1. 서론
Segment Anything은 이미지에서 프롬프트 가능한 세그먼트를 위한 기반 모델을 도입했습니다. 다만 멀티미디어 콘텐츠가 빠르게 증가하면서 상당한 비율이 콘텐츠는 시간적 차원을 갖게 되었습니다. 따라서 이미지 수준의 세그먼트를 넘어서 시간적 위치 지정이 필요합니다. SAM2는 시각적 세그먼트 시스템이 이미지와 비디오 모두에 적용 가능하게 해야합니다.
비디오 세그먼트는 entity의 시공간 범위를 결정하는 것을 목표로 합니다.
다만 SAM의 비디오 세그먼트 모델과 데이터셋은 비디오에서의 모든 세그먼트 기능을 제공하기엔 부족합니다.
이를 위해 SAM2는 PVS(Promptable Visual Segmentation) 작업에 중점을 둡니다. 이는 비디오의 임의의 프레임에서 포인트, 박스, 마스크를 인풋으로 하여 관심있는 segment를 정의하고 이에 대한 시공간 마스크를 예측합니다. 이후 추가 프레임에 대한 프롬프트를 제공하여 반복적으로 수정할 수 있습니다.
SAM2는 객체와 이전 상호작용에 대한 정보를 저장하는 메모리를 갖추고 있어 비디오 전체에서 마스크를 예측 생성하며, 이전 프레임에서 관찰된 객체에 대한 저장된 메모리 컨텍스트를 기반으로 이를 효과적으로 수정할 수 있습니다. 즉 비디오 프레임을 하나씩 처리하며 목표 객체의 이전 메모리에 주의를 기울일 수 있는 메모리 주의 모듈이 장착되어 있습니다.
데이터 엔진을 활용하여 모델과 주석 작업자 간의 상호작용을 통해 새로운 도전적 데이터를 주석하는 방식으로 학습 데이터 생성. 대부분의 기존 비디오 세그먼트 데이터셋과 달리 데이터엔진은 특정 범주의 객체에 제한되지 않고, 경계가 있는 모든 객체를 세그먼트하기 위한 학습 데이터를 제공합니다. SA-V 데이터셋은 50,900개의 비디오에 걸쳐 35.5백만 개의 마스크를 포함하며 이는 기존 비디오 세그먼트 데이터셋보다 53배더 많은 마스크를 제공합니다.
알아가기, SAM에서 상호작용이란?
세그먼트 작업에서 상호작용은 주로 사용자가 모델에 입력을 제공하여 원하는 객체를 정확히 분할하도록 유도하는 행동입니다.
2. 관련연구
SAM은 객체에 해당하는 경계상자, 포인트, 마스크와 같은 입력 프롬프트를 주어 유효한 세그먼트 마스크를 출력하는 프롬프트 가능한 세그먼트 작업을 도입했습니다.
SA-1B 데이터셋으로 학습된 SAM은 유연한 프롬프트 제공으로 제로샷 세그먼트를 가능하게 하여 다양한 후속 응용 분야에 채택될 수 있었습니다. 최근 연구에서는 SAM의 품질을 개선하여 이를 확장하고 있습니다.
iVOS (interactive video object segment)
iVOS는 사용자 안내를 통해 비디오에서 객체 세그먼트 마스크를 효율적으로 얻는 중요한 적업입니다. 최근 접근 방식은 사용자의 입력을 단일 프레임에서 마스크로 변환 후, 이를 다른 프레임에 전파하는 모듈식 디자인을 주로 채택합니다. SAM2 또한 이 작업과 유사하게 비디오 전반에 걸쳐 객체를 세그먼트하면서 우수한 상호작용을 제공하는 것을 목표로 합니다. 이를 위해 강력한 모델과 더 크고 다양한 데이터셋을 구축합니다.
사용자의 안내는 낙서, 클릭, 경계상자 형태로 제공됩니다.
클릭 기반 입력은 상호작용 비디오 세그먼트를 위해 수집에 더 용이합니다. 기존대로 마스크 또는 포인트 기반으로 비디오 추적기를 사용하면 접근 방식에 한계가 있습니다. 추적기가 모든 객체에 대하여 작동하지 않을 수 있으며, SAM이 비디오 이미지 프레임에 대해 성능이 저하될 수 있습니다. 또한 모델의 오류를 상호작용 방식으로 수정할 메커니즘이 없습니다. 따라서 오류가 있는 프레임에서 새로 주석을 진행하고 그 지점에서 추적을 시작해야하는 문제가 있습니다.
VOS(Semi-supervised Video Object Segmentation)
반지도 VOS는 첫 프레임의 객체 마스크를 입력으로 시작하며, 이 마스크를 비디오 전체에 걸쳐 정확히 추적해야 합니다. 입력 마스크가 첫 프레임에서만 객체 외관의 감독 신호로 작용하기 때문에 이를 '반지도'라고 부릅니다.
첫 프레임만을 기반으로 하거나 이전 프레임까지 통합하여 더 빠른 추론을 달성했습니다. 이러한 다중 조건화 방식은 RNN과 cross-attention과 같은 방식으로 모든 프레임에 확장되었습니다. 최근 접근 방식은 ViT를 사용하여 현재 프레임과 모든 이전 프레임, 예측 결과를 함께 처리해 단순한 아키텍쳐를 제공하지만 추론 비용이 매우 큽니다.
Video Segment Dataset
많은 데이터셋이 VOS 작업을 위해 제안되었습니다. 사용되었던 데이터셋들은 딥러닝 학습에 부족했습니다. YouTube-VOS는 4천 개 이상의 비디오와 94개의 객체 범주를 포함하는 VOS 작업을 위한 최초의 대규모 데이터 셋입니다.
알고리즘의 성능이 향상되고 벤치마크 성능이 포화 상태에 도달하면서 연구자들은 VOS 작업의 난이도를 높이기 위해 가려짐, 긴 비디오, 극단적 변형, 객체 다양성, 장면 다양성 등에 집중하기 시작했습니다.
비디오 세그먼트 데이터셋과 다르게 SA-V 데이터셋은 전체 객체 뿐만 아니라 객체의 부분까지 광범위하게 포괄하며, 마스크 개수 면에서도 기존 데이터셋보다 훨씬 더 많은 양을 제공합니다.
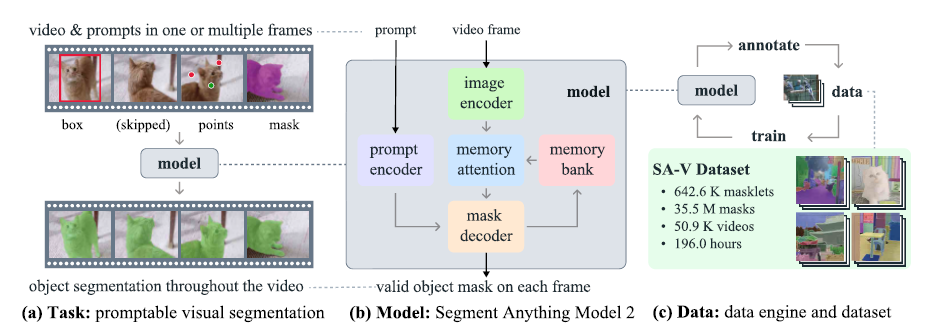
<그림 2> SAM2를 이용한 interactive segmentation
Step 1(선택) :
- 우리는 프레임 1에서 SAM 2에게 프롬프트를 제공하며 목표 객체의 세그먼트를 얻습니다. (초록색 점은 긍정적 프롬프트를, 빨간색 점은 부정적 프롬프트를 나타냅니다.)
- SAM2는 자동으로 다음 프레임으로 세그먼트를 전달하여 마스크를 형성합니다.(파란 화살표)
- 만약 SAM2가 객체를 놓친 경우, 새로운 프레임에서 추가 프롬프트를 제공하여 마스크릿을 수정할 수 있습니다. (빨간 화살표)
Step 2(정제) :
- frame 3에서 단 하나의 클릭만으로 객체를 회복하고 이를 전파하여 올바른 마스크를 얻을 수 있습니다.
- SAM + 비디오 트래커 접근 방식은 Frame 3에서 여러 클릭이 필요하여 Segmentation이 처음부터 다시 시작되어 객체의 재주석에 시간이 소요됩니다. 그러나 SAM 2는 단 하나의 클릭만으로 복구가 가능합니다.
3. 작업 : PVS(Promtable Visual Segmentation)
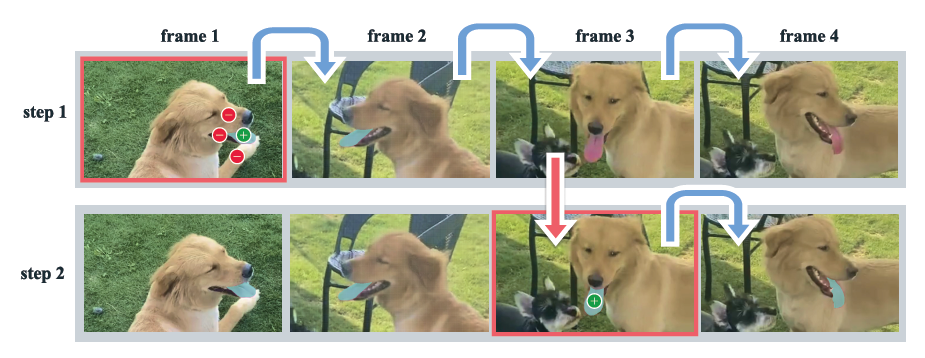
<그림 8> PVS 예시, 이전에 연구된 SA와 VOS는 PVS 작업의 특수한 사례 혹은 하위 개념으로 생각할 수 있습니다.
PVS는 사용자로부터 간단한 입력(프롬프트)을 받아 이미지나 비디오에서 객체를 분할하는 접근 방식입니다. PVS 작업에서는 비디오의 어떤 프레임에도 관계없이 프롬프트를 제공할 수 있습니다.
이때 프롬프트는 긍정적/부정적 클릭, 바운딩 박스, 마스크로 구성될 수 있습니다.
interactive한 경험을 위해, 특정 프레임에서 프롬프트를 수신한 뒤 모델은 즉시 해당 프레임에서 객체의 유요한 세그먼트 마스크로 응답합니다.
최소한의 상호작용으로 객체의 분할을 쉽게 수정할 수 있도록 interactive한 경험을 향상시키는 데 중점을 둡니다.
SAM과 마찬가지로 명확히 경계가 정의된 객체에 대해 중점을 두며, 시각적 경계가 없는 영역은 고려하지 않습니다.
초기 프롬프트를 수신한 뒤 모델은 프롬프트를 전파하여 비디오 전체에서 객체의 마스크를 얻습니다. 따라서 각 비디오 프레임에서 대상이 되는 객체의 세그멘테이션 마스크를 생성하게 됩니다.
추가 프롬프트는 비디오 전반에 걸쳐 세그먼트를 정제하기 위해 어떤 프레임에서도 모델에 제공될 수 있습니다.
PVS의 장점 정리
유연성:
- 다양한 형태의 프롬프트를 지원하므로 사용자가 원하는 방식으로 상호작용 가능.
- 정적인 이미지뿐만 아니라 비디오에서도 적용 가능.
효율성:
- 간단한 입력으로 높은 정확도의 세그멘테이션 결과를 생성.
- 최소한의 사용자 입력으로 더 빠르게 작업 완료.
일반화 가능성:
- SAM2는 프롬프트의 유형에 관계없이 높은 수준의 일반화 성능을 제공.
시공간 일관성:
- 비디오 세그멘테이션에서 시간적 연속성을 유지하며 객체를 정확히 추적.
4. 모델
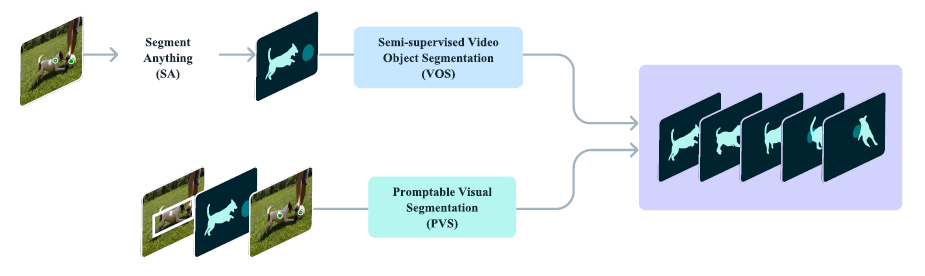
<그림3> SAM2 아키텍쳐
이미지 인코더
-
비디오를 실시간으로 처리하기 위해 스트리밍 방식을 채택합니다.
-
이미지 인코더는 전체 상호작용 동안 한 번만 실행합니다.
-
각 프레임을 나타내는 비조건 토큰을 제공하는 역할을 합니다. 여기서 비조건 토큰은 객체, 위치, 사용자 제공 프롬프트 등의 외부 조건에 영향을 받지 않고 생성되는 독립적인 표현의 백터화된 토큰입니다.
-
다중 스케일 특성을 디코딩하는 데 사용할 수 있는 계층 구조를 가진 MAE 사전 학습된 Hiera 이미지 인코더를 사용합니다.
메모리 어텐션
역할
-
현재 프레임의 특성을 과거 프레임의 특성과 예측, 그리고 새로운 프롬프트에 따라 조건화
-
L개의 트랜스포머 블록을 쌓으며, 첫 번째 블록은 현재 프레임의 이미지 인코딩을 입력으로 받습니다. 각 블록은 self-attention을 수행한 다음,
메모리 뱅크에 저장된 프레임과 객체 포인터에 대한 cross-attention을 수행 -
마지막으로 다층 퍼셉트론(MLP)
memory attention 수식

memory attention 수식 2

프롬프트 인코더 및 마스크
-
프롬프트 인코더는 SAM과 동일하며, 클릭(긍정적 또는 부정적), 바운딩 박스 또는 마스크를 통해 프레임에서 객체의 범위를 정할 수 있도록 프롬프트를 받을 수 있습니다.
-
희소 프롬프트는 위치 인코딩과 각 프롬프트 유형에 대한 학습된 임베딩의 합으로 표현되며, 마스크는 합성곱을 사용하여 임베딩되고 프레임 임베딩과 더해집니다.
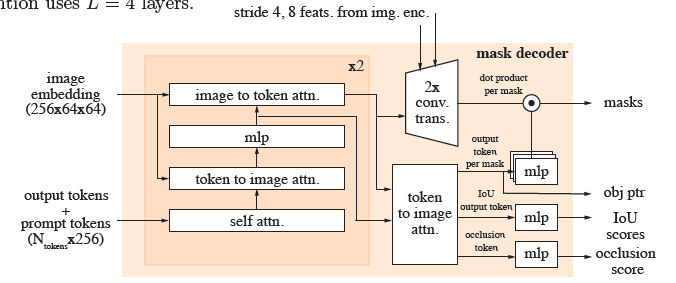
<그림9> 마스크 디코터 아키텍쳐
마스크 디코더 설계는 SAM을 따릅니다.
프롬프트와 프레임 임베딩을 업데이트하는 '양방향' 트랜스포머 블록을 쌓습니다.
-
SAM과 마찬가지로, 여러 호환 가능한 타겟 마스크가 있을 수 있는 애매한 프롬프트에서는 여러 마스크를 예측합니다. 후속 프롬프트가 애매함을 해결하지 않으면 모델은 현재 프레임에 대해 예측된 IOU가 가장 높은 마스크만 전파합니다. 이를 위하여 IOU socres를 반환하는 MLP 헤드를 추가합니다.
-
SAM에서는 긍정적 프롬프트가 주어졌을 때 항상 분할할 유효한 객체가 존재하지만, PVS 작업에서는 어떤 프레임에서는 유효한 객체가 존재하지 않을 수 있습니다. (예를 들어 가림현상으로 인하여) 따라서 현재 프레임에서 관심 객체가 존재하는지 예측하는 추가 MLP 헤드를 추가합니다. 이는 occlusion score를 반환합니다.
-
또 다른 차이점으로 마스크 디코딩을 위한 고해상도 정보를 통합하기 위해 계층적 이미지 인코더에서 추출한 stride 4, 8 feature map을 잔차 연결해줍니다. 이는 그림 상단에 표기되어있으며 MSA 블록을 우회합니다.
메모리 인코더
메모리 인코더는 출력 마스크를 다운샘플링하여 메모리를 생성하고, 이를 이미지 인코더에서의 비조건부 프레임 임베딩과 요소별로 합산합니다. 그 후, 정보 융합을 위해 경량 합성곱 층을 추가합니다.
메모리 뱅크
메모리 뱅크는 비디오 내 목표 객체에 대한 과거 예측 정보를 유지하기 위해 최대 N개의 최근 프레임 메모리를 갖춘 FIFO 큐를 유지하며, 최대 M개의 프롬프트 프레임 정보를 FIFO 큐에 저장합니다.
초기 마스크가 유일한 프롬프트인 VOS에서는 메모리 뱅크가 첫 번째 프레임의 메모리와 최대 N개의 최근 프레임의 메모리를 지속적으로 유지합니다. 두 세트의 메모리는 공간 특성 맵으로 저장됩니다.
또한 공간 메모리 외에, 각 프레임의 마스크 디코더 출력 토큰을 기반으로 세그먼트할 객체의 고수준 의미 정보를 위한 경량 벡터 형태의 객체 포인터 목록을 저장합니다. 우리의 메모리 주의는 이러한 공간 메모리 특성과 객체 포인터 모두에 크로스 어텐션을 적용합니다.
SAM2는 N개의 최근 프레임의 메모리에 시간적 위치 정보를 임베딩하여 모델이 단기 객체 이동을 표현할 수 있도록 합니다. 그러나 프롬프트된 프레임에는 이를 임베딩하지 않습니다. 이는 프롬프트된 프레임에서 훈련의 신호가 더 희소하고, 훈련 중 본 적 없는 매우 다른 시간 범위의 프롬프트된 프레임에 대해 일반화하는 것이 더 어렵습니다.
