0. Main Idea
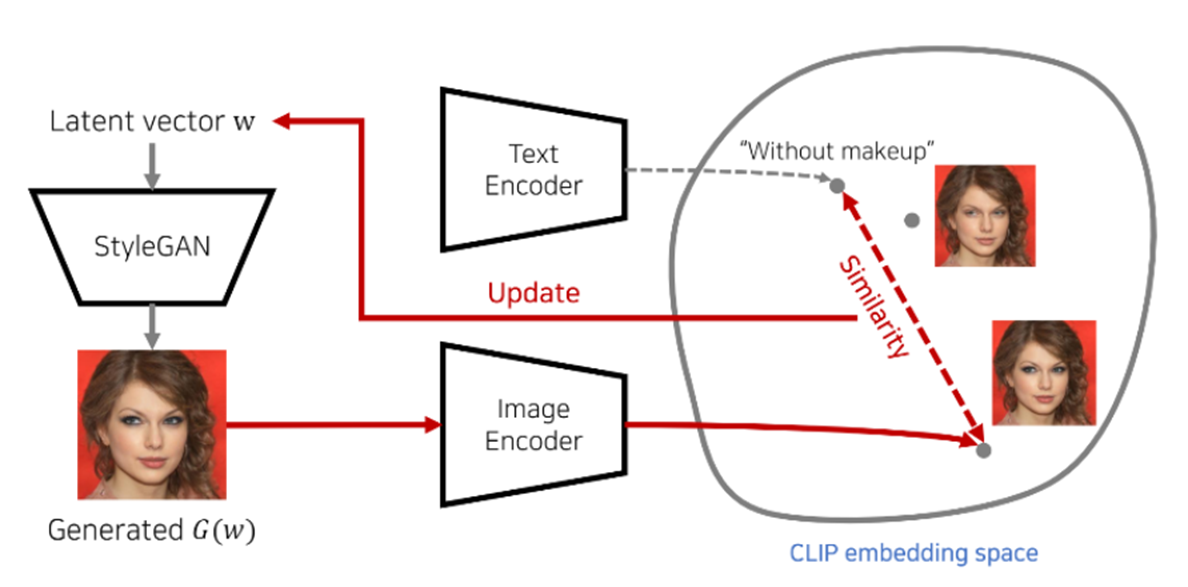
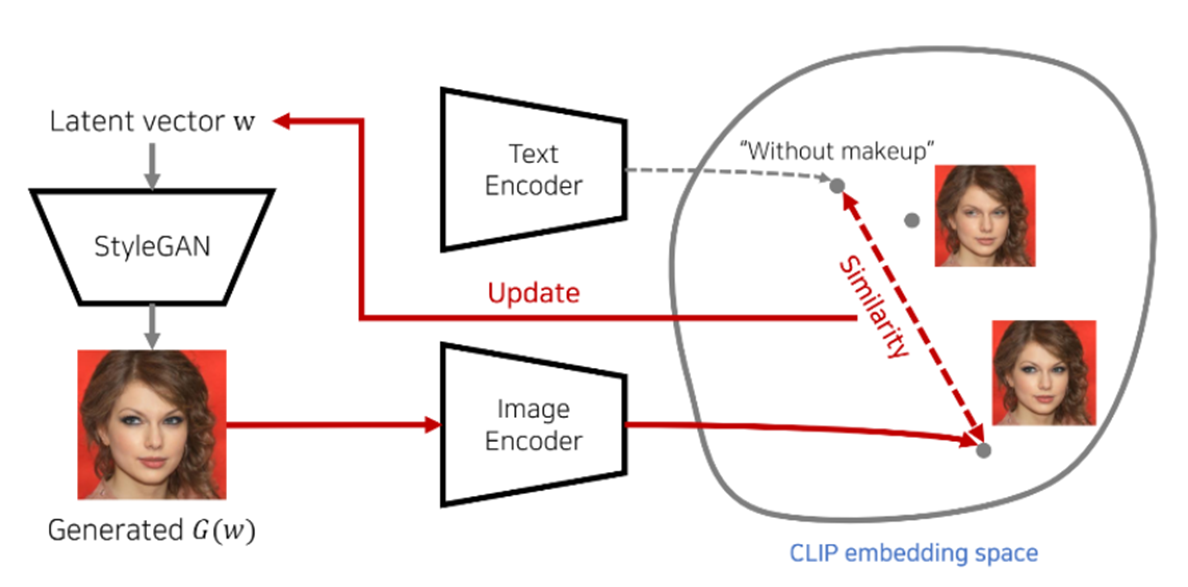
StyleGAN의 Encoding 과정에 Clip Loss를 추가하여 텍스트로 Style을 바꾸는 작업을 가능하게 한다.
Latent Vector w로 부터 만들어진 이미지에 semantic embedding 값이 미리 설정한 특정한 텍스트와 유사해질 수 있는 방향으로 Latent vector를 업데이트 하는 것이다.
1. Methods
1.1 Latent Optimization
- G : StyleGAN의 generator
- D_{CLIP} : G(w)와 text t의 embedding vector의 cosine distance 계산
- L2 distance와 identity loss는 w vector를 w source vector와 유사하게 입력 이미지를 embedding
- L_{ID} : Identity loss를 의미
- R은 사전학습 된 arcface를 사용해서 w source와 w의 cosine similirity를 구하고 이를 optimizaion

어떤 사람의 attribute을 조절할 때는 lambda ID의 값에 일정치 주고, Identity 변경 시 lambda ID값을 낮은 값으로 설정
1.2 Latent Mapper
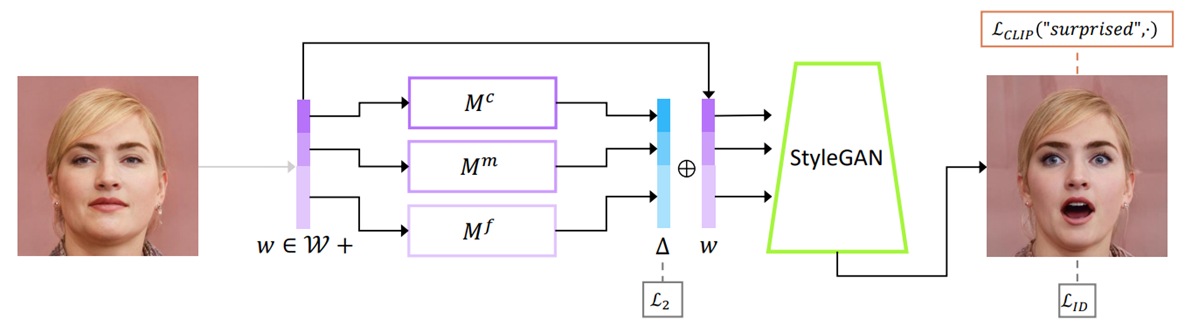
특정 text prompt에 대한 mapping network 학습
Manipulation의 type과 세부적으로 어떻게 변화하고 싶은지에 따라 세가지 매핑 네트워크 coarse, middle, fine style로 구분
LOSS
CLIP loss는 mapper로 하여금 CLIP latent space서 cosine distance를 최소화하도록 함

text prompt를 통해 identity를 유지하면서 한 가지 이상의 속성을 한번에 변경 가능
1.3 Global Directions
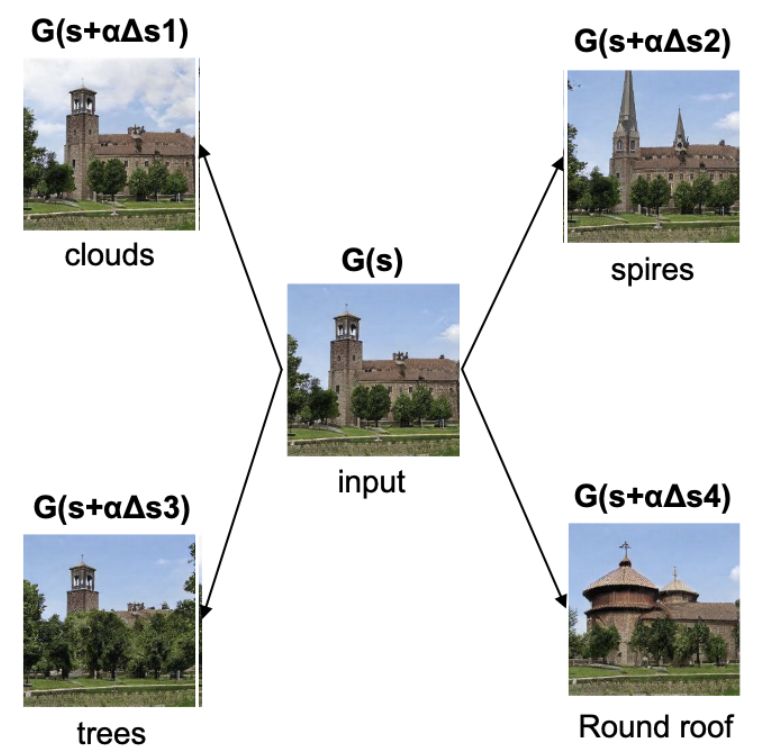
global latent space에 text를 매핑하는 방법으로 어떤 입력이 들어와도 사용가능
원하는 특성을 지시하는 text prompt가 주어지면 원하는 조작 방향 Δs가 다른 특성을 해치지 않으며 원하는 이미지 생성

α는 얼마나 많은 변화를 줄지에 관한 것(manipulation strength)이고 β는 채널 별 threshold로, β가 높으면 특정한 채널 스타일만 변경되고 낮으면 추가적인 특징도 같이 변경
2. Comparisions and Evaluation
2.1. Comparisions and Evaluation

Latent mapper 및 global direction 방법을 TediGAN과 비교
복잡한 속성으로는 trump, 덜 복잡하고 덜 구체적인 속성으로는 모히칸 헤어, 더 단순하고 일반적인 속성은 ‘주름이 없는’것으로 설정하여 실험 진행
실험 결과, latent mapper는 복잡한 속성에 적합하고, global direction은 더 간단하거나 더 일반적인 속성에 적합
2.2. Limitation

StyleGAN의 generator와 사전학습 된 모델에 의존적인 모습을 보임 → 사전학습 된 generator의 도메인에 벗어난 것까지 이미지를 control 할 수 없음
