가설검정
병아리가 부화한 지 5일이 지났다. 그런데 부화장 A에서 태어난 병아리 대비 부화장 B에서 태어난 병아리의 덩치가 더 작아 보인다. 서로 다른 사료를 먹고 있으나, 정말 작은 건지 검정해보자.
Data Load
> df <- read.csv('ch4-3.csv', header=TRUE)
> df상자그림으로 분포 비교
> boxplot(weight ~ hatchery, data=df,
+ horizontal=TRUE, col=c('light green', 'sky blue'),
+ ylab='부화장', xlab='몸무게 분포',
+ main='A vs B 몸무게 분포 비교')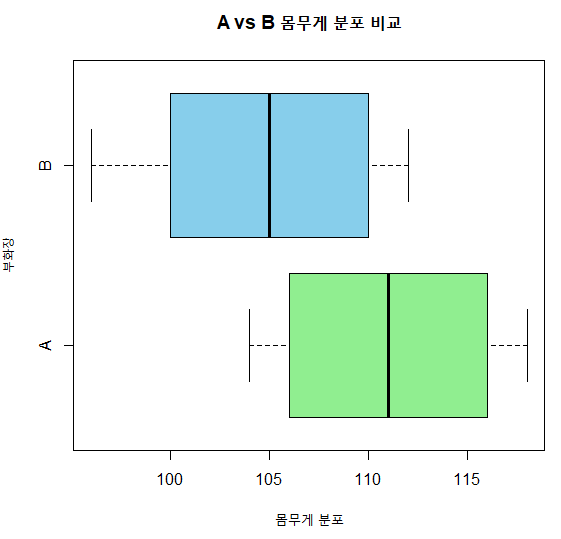
상자그림으로 비교해보니 부화장 A의 병아리 몸무게가 B보다 높게 분포되어 있음을 확인할 수 있다. 통계적으로 두 집단 간의 몸무게가 같은지 다른지를 검정해보자.
정규성 검정
두 집단 간의 몸무게 평균이 같은지 다른지를 검정하기 위해 t-test를 진행한다. t-test는 데이터가 정규분포를 따른다는 가정이 필요하므로, 정규분포를 따르는지 확인하기 위한 Shapiro-Wilk Test를 진행한다.
> a <- subset(df$weight, df$hatchery == 'A')
> b <- subset(df$weight, df$hatchery == 'B')
> shapiro.test(a)
Shapiro-Wilk normality test
data: a
W = 0.94, p-value = 0.553
> shapiro.test(b)
Shapiro-Wilk normality test
data: b
W = 0.93907, p-value = 0.5427귀무가설: 정규분포를 따른다.대립가설: 정규분포를 따르지 않는다.
a의 p-value = 0-553, b의 p-value = 0.5427 이므로 유의수준인 0.05 보다 크기 때문에 귀무가설을 채택한다. 즉, 정규분포를 따른다.
신뢰수준(1-a): 어떤 값이 알맞은 추정값이라고 믿을 수 있는 정도를 뜻한다. 주로 95%를 사용한다.유의수준(a): 가설검정에서 사용되는 기준값을 의미한다.유의확률(p-value): 귀무가설이 맞다고 가정할 때 얻은 결과보다 극단적인 결과가 실제로 관측될 확률을 의미한다.
t-test 두 집단 간 평균 비교
t-test() 함수를 통해 부화장에 따른 몸무게 차이를 검정한다.
귀무가설(H0): 집단 간 병아리 몸무게에 차이가 없다.대립가설(H1): 집단 간 병아리 몸무게에 차이가 있다.
> t.test(data=df, weight ~ hatchery)
Welch Two Sample t-test
data: weight by hatchery
t = 2.8425, df = 17.673, p-value = 0.01094
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
1.71544 11.48456
sample estimates:
mean in group A mean in group B
110.8 104.2p-value = 0.01904 이므로 유의수준인 0.05 보다 작기 때문에 귀무가설을 기각하고 대립가설을 채택한다. 즉, 부화장 A와 B 병아리 몸무게 평균은 서로 다르다.
