서포트 벡터 머신이란?
서포트 벡터 머신(Support Vector Machine)은 고차원의 공간에서 최적의 분리 초평면을 찾아 이를 이용해 분류와 회귀를 수행하는 알고리즘이다.
서포트 벡터는 주어진 데이터 중에서 결정 경계와 가장 가까운 거리에 위치한 데이터들을 말한다. 마진은 결정 경계에서 서포트 벡터까지의 거리를 말한다. 결정 경계는 데이터의 분류 기준이 되는 경계를 뜻하며, SVM는 결국 최대 마진을 갖는 초평면인 경정 경계를 찾는 알고리즘이다.
하지만 도저히 선형만으로 구분하기가 어려운 사례들도 많다. 이때에는 2차원의 데이터를 3차원으로 변환하면 결정 경계를 찾을 수 있다. 이런 방법을 커널 트릭(Kernel Trick)이라고 한다. 비선형 분류를 위해 데이터를 높은 차원으로 변환시키는 함수를 커널 함수(Kernel Function)라고 한다. 커널 함수에는 선형(linear), 다항(polynomial), 가우시안(Gaussian), 가우시안 RBF, 시그모이드(Sigmoid) 등 다양한 함수들이 존재한다.
패키지 설치 및 불러오기
나이브 베이즈에서도 사용했던 패키지 e1071을 사용하여 SVM을 수행할 수 있다.
> install.packages('e1071')
> library(e1071)Data Load
> train <- read.csv('ch6-2_train.csv', header=TRUE, stringsAsFactors=TRUE)
> test <- read.csv('ch6-2_test.csv', header=TRUE, stringsAsFactors=TRUE)
> str(train)
'data.frame': 240 obs. of 4 variables:
$ wing_length: int 238 236 256 240 246 233 235 241 232 234 ...
$ tail_length: int 63 67 65 63 65 65 66 66 64 64 ...
$ comb_height: int 34 30 34 35 30 30 30 35 31 30 ...
$ breeds : Factor w/ 3 levels "a","b","c": 1 1 1 1 1 1 1 1 1 1 ...SVM
svm() 함수를 통해 수행핳 수 있다.
> svm_clf <- svm(breeds ~ ., data=train)그래프
plot() 함수를 통해 품종별 데이터가 어떻게 분할 되었는지 확인해보자. slice() 함수의 경우 그래프를 분할할 수 있는 함수이다.
x축을 tail_length, y축을 wing_length로 뒀기 때문에 그 외의 독립변수인 comb_height를 기준으로 두되 그 값은 중앙값으로 설정하고 그려본다.
> plot(svm_clf, train, wing_length ~ tail_length,
+ slice=list(comb_height=median(train$comb_height)))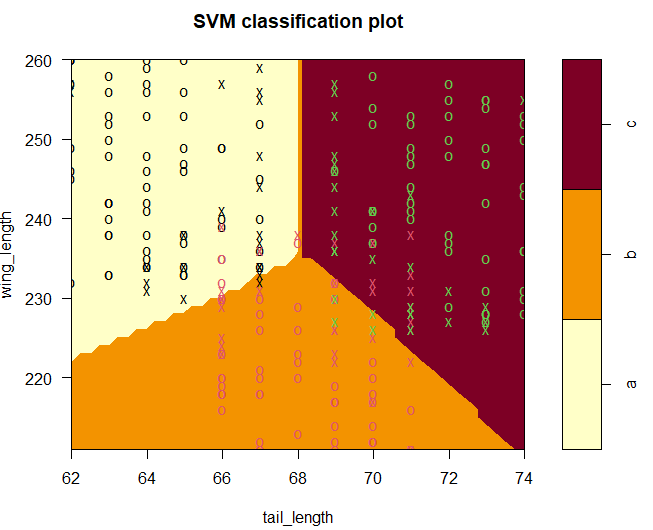
모델 성능 평가
> test$pred <- predict(svm_clf, newdata=test, type="class")
> confusionMatrix(test$pred, test$breeds)
Confusion Matrix and Statistics
Reference
Prediction a b c
a 20 1 0
b 0 17 1
c 0 2 19
Overall Statistics
Accuracy : 0.9333
95% CI : (0.838, 0.9815)
No Information Rate : 0.3333
P-Value [Acc > NIR] : < 2.2e-16
Kappa : 0.9
Mcnemar's Test P-Value : NA
Statistics by Class:
Class: a Class: b Class: c
Sensitivity 1.0000 0.8500 0.9500
Specificity 0.9750 0.9750 0.9500
Pos Pred Value 0.9524 0.9444 0.9048
Neg Pred Value 1.0000 0.9286 0.9744
Prevalence 0.3333 0.3333 0.3333
Detection Rate 0.3333 0.2833 0.3167
Detection Prevalence 0.3500 0.3000 0.3500
Balanced Accuracy 0.9875 0.9125 0.9500