1. Introduction
NLP에서 Transformer의 영감을 받아, 최소한의 수정만으로 표준 Transformer를 이미지에 적용하는 실험을 진행하였습니다. 이를 위해 이미지를 패치로 분할하고 이러한 패치의 선형 임베딩 시퀀스를 트랜스포머에 입력으로 제공합니다. 이미지 패치는 NLP에서 토큰과 같은 방식으로 취급됩니다. 지도학습 방식으로 이미지 분류에 대한 모델을 훈련시킵니다.
강력한 정규화 없이 이미지넷과 같은 중간 크기의 데이터 셋에 대해 훈련할 경우, 모델은 비슷한 크기의 ResNet보다 몇 포인트 낮은 수준의 정확도를 제공합니다.
이는 데이터 양의 부족으로 인한 것입니다.
하지만 대규모 데이터 셋(1400만 ~ 3억장)으로 모델을 학습 시킬 경우 ViT는 데이터 포인트 수가 적은 작업에 적용하면 우수한 결과를 얻을 수 있습니다.
특히 최고 모델은 ImageNet에서 88.55%, ImageNet-Real에서 90.72%, Cifar-100에서 94.55%, 19개의 작업으로 구성된 VTAB 제품군에서 77.63%의 정확도를 달성했습니다.
2. 관련 작업
3. 방법
3.1 비전 트랜스포머(ViT)
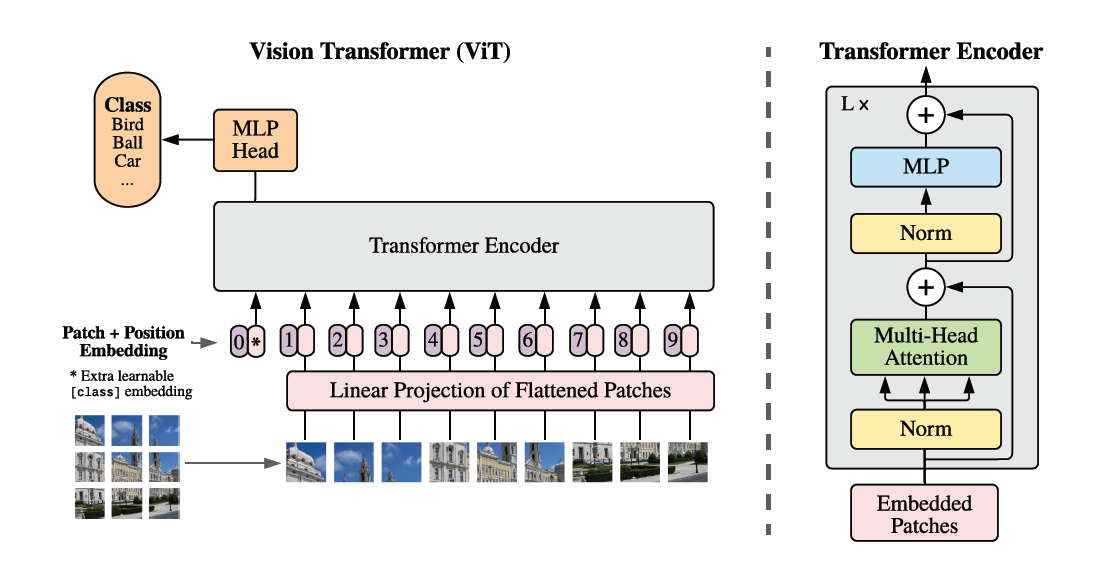
< 그림1> 모델 개요, 이미지를 고정된 크기의 패치로 분할하고, 각 패치를 선형적으로 임베딩합니다. 이에 위치 임베딩을 추가한 다음, 결과 벡터 시퀀스를 표준 Transformer 인코더에 공급합니다. 분류를 수행하기 위해 학습한 분류 토큰을 시퀀스에 추가하는 표준 접근 방식을 사용합니다.>
- 표준 트랜스포머는 토큰 임베딩의 1D Sequence를 입력으로 받습니다. 2D 이미지를 처리하기 위해 이미지를 다음과 같이 재형성합니다.
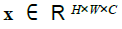
x는 실수에 높이 x 너비 x 채널을 지수화하는 공식을 따릅니다.
- 평면화 된 2D패치 시퀀스는 다음과 같이 형성됩니다.
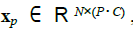
C = 채널 수 입니다.
P = 각 이미지 패치의 해상도입니다.
N = 결과 패치 수입니다.
Transformer는 모든 레이어에서 일정한 크기의 백터 D를 사용하므로 패치를 평평하게하고 훈련 가능한 선형 투영을 사용하여 D차원으로 매핑합니다. 이 투영의 출력을 패치 임베딩이라고 합니다.
전반적인 ViT의 진행 수식은 하기와 같습니다.
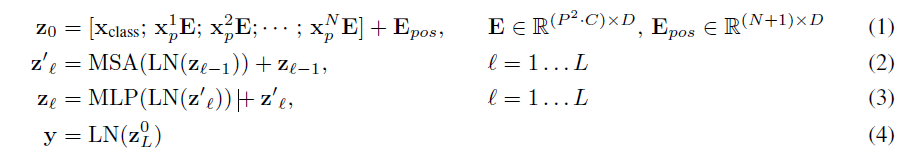
-
z0단계입니다.
Xclass;는 Classfication token입니다.
X'p는 patch N번에 대한 변환입니다.
E는 D차원으로 축소 혹은 확장하는 Embeding을 뜻합니다.
Epose는 Postional Embeding을 의미합니다.
따라서 x를 N개의 패치만큼 각각 Linear Embeding한 뒤 Postional Embeding 값을 더해줍니다. -
두 번째 단계는 MSA 즉 Multi Head Attention을 사용합니다.
z0으로 변환된 값에 layer normalization을 적용합니다.
이후 Multi Head Attention을 진행한 뒤 z0 값을 잔차연결하여 줍니다. -
세번째 단계로 MLP를 사용합니다.
MSA을 거쳐 도출된 값을 Layer Normalization을 진행한 뒤 Multi Layer Perceptron을 거쳐줍니다. 도출된 값에 잔차연결을 진행합니다. -
MSA를 진행하여 출력되는 값은 (N+1)xD의 토큰입니다. 토큰에는 class token 1개와 N개의 Patch token 들로 구성되어 있습니다.
-
이때 class token은 MSA를 통해 패치들 간의 관계를 반영하여 이미지의 전반적인 구조적 및 문맥적 정보를 담고 있는 벡터입니다.
-
ViT 최종 단계에서는 Class Token만 사용하며 MLP Head에 input하여 최종 분류를 진행합니다.
3.2 미세 조정 및 더 높은 해상도
대규모 데이터 세트에 대해 ViT를 사전 학습하고 다운스트림 작업에 맞게 미세 조정합니다.
이를 위해 ImageNet으로 사전학습된 예측 헤드를 제거합니다.
예측 헤드는 약 1000개의 값을 예측하는 헤드입니다.
다만 사용자가 예측하고자 하는 클래스의 개수에 맞게 다운스트림하기 위하여 예측헤드를 제거하고 새로운 FFN을 적용합니다.
여기서 FFN은 DxK 선형 레이어를 거치는 MLP Head입니다.
- D는 Transformer의 출력 CLS 토큰의 차원(임베딩 크기, 보통 768 or 1024 등)입니다.
- K는 다운스트림 될 클래스의 수입니다.
따라서 사전학습된 ViT 모델에 다운스트림되어 출력되는 클래스의 개수는 K개가 됩니다.
ViT를 Fine-tuning 할 때, Pre-training과 동일한 패치의 크기를 사용하기 때문에 고해상도의 이미지로 fine-tuning 하면 Sequence의 길이가 길어질 수 있습니다.
따라서 pre-trained positional embedding을 원본 이미지의 위치에 따라 2D interpoliation(보간법)하여 사용합니다.
4. 실험
실험 영역은 ViT와 다른 모델들간의 성능 비교가 주를 이루기 때문에 ViT의 내용에 집중하기 위하여 여러 목차를 생략하도록 하겠습니다.
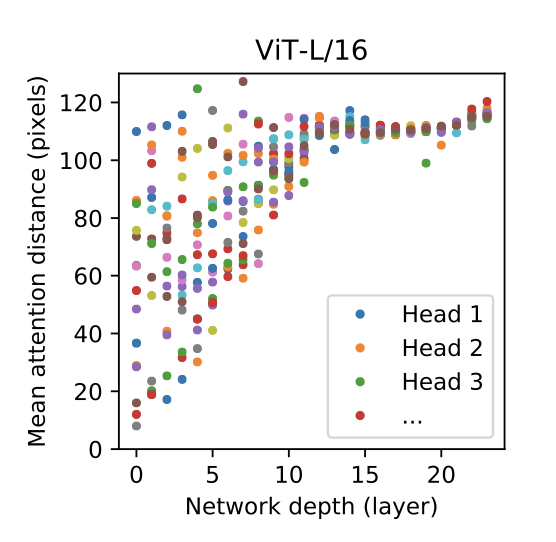
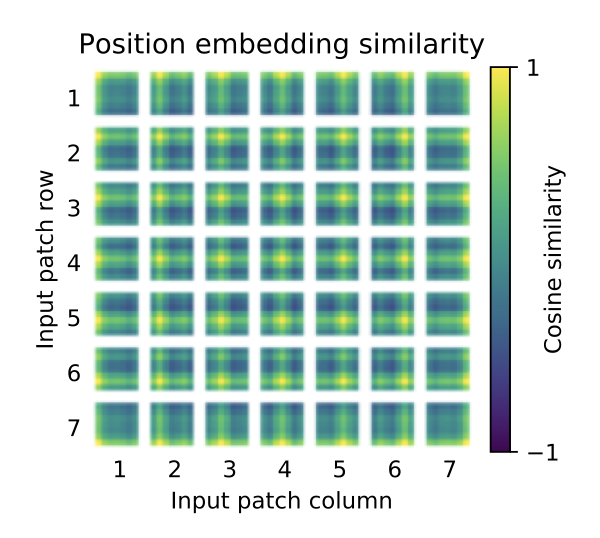
4.5 비전 트랜스포머 검사

<그림 6 > 출력 토큰에서 입력 공간으로의 대표적인 예시.
비전 트랜스포머 이미지 데이터를 처리하는 방식은 위의 이미지 예시와 같습니다. 비전 트랜스포머는 분류 시 의미적 관련성이 있는 이미지 영역에 attend하게 됩니다.
비전 트랜스포머는 이미지 데이터를 처리하는 방식을 이해하기 위해 내부 표현을 분석합니다. 비전 트랜스포머

ㅇ
ㅇㅇㅇ