3. BERT
- BERT의 프레임워크에는 사전학습과 미세 조정이라는 두 단계가 있습니다.
- 사전학습에서는 다양한 사전학습 작업을 통해 레이블이 지정되지 않은 데이터에 대해 모델을 학습합니다.
- 미세조정을 위해 사전학습된 파라미터로 BERT 모델을 초기화하고, 다운스트림 작업의 레이블이 지정된 데이터를 사용하여 모든 파라미터를 미세 조정합니다.
- BERT의 특징은 다양한 작업에 걸쳐 통합된 아키텍쳐 입니다.
- 미니 사전 학습된 아키텍쳐와 최종 다운스트림 아키텍쳐 간의 차이점을 파악할 수 있습니다.
Model architecture
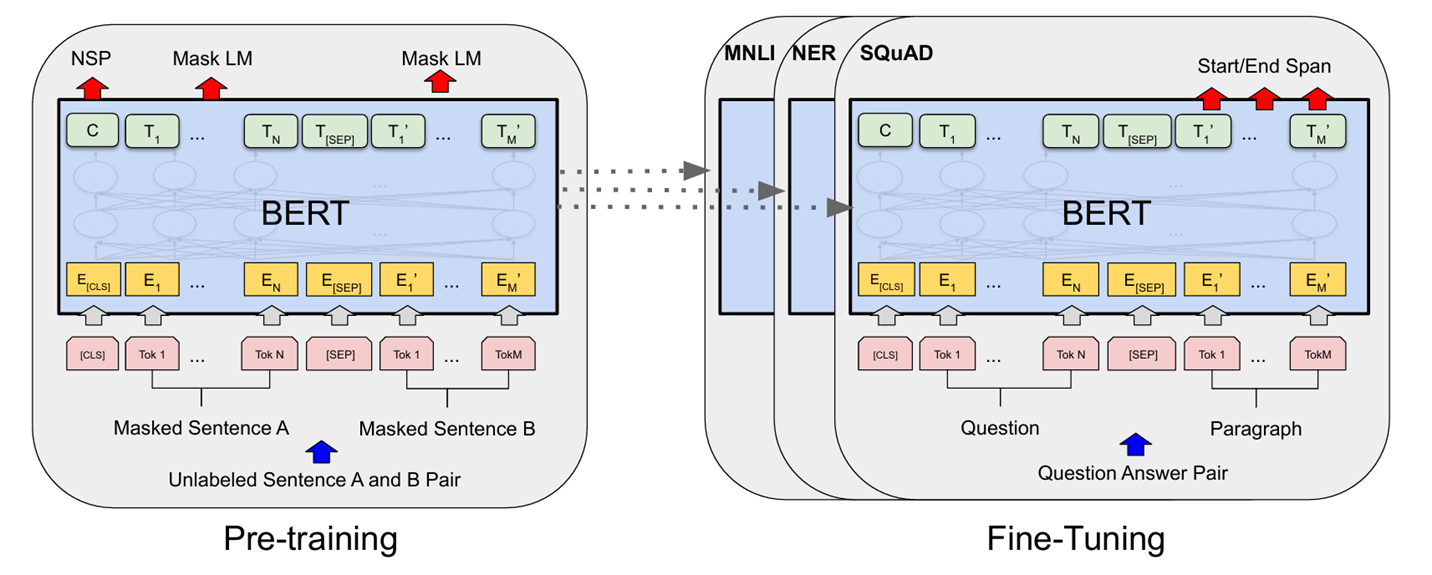
BERT의 기본 아키텍쳐
-
BERT는 Transformer 모델 구조를 기반으로 만들어졌습니다.
-
Transforemr는 주로 자연어 처리(NLP) 문제를 해결하는데 사용되며, 양 방향으로 텍스트를 이해하는 특징을 가집니다.
BERT 모델 크기
-
BERT_BASE :
레이어 수 : 12
Hidden size : 768
총 파라미터 : 약 1억 1천만 개 -
BERT_LARGE :
레이어 수 : 24
Hidden size : 1024
총 파라미터 : 3억 4천만 개
GPT와의 차이
-
BERT는 텍스트를 양방향으로 이해합니다. 즉, 앞 뒤 문맥을 모두 고려합니다.
-
반면 GPT는 주로 텍스트의 앞쪽 문맥만 사용하여 단어를 예측합니다.
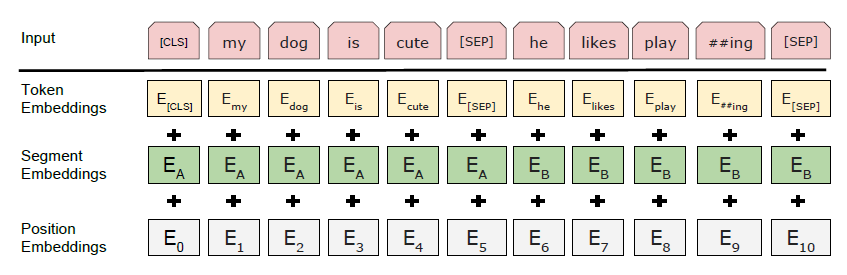
<그림 2> BERT 입력 표현, 입력 임베딩은 토큰 임베딩, 세그먼트 임베딩, 포지션 임베딩의 합입니다.
입력 출력표현
-
BERT는 다양한 입력을 처리할 수 있도록 입력 표현 방식을 설계, 여기서 입력안 하나의 문장 또는 두 개의 문장이 포함된 토큰 시퀀스로 구성됩니다.
-
WordPiece 임베딩을 사용하여 30,000개의 어휘를 포함합니다.
-
입력 시퀀스는 특수 토큰 [CLS]로 시작합니다.
-
이 토큰은 분류 작업에 사용되는 최종 숨겨진 상태 벡터로 변환됩니다.
-
입력 시퀀스가 두 문장으로 이뤄진 경우, 각 문장은 SEP 토큰으로 구분됩니다.
입력 표현 방식 구성
- 토큰 임베딩 : 각 단어 또는 서브워드에 대하여 WordPiece 임베딩 생성
- 세그먼트 임베딩 : 입력 문장이 두 개일 경우, 각 문장에 대해 다른 세그먼트 ID를 부여.
- 포지션 임베딩 : 시퀀스 내에서 각 토큰의 위치 정보를 추가.
3.1 BERT Pre-training
MLM(Masked LM)
-
양방향 조건부는 각 단어가 직접적으로 "스스로를 볼 수 있도록" 허용하고 모델이 다층적인 맥락에서 단어를 예측하게 할 수 있습니다.
-
양방향 표현을 훈련하기 위해서 입력 토큰의 일정 비율을 무작위로 마스킹합니다. 이후 마스킹된 토큰을 예측합니다.
-
이 절차를 MLM이라고 부릅니다.
-
이 때 마스크 토큰에 해당하는 최종 hidden vector는 표준 LM과 마찬가지로 어휘 위에 출력 softmax에 공급됩니다.
-
모든 실험에서 각 Sequence의 모든 단어 조각 토큰의 15%를 무작위로 마스킹합니다.
-
하지만 이 방식은 양방향 사전학습 모델을 얻을 수 있지만, 미세 조정 중에 MASK 토큰이 적용되지 않기 때문에 사전학습과 미세 조정 사이의 불일치가 발생됩니다.
이를 완화하기 위해서 아래와 같은 방식을 채택합니다.
-
i번째 토큰이 선택되면, i번째 토큰을 (1) 80%는 MASK 토큰
-
(2) 10%는 무작위 토큰으로
-
(3) 10%는 변경되지 않은 i번째 토큰으로 대체합니다.
-
이후 Ti를 사용하여 교차 엔트로피 손실이 있는 원래 토큰을 예측합니다.
NSP(Next Sentense Prediction)
NSP 개념
-
BERT 모델에서 두 문장 간의 관계를 이해하기 위한 사전 학습 과정 중 하나입니다.
-
두 문장이 주어졌을 때, 다음 문장이 실제로 이전 문장(A) 다음에 이어지는 문장(B)인지 또는 무작위로 선택된 문장인지 판단합니다.
NSP 학습 과정
- IsNext
문장 B가 문장 A 다음에 이어지는 문장일 때.
- NotNext
문장 B가 문장 A와 관련 없는 무작위로 선택된 문장일 때.
학습 데이터 중 50%는 IsNext 관계, 나머지 50%는 NotNext 관계로 구성됩니다.
NSP는 QA(질문답변)와 NLI(자연어 추론) 모두에 유익합니다.
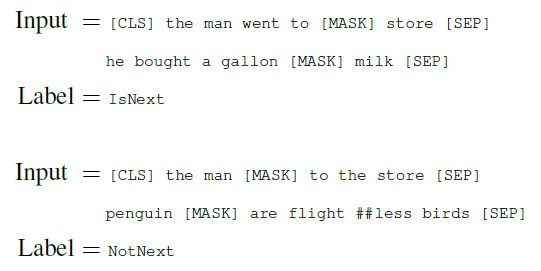
사전 훈련 데이터
-
사전 훈련 코퍼스에는 북스코퍼스와 영어 위키백과를 사용합니다.
-
긴 연속 시퀀스를 추출하기 위해 문장 수준 코퍼스가 아닌 문서 수준 코퍼스를 사용합니다.
3.2 BERT 미세 조정
-
트랜스포머 Self Attention 매커니즘을 사용하면 단일 텍스트 혹은 텍스트 쌍의 입력과 출력에 대하여 효율적으로 작업할 수 있어 BERT 모델의 미세 조정이 간단해집니다.
-
텍스트 쌍을 처리할 때는 독립적으로 인코딩 하는 것 보다, Self Attention으로 두 단계를 통합하여 인코딩하는 것이 효과적입니다.
-
이렇게 할 시에 문맥 사이의 양방향 교차주의가 효과적으로 이뤄집니다.
각 작업에 대하여 입력과 출력을 BERT에 간단하게 연결하고 모든 매개변수를 엔드투엔드로 Fine-Tuning합니다. 입력 측면에서 문장 A와 문장 B는 다음과 유사합니다.
-문장 쌍을 사용하는 패러프레이징(paraphrasing) 작업,
-가설-전제(hypothesis-premise) 쌍을 사용하는 함의(entailment) 작업,
-질문-문단(question-passage) 쌍을 사용하는 질문 응답 작업,
-텍스트 분류 또는 시퀀스 태깅 작업에서의 단일 텍스트 형태의 쌍.
출력 측면에서는, 토큰 표현이 시퀀스 태깅 또는 질문 응답과 같은 토큰 수준 작업을 위해 출력 레이어로 전달되고, [CLS] 표현은 함의 또는 감정 분석과 같은 분류 작업을 위해 출력 레이어로 전달됩니다.
4. GLUE(General Language Understanding Evaluation)
GLUE는 자연어 이해(NLU, Natural Language Understanding) 평가를 위한 다양한 과제의 모음집입니다. BERT나 다른 언어 모델의 성능을 평가하기 위해 널리 사용됩니다.
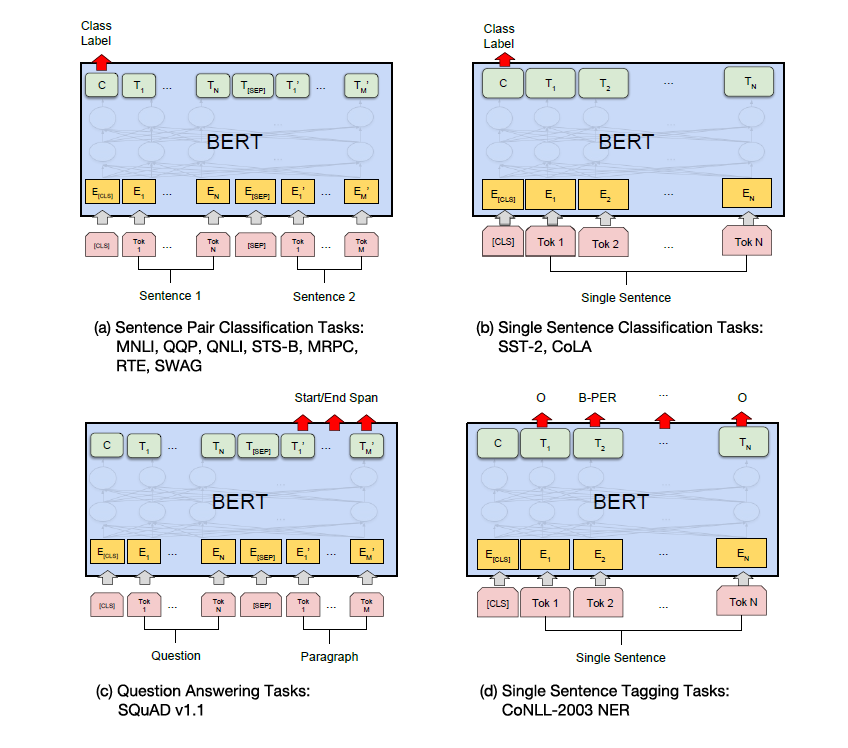
GLUE 미세조정
-
입력 형식 : GLUE를 활용하여 미세 조정에서는 BERT 입력으로 단일문장 혹은 문장 쌍을 제공합니다.
-
출력형식 : 최종적으로 [CLS] 토큰의 백터 표현이 출력 레이어로 전달되어 분류 작업에 사용됩니다.


그림 a,c는 쌍으로 이뤄진 문장을 input하며 sep 토큰으로 문장을 구분합니다.
그림 b,d는 한 문장을 input하며 sentence 사이의 토큰 관계를 계산합니다.
GLUE 예시
<그림 a에 대한 설명>
문장 쌍을 사용하는 패러프레이징(paraphrasing) 작업
패러프레이징 작업은 두 문장이 같은 의미를 갖는지(즉, 서로 말만 다를 뿐 의미는 동일한지)를 판단하는 작업입니다.
입력 데이터:
두 개의 문장 쌍 (문장 A와 문장 B).
예:
문장 A: "Can you help me with this task?"
문장 B: "Could you assist me with this work?"
목표:
두 문장이 동의어 관계인지(True) 또는 의미가 다르거나 무관한지(False)를 판단.
<그림b에 대한 설명>
가설-전제(hypothesis-premise) 쌍을 사용하는 함의(entailment) 작업
함의(entailment)는 두 문장 사이의 논리적 관계를 분석합니다.
하나의 문장(가설, Hypothesis)이 다른 문장(전제, Premise)으로부터 논리적으로 도출 가능한지 확인하는 작업입니다.
입력 데이터:
가설과 전제로 구성된 문장 쌍.
예:
전제(Premise): "A person is standing under a tree."
가설(Hypothesis):
"Someone is taking shelter under a tree."
목표:
가설이 전제를 기반으로 논리적으로 참인지(True), 거짓인지(False), 또는 불확실한지(Neutral)를 판단.
<그림c>
질문-문단(question-passage) 쌍을 사용하는 질문 응답(question answering) 작업
질문 응답은 문단(Passage)에서 질문에 대한 답변을 추출하거나 생성하는 작업입니다.
입력 데이터:
질문(Question)과 관련 문단(Passage).
예:
질문: "What is the capital of France?"
문단: "Paris is the capital city of France, known for its culture and history."
목표:
문단에서 질문의 답변을 찾기.
답변: "Paris"
<그림c>
텍스트 분류 또는 시퀀스 태깅 작업에서의 단일 텍스트-? 형태의 쌍
이 작업은 단일 텍스트 입력을 기반으로 특정 분류나 태깅 작업을 수행합니다.
텍스트 분류:
문서나 문장을 입력으로 받아 감정(긍정/부정) 분석, 주제 분류 등을 수행.
예:
입력: "The movie was absolutely wonderful!"
출력: 긍정(Positive)
시퀀스 태깅:
입력 문장에서 단어 단위로 태그를 지정하는 작업. 주로 개체명 인식(NER)이나 품사 태깅 등에 사용됩니다.
예:
입력: "Barack Obama was born in Hawaii."
출력: Barack Obama [PER], Hawaii [LOC]
