디렉토리 설정
# 현재 디렉토리 확인
> getwd()
# 디렉토리 설정
> setwd('디렉토리 경로')Data Load
# Data Load
> df <- read.csv('ch4-2.csv', header=TRUE)
> head(df)데이터 구조
str() 함수를 통해 데이터 구조와 유형을 확인할 수 있다.
2개의 변수가 30개의 관측치를 가지고 있는 data.frame 형태로 되어 있으며, chick_nm 변수는 Factor형, weight 변수는 int형으로 되어 있다.
> str(df)
'data.frame': 30 obs. of 2 variables:
$ chick_nm: chr "b01" "b02" "b03" "b04" ...
$ weight : int 37 39 41 45 37 33 34 31 40 41 ...통계량
- 수치형 변수의 경우 최소값, 제1사분위수, 중앙값, 평균, 제3사분위수, 최대값을 알 수 있다.
- 범주형 변수의 경우 Length, Class, Mode에 대해서 알 수 있다.
> summary(df)
> summary(df$weight)
> summary(df$chick_nm)히스토그램
히스토그램은 hist() 함수를 통해 그릴 수 있다. 데이터의 분포를 확인할 때 사용하는 대표적인 그래프이다.
> hist(df$weight, col='sky blue', xlab='병아리 무게(g)', ylab='B 부화장 병아리 무게 분포 현황')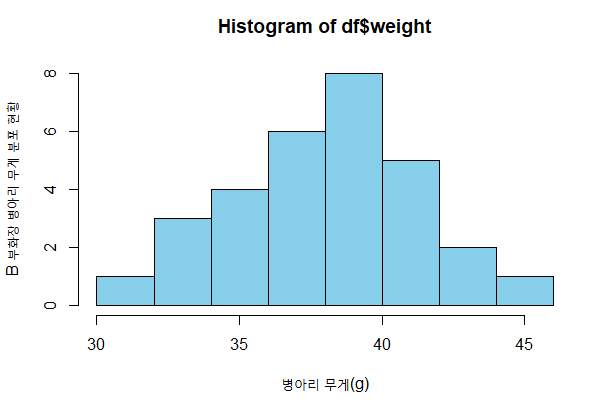
상자그림
boxplot() 함수를 통해 상자그림을 그릴 수 있다. 전체 데이터를 4등분해 데이터의 분포를 파악하는데 사용한다. 서로 다른 2개 이상의 집단 간 데이터 분포를 비교할 때 주로 사용된다.
> boxplot(df$weight, col='sky blue', main='B 부화장 병아리 무게 상자그림')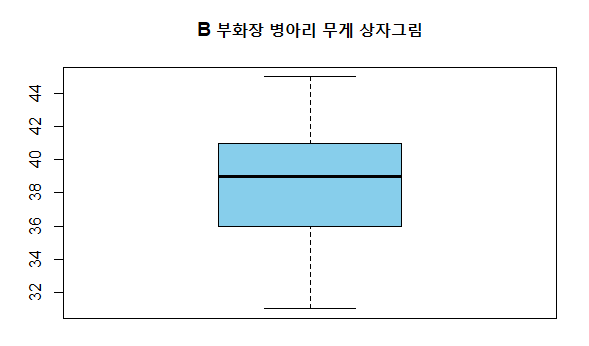
상자그림에 대한 설명은 다음과 같다.

다중 그래프
R에서 한 번에 그래프를 2개 이상 그리기 위해서는 par() 함수를 사용한다. mfrow 옵션은 그래프의 배치를 설정한다. c(행 개수, 열 개수)로 되어있다.
boxplot의 horizontal=TRUE 옵션은 상자그림을 가로 형태로 변경한다는 의미이다.
> par(mfrow=c(2, 1))
> hist(df$weight, col='sky blue', xlab='병아리 무게(g)', ylab='B 부화장 병아리 무게 분포 현황')
> boxplot(df$weight, horizontal=TRUE, col='sky blue')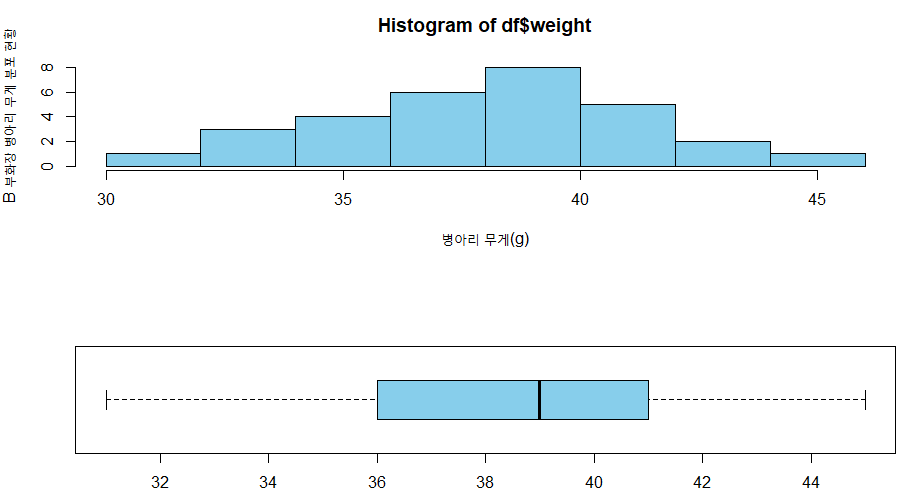
중심극한정리
데이터가 많을 경우(일반적으로 30개 이상) 정규분포와 가까워진다는 것을 정리한 것이 중심극한정리이다.
