2. 내용
2.1 경계상자 예측
Yolov3 또한 Yolov2와 같이 k-clustering을 사용하여 앵커 박스를 예측합니다. 네트워크는 각 경계 상자에 대해 4개의 좌표 (tx, ty, tw, th)를 예측합니다. 셀이 이미지의 왼쪽 상단 모서리로부터 (cx, cy)만큼 오프셋 되고, 앵커 박스의 너비와 높이가 pw, ph일 때 예측은 다음과 같이 적용됩니다.
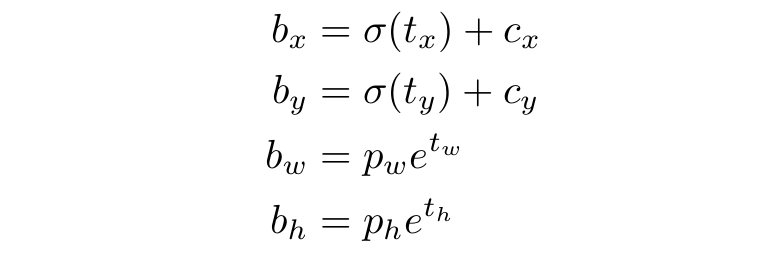
하기 그림은 해당 수식을 적용하여 바운딩 박스가 생성되는 예시입니다.
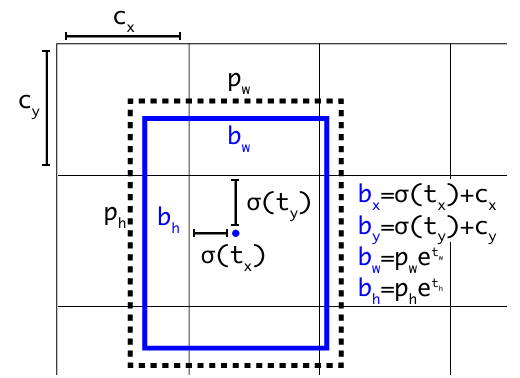
Yolov3는 Sum Squared Error loss를 사용합니다. 만약 좌표 예측에 대한 실제 값이 y 일 때, y - y'가 기울기가 됩니다.
Yolov3는 로지스틱 회귀를 사용하여 각 bounding box에 대한 신뢰도 점수를 예측합니다. 신뢰도 점수를 바탕으로 NMS를 진행하며 iou threshold는 0.5입니다.
Yolov3의 시스템은 각 실제 객체에 하나의 앵커박스만 할당합니다. 앵커박스가 실제 객체에 할당되지 않을 경우, 좌표나 클래스 예측에 대한 손실은 없으며, 객체성에 대한 신뢰도 점수에서만 손실이 발생합니다.
2.2 클래스 예측
Yolov3부터 각 상자는 멀티레이블 분류를 사용합니다.
멀티레이블 분류는 soft max를 사용하지 않습니다.
그 이유는 다음과 같습니다.
바운딩 박스 안에 겹치는 레이블이 존재할 때에 soft max를 사용하면 각 상자에 정확히 하나의 class만 존재한다고 가정합니다. 하지만 박스 안의 레이블들은 독립적인 객체들 입니다. 따라서 이타적인 activation함수 softmax 대신, 독립적으로 분류하는 함수인 sigmoid를 사용해야합니다.
알아가기, FPN이란?
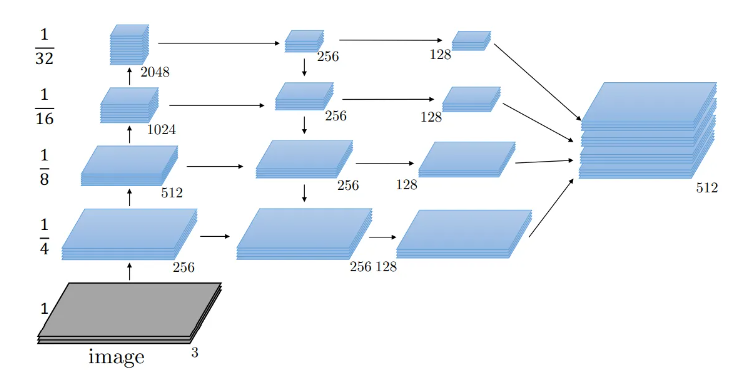
FPN이란 무엇인가?
FPN은 Feature Piramid Network의 약자로 다양한 스케일의 featuremap을 통해 효율적으로 객체를 탐지하기 위해 설계된 모델 구조입니다.
대표적으로 Mask-RCNN, Retina-Net, Yolov3 등에서 사용됩니다.
FPN 작동 방식
-
Bottom Down : 기본적인 CNN 네트워크에서 입력 이미지를 통해 점진적으로 다운샘플링하여 저해상도에서 고수준의 특성을 추출합니다.
-
Top-down 경로: 고해상도 특성 맵으로 역전파하면서 상위 단계의 특성 맵을 저해상도 특성 맵에 통합합니다.
-
Skip 연결 : 각 단계의 featuremap을 합성합니다. 풍부한 정보를 가진 feature map을 생성합니다.
2.3 여러 스케일에서의 예측
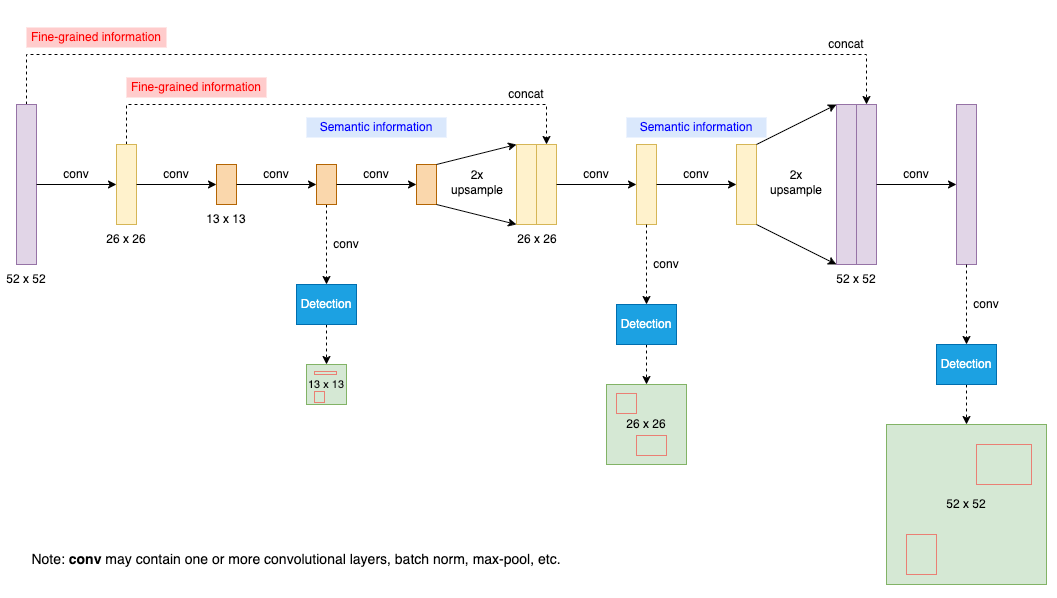
<추가 그림 yolov3 아키텍쳐>
YOLOv3에서는 3개의 다른 스케일에서 상자를 예측합니다.
위에서 언급한 FPN 네트워크를 모델의 Neck으로 사용하여 다중 스케일에서 feature map을 추출합니다.
-
기본 특징 추출기에서 몇 개의 합성곱 계층을 추가합니다.
-
각 스케일의 마지막 계층은 3D Tensor를 예측합니다. 여기에는 경계 상자, 객체성, 클래스 예측이 인코딩 됩니다.
-
COCO 데이터셋에서 각 스케일마다 3개의 상자를 예측하므로 텐서 크기는 N x N [ 3 x (4 + 1 + 80)] 이 됩니다. 4는 bounding box의 오프셋으로 x, y, w, h 값이 되고 1은 객체성 예측, 80은 클래스 예측이 됩니다.
-
그런 다음 두 계층 전의 특징 맵을 가져와 2배로 업샘플링, 네트워크 초반부의 특징맵을 가져와 업샘플된 특징과 연결합니다.
이 방법은 업샘플된 특징에서 더 의미 있는 의미론적 정보를 얻고, 초반부의 특징 맵에서 더 세밀한 정보를 얻을 수 있게 합니다.
- 그런 다음 이 결합된 feature map을 처리하기 위해 몇 개의 합성곱 layer를 추가합니다.
이후 유사한 Tensor를 예측하고 이때 크기는 두배가 됩니다.
- 한번 더 동일한 디자인을 수행하여 마지막 스케일에 대하여 상자를 예측합니다.
따라서 3번째 scale에 대한 예측은 모든 이전 계산의 이점을 누리고, 네트워크 초반부 세밀한 특징도 포함합니다.
Yolov3는 여전히 k-mean clustering을 사용하여 anchor box를 결정합니다. 이 때 9개의 anchor box와 3개의 scale을 사용하여 클러스터를 scale에 균등하게 나눴습니다.
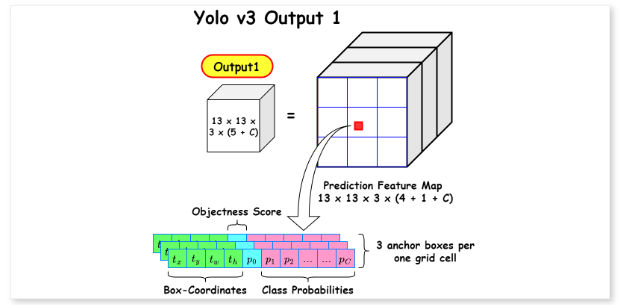
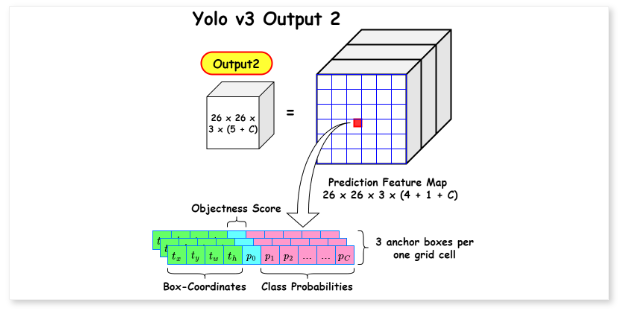
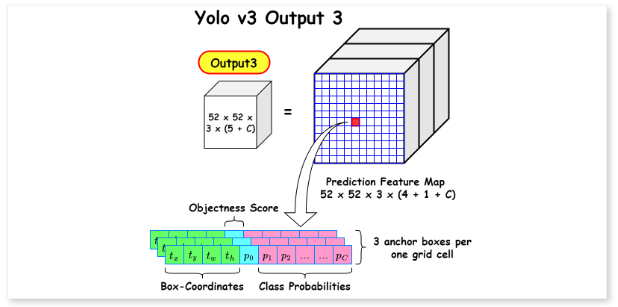
<3가지 스케일의 Output 예시>
2.4 특징 추출기
Yolov3는 새로운 네트워크를 사용하여 특징을 추출합니다.
Yolov2의 Darknet-19, 그리고 Residual network 방식을 결합한 Hybrid 접근 방식을 사용합니다. Yolov3 Network는 3x3 conv layer와 1x1 conv layer를 사용합니다. 또한 short connection을 사용합니다.
알아가기, Residual은 무엇인가?
layer의 구조가 깊어짐에 따라 기울기가 소실되는 gradient vanishing 문제가 발생될 수 있다. 깊은 network에서 훈련 과정 중에 loss가 줄어들지 않는 현상과 같다.
Residual Block의 개념
-
output = F(x) + x 입니다.
-
x는 입력 값입니다.
-
F(x)는 x 입력에 대한 변환된 값입니다.
-
F(x) + x는 변환 값에 x를 더한 값입니다.
-
Residual 값을 다음 Layer로 전달합니다.
input x > conv layer > Batch Normalization > Relu > Residual > Relu > Next layer
위 개념을 도입한 새로운 Network를 Darknet-53이라고 합니다.
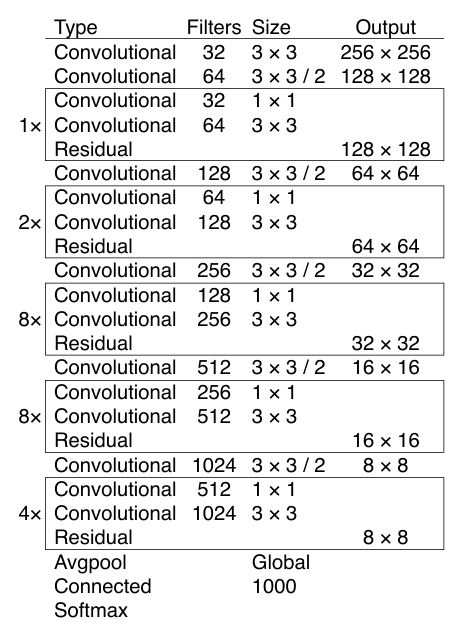
< Table 1. Darknet-53>
각 네트워크는 동일한 설정에서 훈련되고 256 x 256 해상도의 단일 크롭 정확도로 테스트 되었습니다. Darknet-53은 최첨단 분류기와 비슷한 성능을 보이지만, 부동 소수점 연산이 적고 속도는 더 빠릅니다. 또한 ResNet-152와 비슷한 성능을 보이지만, 2배 더 빠릅니다.
Darknet-53은 측정된 부동 소수점 연산 속도가 가장 높습니다. 이는 네트워크 구조가 GPU를 더 잘 활용하여 평가하는 데 효율적이고 더 빠른 것을 의미합니다.
2.5 훈련
Yolov3는 전체 이미지를 사용하여 훈련합니다. 멀티 스케일 훈련, 데이터 증강, batch normalization 등 다양한 기법을 사용해줍니다. Darknet nueral network 프레임워크를 사용하여 훈련과 테스트를 진행합니다.
3. 성능
Yolov3의 성능은 mAP 기준으로 보면, YOLOv3는 SSD 변형들과 비슷한 성능을 보여주지만 3배 더 빠른 속도를 보입니다.
IOU = 0.5일 때 mAP로 보면, YOLOv3은 강력한 성능을 보입니다. RetinaNet과 거의 동등한 성능을 보이며, SSD 변형들보다 훨씬 우수합니다. 이는 Yolov3가 객체에 대한 적절한 경계 상자를 생성하는데 매우 뛰어난 것을 위미합니다. 그러나 IOU threshold가 증가함에 따라 성능이 크게 떨어집니다. 이는 Yolov3가 상자와 객체를 정확히 일치시키는 것에 어려움을 겪는 것을 의미합니다.
과거 Yolo는 작은 객체 탐지에 어려움을 겪었습니다. 그러나 멀티 스케일 예측으로 인하여 작은 객체에 대한 성능이 비교적 높습니다. 하지만 중간 크기와 큰 객체에 대한 성능은 상대적으로 더 낮은 것을 확인할 수 있습니다.
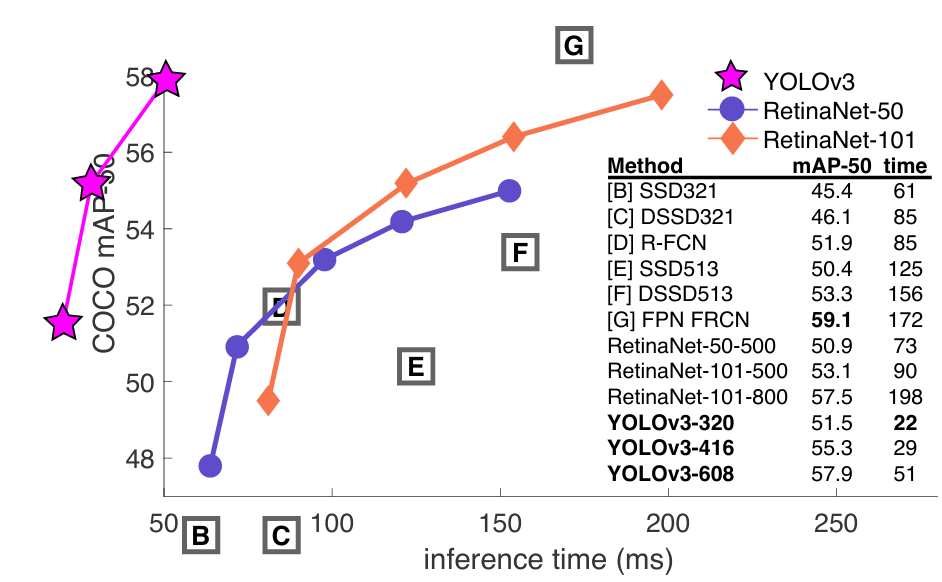
<그림3>
위의 표는 mAP 0.5 IOU 지표에서의 속도/정확도 절충을 나타냅니다.
표에서 확인할 수 있는 것처럼 YOLOv3는 아주 빠른 속도임에도 불구하고 성능이 좋은 것을 확인할 수 있습니다.
Referenece
