연습문제
iris(붓꽃) 데이터 셋을 이용하여 문제를 풀으세요.
1번
iris 데이터 셋의 구조와 형태를 R 함수를 이용해 확인해보세요. 몇 개의 열과 행으로 이뤄졌으며, 각 열은 어떤 형태를 갖추고 있나요?
- 150개의 row를 가진 5개의 변수가 존재한다.
- Species 컬럼은 범주형 변수, 그 외 변수는 수치형 변수이다.
> df <- iris
> str(df)
'data.frame': 150 obs. of 5 variables:
$ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
$ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
$ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
$ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
$ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...2번
head() 함수를 이용해 iris 데이터 셋의 처음부터 10행까지의 데이터를 불러오세요.
> head(df, 10)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
7 4.6 3.4 1.4 0.3 setosa
8 5.0 3.4 1.5 0.2 setosa
9 4.4 2.9 1.4 0.2 setosa
10 4.9 3.1 1.5 0.1 setosa3번
Sepql.Width 열의 데이터 평균과 표준편차 그리고 3사분위수를 구해보세요.
- 평균 : 3.057
- 표준편차 : 0.436
- 3사분위수 : 3.3
> summary(df$Sepal.Width)
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.000 2.800 3.000 3.057 3.300 4.400
> sd(df$Sepal.Width)
[1] 0.43586634번
Sepql.Width 열의 데이터 분포를 히스토그램으로 나타내 보세요.
> hist(df$Sepal.Width, col='light green',
+ xlab='Sepal.Width',
+ main='Sepal.Width 분포')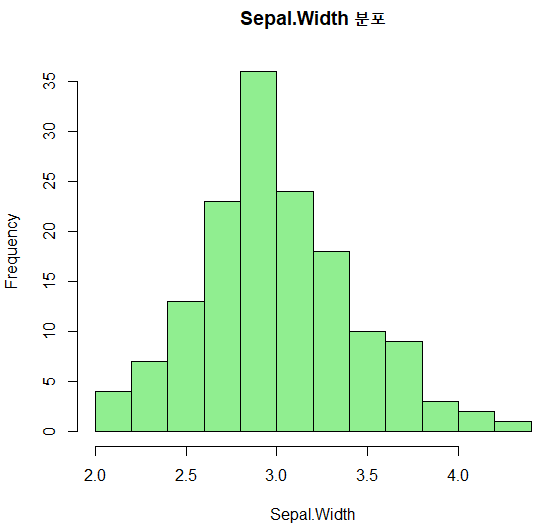
5번
상자그림을 이용해 붓꽃 품종별(Species) Sepal.Width의 분포를 나타내 보세요. Sepal.Width가 가장 넓은 품종은 어떤 종인가요?
- setosa의 분포가 높다.
> boxplot(Sepal.Width ~ Species, data=df,
+ col=c('light green', 'yellow', 'sky blue'),
+ main='붓꽃 품종별 분포')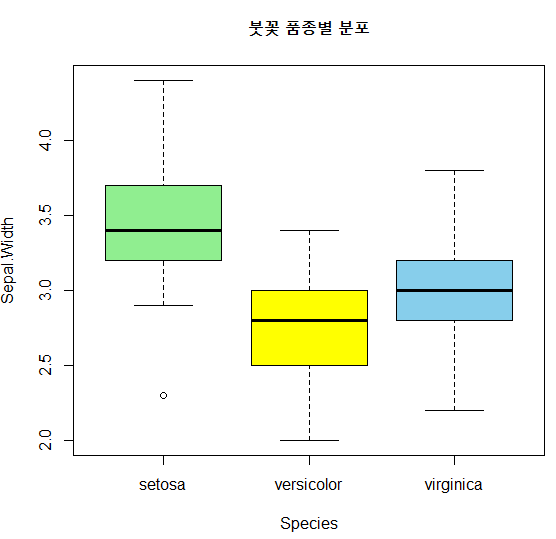
6번
setosa 품종의 Sepal.Width만 필터링해 s라는 데이터 셋을 만들고, versicolor 품종의 Sepal.Width만 필터링해 v라는 데이터 셋을 만들어 보세요.
> s <- subset(df$Sepal.Width, df$Species == 'setosa')
> v <- subset(df$Sepal.Width, df$Species == 'versicolor')7번
데이터 셋 s와 v가 정규분포를 따르는지 검정해 보세요.
- 귀무가설 : 정규분포를 따른다.
- 대립가설 : 정규분포를 따르지 않는다ㅏ.
두 데이터 셋 모두 정규분포를 따른다.
> shapiro.test(s)
Shapiro-Wilk normality test
data: s
W = 0.97172, p-value = 0.2715
> shapiro.test(v)
Shapiro-Wilk normality test
data: v
W = 0.97413, p-value = 0.3388번
데이터 셋 s와 v의 평균이 같다고 할 수 있는지 t-test를 통해 검정해 보세요.
- 귀무가설 : 두 집단 간의 평균에 차이가 없다.
- 대립가설 : 두 집단 간의 평균에 차이가 있다.
두 집단 간의 평균에 차이가 있다.
> t.test(s, v)
Welch Two Sample t-test
data: s and v
t = 9.455, df = 94.698, p-value = 2.484e-15
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
0.5198348 0.7961652
sample estimates:
mean of x mean of y
3.428 2.770 