/날짜순/가격순을 페이징할 때에는 추가적인 paging cursor 조건을 사용되게 되는데 이때 storage 엔진에서 범위 검색을 하는 것이 아닌 범위 검색 후에 나온 데이터들을 MYSQL 엔진에서 직접 filter 했기 때문에 느렸다.
- 전문 검색은 적은 데이터를 검색하기에는 속도/정확성에서도 like 검색보다는 좋은 성능을 발휘했지만, limit 조건을 Streaming 형식이 아니라 Batch 형식으로 사용하기 때문에 키워드에 해당하는 모든 row를 가져와서 filtering 및 limit 하므로 db의 cache 성능에 따라서 제대로 동작하지 않는 이슈가 있어서 대용량 처리에는 적합하지 않다고 판단했다.
위에서 생긴 성능 이슈를 최적화할 수 있는 핵심 키워드는 다음과 같았다.
- join / group by 비용 줄이기 (비정규화)
- 인덱스 설계하기
- 힌트 사용하기
Like %%를 사용해도 될까?
DB의 인덱스에 대해 무지했었을 때 무심코 %%를 사용한 적이 있었다. 과연 %%는 제대로 된 검색 성능을 발휘할까?
결론부터 말하면 %%는 인덱스를 타지 않기 때문에 full scan을 하게 되고 대용량 데이터를 검색하는 경우 성능 이슈가 발생할 수 있다.
만약 와일드카드를 뒤에만 적용한다면 앞 글자가 같은 것만 검색이 되기 때문에
노트북을 검색하는 경우 노트북 ~ 은 검색이 되지만 ~ 노트북 ~ 과같이 가운데에 있거나 ~ 노트북 과 같은 경우에는 제대로 검색이 되지 않는다.
이럴 경우 검색정확도가 현저하게 떨어질 수 있다.
1. Like로 개발하기
앞서 본 것과 같이 like로 대용량 쿼리를 조회하기 위해서는 인덱스가 필수적이기 때문에 % 키워드 %, 키워드 % 는 사용할 수 없다.
따라서 정확도는 어느 정도 포기하고 조회 쿼리 성능을 끌어올려 보자
여기서 테스트하는 검색 데이터의 조건은 최악의 시나리오를 가정으로 한다. 추가로 간단하게 일반적인 검색에 대한 성능도 살펴보자.
테스트 데이터 개수
- analyze table row 기준
- likes -> 1,500만 건
- products -> 6,700만 건
- users -> 1,800만 건
검색된 row의 수나 필터링의 조건에 따라서 테스트 결과가 상이했기 때문에 부가적인 필터링 조건들은 제거했다.
첫 번째 테스트는 오직 키워드 / 정렬 조건으로 테스트하고
두 번째 테스트는 여러 가지 필터를 추가해서 테스트해 볼 것이다.
튜닝 포인트 찾기
- 실행계획

-> Limit: 10 row(s) (actual time=142469.010..142469.012 rows=10 loops=1) -> Sort: like_counts DESC (actual time=142469.009..142469.011 rows=10 loops=1) -> Filter: ((count(p.product_no) < 20) or ((count(p.product_no) = 20) and (p.product_no > 1000))) (actual time=142283.995..142343.355 rows=262546 loops=1) -> Table scan on <temporary> (actual time=0.001..28.732 rows=262546 loops=1) -> Aggregate using temporary table (actual time=142283.993..142326.969 rows=262546 loops=1) -> Nested loop left join (cost=1256574.19 rows=570825) (actual time=0.594..140801.042 rows=269351 loops=1) -> Index range scan on p using product_name_idx, with index condition: (p.product_name like 'a0%') (cost=655885.75 rows=546646) (actual time=0.431..93734.936 rows=262546 loops=1) -> Index lookup on l using fk_Likes_product_no (product_no=p.product_no) (cost=0.99 rows=1) (actual time=0.178..0.179 rows=0 loops=262546)
- 비교
| 작업 | 시간 |
|---|---|
| Nested loop left join | time 0.594..140801.042 |
| Index range scan | time 0.431..93734.936 |
실행계획에서 actual time 살펴봤을 때 가장 오래 걸리는 작업은 range scan과 nested loop join이다.
따라서 생각해 볼 수 있는 튜닝 포인트는 다음과 같다.
-
nested loop join 시간을 줄여보자 (join 제거하기 -> 비정규화)
- trade off
insert 시에 product table에 함께 update를 해야 하지만 현재 중고 거래 비즈니스상 조회가 대부분일 것으로 예측되기 때문에 두 번의 쿼리가 나가더라도 조회의 성능을 올리는 것이 맞는다고 판단했다.
- trade off
-
Index range scan 시간을 줄여보자 (index 재설계)
-
filesort로 인한 성능 문제 filesort가 있고 없고의 차이에 따라서 쿼리 성능 차이가 발생한다. 이 경우는 아래에서 좀 더 자세하게 살펴보자
위의 순서대로 쿼리를 튜닝해 보자.
1. join / group by 비용 줄이기
- 특정 조건을 걸지 않고 기본적인 키워드 검색 + 페이징 + 정렬 쿼리의 성능을 테스트해보았다.
아래의 쿼리를 베이스로 해서 튜닝할 것이다.
select *
from (select p.*, count(p.product_no) as like_counts
from products p
left join likes l on p.product_no = l.product_no
where p.product_name like 'a0%'
group by p.product_no) t
where (t.like_counts < 20 OR (t.like_counts = 20 AND t.product_no > 1000))
order by t.like_counts desc
limit 10;
해당 쿼리는 인기순으로 정렬하는 쿼리이다.
no-offset 방식을 적용하였고 no-offset 방식을 사용할 때 paging 쿼리에서 사용하는 cursor로 값이 유니크한 값이 있어야 하는데 pk로 no-offset을 사용할 때는 pk 자체가 유니크해서 pk를 그대로 cursor로 사용해도 되지만
현재처럼 인기순/날짜순/금액순인 경우에는 (금액/날짜/좋아요 개수가) cursor가 겹칠 수 있으므로 다음과 같이 추가로 filtering을 해주어야 한다.
비정규화 하기
기존에는 likes 테이블을 join 후에 product_no를 기준으로 group by를 해서 각 product의 개수를 조회했다.
하지만 데이터가 커질수록 join 비용이 커진다.
따라서 이 비용을 줄이기 위해 products table에 like_count 컬럼을 추가해 like가 카운트를 따로 저장하는 식으로 비정규화한다면
likes table insert 시에 products table에도 추가적으로 update를 해야 하지만
조회할 때 join을 하지 않고 products 테이블만으로도 like_count를 구할 수 있다.
비정규화 테스트 최악의 시나리오
- product_name_idx (단일) 인덱스를 사용해서 다른 필터는 추가하지 않고 테스트
- 6,700만/55 ~ 26만 전체 데이터의 0.82 ~ 0.39%
비정규화 전
-
인기순 2m 19s 844ms
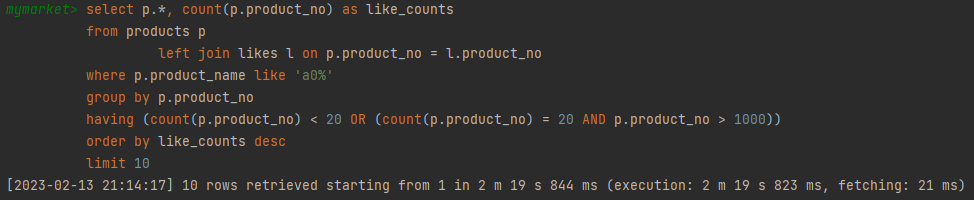
-
최신순 1m 49s 909ms

-
가격 높은순 1m 45s 915ms
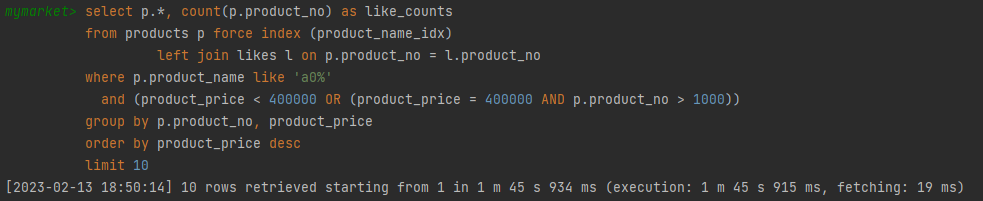
-
가격 낮은순 1m 57s 214ms
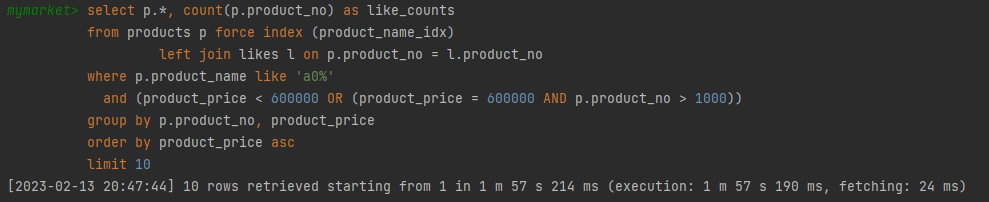
비정규화 후
-
인기순 1m 19s 477ms

-
최신순 1m 20s 80ms

-
가격 높은순 1m 19s 134ms

-
가격 낮은순 1m 19s 270ms

결과 (6,700만/55 ~ 26만)
| 정렬 | 비정규화 전 | 비정규화 후 |
|---|---|---|
| 인기순 | 2m 19s 844ms | 1m 19s 477ms |
| 최신순 | 1m 49s 909ms | 1m 20s 80ms |
| 가격 높은순 | 1m 45s 915ms | 1m 19s 134ms |
| 가격 낮은순 | 1m 57s 214ms | 1m 19s 270ms |
비정규화 테스트 일반 시나리오
- 6,700만/3.2 ~ 1.6만 전체 데이터의 0.05 ~ 0.02%

-> Index range scan on p using product_name_idx, with index condition: (p.product_name like 'a00%') (cost=39266.14 rows=32722) (actual time=0.561..6198.653 rows=16181 loops=1)
-> Index lookup on l using fk_Likes_product_no (product_no=p.product_no) (cost=1.00 rows=1) (actual time=0.204..0.204 rows=0 loops=16181)예측치 rows=32722 실제 rows=16181
비정규화 전
- 8s 960ms
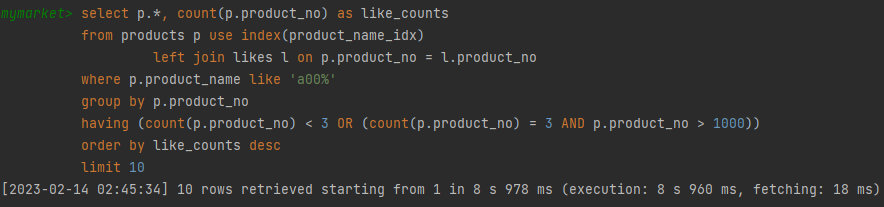
비정규화 후
- 4s 976ms

결과 (6,700만/3.2 ~ 1.6만)
| 비정규화 전 | 비정규화 후 |
|---|---|
| 8s 960ms | 4s 976ms |
2. 복합인덱스 설계하기
인덱스는 하나밖에 사용할 수 없다.
따라서 복합인덱스를 설정해 줘야 하는데 보통은 가장 많이 필터링되는 순서대로 (카디널리티가 높을수록) 복합인덱스를 설계해 주면 좋다.
현재 검색 쿼리에서 필수적으로 들어가는 인덱스인 product_name과 정렬 인덱스 이 2가지를 이용해서 복합인덱스를 설계해 볼 수 있다.
일반적으로 카디널리티가 높은 순서로 product_name / (정렬 인덱스) 순서로 복합키를 구성하는 것이 맞다.
반대로 (정렬 인덱스) / product_name으로 구성했을 때는 어떤 게 다를지 예측하고 테스트를 해보자
filesort 차이 분석
- filesort
select *
from products use index (product_name_and_modify_idx)
where product_name like 'a0%'
and modify_date < '2015-10-30'
order by modify_date desc
limit 10;-> Limit: 10 row(s) (actual time=39227.139..39227.141 rows=10 loops=1)
-> Sort: products.modify_date DESC, limit input to 10 row(s) per chunk (cost=630762.98 rows=525712) (actual time=39227.138..39227.139 rows=10 loops=1)
-> Index range scan on products using product_name_and_modify_idx, with index condition: ((products.product_name like 'a0%') and (products.modify_date < TIMESTAMP'2015-10-30 00:00:00')) (actual time=0.452..39072.626 rows=117072 loops=1)- sort x
select *
from products use index (product_name_and_modify_idx)
where product_name like 'a0%'
and modify_date < '2015-10-30'
limit 10;-> Limit: 10 row(s) (actual time=0.487..4.016 rows=10 loops=1)
-> Index range scan on products using product_name_and_modify_idx, with index condition: ((products.product_name like 'a0%') and (products.modify_date < TIMESTAMP'2015-10-30 00:00:00')) (cost=630699.77 rows=525712) (actual time=0.487..4.014 rows=10 loops=1)
위아래를 비교해 보았을 때 단순히 order by(filesort)가 있냐 없냐의 차이다.
근데 속도 차이는 39227.139 vs 4.016로 매우 크게 난다. 따라서 filesort가 쿼리 성능에 큰 영향을 끼친다는 것을 어림짐작해 볼 수 있었다.
(실행계획을 보면 sort의 cost가 매우 높은 것을 알 수 있다.)
그렇다면 filesort를 없앤다면 성능이 더 좋지 않을까?
최악의 시나리오를 생각해보자
- product_name / modify_date (정렬 인덱스) 인 경우는 filesort를 해야 하므로 검색된 데이터가 많을수록 느릴 것으로 예상할 수 있다.
- 쿼리
select *
from products use index (product_name_and_modify_idx)
where product_name like 'a0%'
and modify_date < '2015-10-30'
order by modify_date desc
limit 10;-
실행계획

-
쿼리 결과

- modify_date (정렬 인덱스) / product_name인 경우는 modify_date가 카디널리티가 낮으므로 필터링 성능은 낮지만 filesort를 사용하지 않기 때문에 위의 실험처럼 많은 데이터가 조회될 때 오히려 product_name / modify_date보다 빠를 것으로 예상된다.
- 쿼리
select *
from products force index (modify_and_product_name_idx)
where modify_date < '2015-10-30'
and product_name like 'a0%'
order by modify_date desc
limit 10;-
실행계획

-
쿼리 결과

-> Limit: 10 row(s) (actual time=0.529..3.964 rows=10 loops=1)
-> Index range scan on products using product_modify_and_product_name_idx, with index condition: ((products.modify_date < TIMESTAMP'2015-10-30 00:00:00') and (products.product_name like 'a0%')) (cost=40019508.78 rows=33357532) (actual time=0.529..3.961 rows=10 loops=1)
먼저 이 인덱스의 경우는 products.modify_date를 기준으로 범위를 좁히게 되는데 최신순으로 검색할 때 products.modify_date로 범위를 줄이는 것보다 Like 키워드로 범위를 줄이는 것이 훨씬 필터링이 많이 된다.
(인기순, 가격순도 마찬가지이다)
또한 일반적으로 우리는 옛날 자료보다 최신 자료를 위주로 찾기 때문에 modify_date를 기준으로 범위를 좁히는 검색은 비즈니스에 맞지 않는 것으로 생각된다.
(실제로 modify_date가 옛날 날짜로 갈수록 성능이 향상됨)
따라서 다음과 같이 특정 지표에서만 뛰어난
modify_date (정렬 인덱스) / product_name 인덱스를 사용하기보다는 평균적으로 성능이 나오는 product_name / modify_date (정렬 인덱스) 것이 더 효율적인 것으로 판단된다.
일반적인 시나리오를 생각해보자
- product_name / 정렬 인덱스
select *
from products force index (product_name_and_modify_idx)
where
product_name like '게이밍%'
and modify_date < '2023-10-30'
and product_exchange_status ='Y'
and product_status ='BEST'
order by modify_date desc
limit 10;-> Limit: 10 row(s) (actual time=3.349..3.349 rows=3 loops=1)
-> Sort: products.modify_date DESC, limit input to 10 row(s) per chunk (cost=21.41 rows=17) (actual time=3.348..3.349 rows=3 loops=1)
-> Filter: ((products.product_status = 'BEST') and (products.product_exchange_status = 'Y')) (actual time=2.031..3.328 rows=3 loops=1)
-> Index range scan on products using product_name_and_modify_idx, with index condition: ((products.product_name like '게이밍%') and (products.modify_date < TIMESTAMP'2023-10-30 00:00:00')) (actual time=0.899..3.319 rows=17 loops=1)- 정렬 인덱스 / product_name
select *
from products force index (modify_and_product_name_idx)
where modify_date < '2023-10-30'
and product_name like '게이밍%'
and product_exchange_status ='Y'
and product_status ='BEST'
order by modify_date desc
limit 10;-> Limit: 10 row(s) (actual time=0.080..36463.196 rows=3 loops=1)
-> Filter: ((products.product_status = 'BEST') and (products.product_exchange_status = 'Y')) (cost=40028821.98 rows=37060) (actual time=0.080..36463.196 rows=3 loops=1)
-> Index range scan on products using product_modify_and_product_name_idx, with index condition: ((products.modify_date < TIMESTAMP'2023-10-30 00:00:00') and (products.product_name like '게이밍%')) (cost=40028821.98 rows=33357532) (actual time=0.043..36463.191 rows=17 loops=1)최악의 시나리오와는 반대로 product_name / 정렬 인덱스가 훨씬 빠르다.
정렬 인덱스 / product_name을 사용할 때에도 겨우 17건에서 14건을 filtering하고 3건을 반환하는 데에 filter cost 가 매우 커서 느린 것을 확인해 볼 수 있다.
product_name / 정렬 인덱스 복합인덱스 설정 후
-
인기순 15s 314ms

-
최신순 36s 77ms

-
가격 높은순 36s 666ms

최종 결과
| 정렬 | 비정규화 전 | 비정규화 후 | 복합인덱스 설정 후 |
|---|---|---|---|
| 인기순 | 2m 19s 844ms | 1m 19s 477ms | 15s 314 ms |
| 최신순 | 1m 49s 909ms | 1m 20s 80ms | 36s 77ms |
| 가격순 | 1m 45s 915ms | 1m 19s 134ms | 36s 666ms |
일정하지 않은 인덱스
검색 조건에 FK나 추가되는 경우가 있었는데 ex) 카테고리 이때 옵티마이저가 기존에 사용하던 인덱스를 사용하지 않고 FK나 다른 인덱스를 사용하는 경우가 있었다.
이 때문에 일정한 성능을 보장하기 힘들었다.
그래서 use index를 사용해 인기순, 가격순, 날짜순에 맞는 최적화된 인덱스를 사용할 수 있도록 개선하였다.
2. 전문 검색으로 개발하기
- MYSQL에서는 전문 검색 인덱스를 지원한다.
n-gram 형태로 문자열을 토큰으로 분리해서 인덱스로 사용하는 방식이다.
현재 product_name에 대해서 n-gram 형태로 full-text-index를 생성해 놓았다.

바로 검색해보자
select *
from products
where MATCH(product_name) AGAINST ('a00' in boolean mode)
order by modify_date desc
limit 10;다음과 같은 오류를 반환하면서 쿼리가 실행되지 않는다.

전문 검색은 내부에서 검색할 때
일반 검색과는 달리 limit 10을 streaming 형식으로 진행되지 않는다.
따라서 MATCH(product_name) AGAINST (a00 in boolean mode)에 해당하는 모든 데이터를 가져온 후 filtering하고 limit 해야한다.
대용량 데이터일수록 큰 메모리가 필요하고 한번 쿼리를 실행할 때마다 많은 데이터를 filtering 하지 못하고 가져와야 하므로 대용량 데이터를 조회할 때는 맞지 않다고 판단했다.
느낀점
RDB를 이용해서 대용량 데이터를 검색하는 기능을 만들기에는 여러 가지 한계점이 있었다.
인덱스를 사용하면 성능을 끌어올릴 수 있으나 인덱스를 추가하면 할수록 cud의 성능이 하락하기 때문에 trade-off를 고려해야 했다.
많은 양의 데이터를 처리하기 위해서 DB의 성능이 좋아야 하고 트래픽이 많은 경우에는 scale-out을 고려해야 하는데
RDB 특성상 확장성이 좋지 않은 단점이 있으므로 이런 검색과 같이 특수한 경우는 nosql을 고려해 볼 수 있을 것 같다.
