https://arxiv.org/abs/1503.03832
Abstract
얼굴 이미지에서 거리가 얼굴 유사성 측정에 직접 해당하는 콤팩트한 유클리드 공간으로의 매핑을 직접 학습하는 FaceNet을 제시한다. 이 공간에서는 FaceNet 임베딩을 기능 벡터로 사용하여 얼굴 인식, 검증 및 클러스터링과 같은 작업을 쉽게 구현할 수 있다.
여기서는 임베딩 자체를 직접 최적화하도록 훈련된 심층 컨볼루션 네트워크를 사용한다. 이는 표현 효율성이 좋아 한 얼굴 당 128바이트만 사용하여 최첨단 얼굴 인식 성능을 달성한다.
1 Introduction
얼굴 검증, 인식, 클러스터링 (이 사람이 동일한가, 누구인가, 이 얼굴들에서 같은 사람 찾기)에 대한 통합된 시스템을 제공한다. 이 방법은 deep convolutional network를 통해 이미지 당 유클리드 임베딩 학습을 기반으로 한다.
이 신경망은 임베딩 공간의 L2 제곱이 얼굴 유사성에 직접 대응되도록 훈련되었다. (동일한 얼굴이면 거리가 작고, 얼굴이 다르면 거리가 크다)
임베딩이 생성되면, 얼굴 검증은 두 임베딩 사이의 거리를 임계값으로 설정하여 해결하며, 인식은 KNN 분류 문제로 해결할 수 있고 클러스터링은 K-means나 응집 클러스터링을 통해 해결할 수 있다.
과거의 얼굴 인식 방식은 주로 딥 네트워크를 사용하여 알려진 얼굴 식별 정보를 기반으로 훈련된 분류 레이어를 사용하여 얼굴을 인식했다. 그러나 이 방식은 비효율적이다. FaceNet은 이와 달리 triplet loss의 손실 함수를 사용하여 128차원의 압축된 얼굴 임베딩을 직접 출력한다. 이는 보다 효율적이고 직접적인 방식으로 얼굴을 인식할 수 있다.
2 Related Work
아래의 딥 네트워크를 사용하여 얼굴의 픽셀에서 직접적으로 표현을 학습하고, 레이블이 지정된 얼굴의 데이터 세트를 통해 포즈,조명 등 다양한 조건에 대한 불변성을 얻는다.
Deep Convolution Network
- Zeiler&Fergus Model
- Inception model
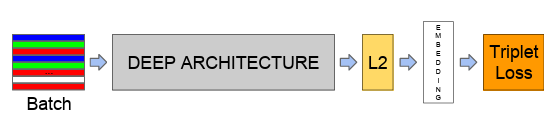
얼굴 임베딩 모델은 batch input layer와 Deep CNN layer 로 구성되며 L2 정규화를 거친다.
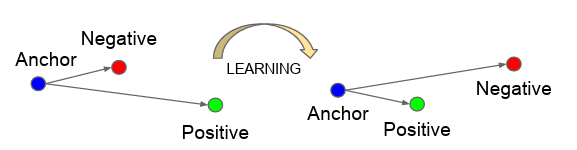
이후 triplet loss를 통해 anchor와 positive의 거리는 최소화하고 anchor와 negative의 거리는 최대화한다.
3 Method
FaceNet은 deep convolutional network를 사용하고 주요 아키텍처는 Zeiler&Fergus 네트워크와 Inception 네트워크이다. 여기서 가장 중요한 부분은 end to end 학습이고, 이를 위해 triplet loss를 사용한다.triplet loss를 통해 각 얼굴 쌍 사 이의 margin을 적용하여 다른 얼굴들 사이의 차별성을 강조한다.
3.1 Triplet loss
이미지 x를 d차원 유클리드 공간에 삽입하여 같은 사람의 이미지들(anchor와 positive)이 다른 사람의 이미지(anchor와 negative)보다 더 가깝도록 하려고 한다.
3.2 Triplet Selection
수렴 속도가 느리지 않고 모델을 증명하는 데 기여할 수 있는 삼중항을 선택하는 접근 방식에 대해 설명한다.
빠른 수렴을 위해 xa가 주어지면 아래 식을 만족하는 xp및xn을 선택해야 한다.
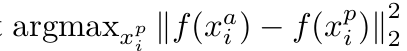
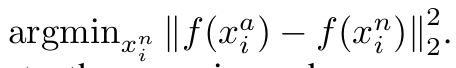
전체 세트에서 argmin과 argmax를 계산은 불가능하기 때문에 두 가지 중 하나로 선택해야 한다.
- 가장 최근의 네트워크 checkpoint를 기준으로 데이터의 서브셋에 대해 argmin과 argmax를 계산해서 n단계마다 오프라인으로 triplet을 생성한다.
- 온라인으로 triplet을 생성하여 미니 배치 내에서 hard positive/negative를 선택할 수 있다.
여기서 온라인 triplet 생성에 초점을 두고 미니 배치 내에서만 argmin,argmax를 계산한다.
모든 anchor-positive 쌍을 사용하면서 the hardest negative 쌍을 선택함으로써 모델의 안정성과 수렴 속도를 향상시킨다. triplet 선택은 빠른 수렴에 중요하며, 배치 크기는 hard triplet 선택 방법에 대한 주요 제약사항이다.
3.3 Deep Convolutional Network
표준 backprop과 SGD, AdaGrad를 사용했으며 학습률은 0.05이다. 두 가지의 아키텍처를 사용했는데 이 둘은 매개변수와 FLOPS에서 차이가 있다.
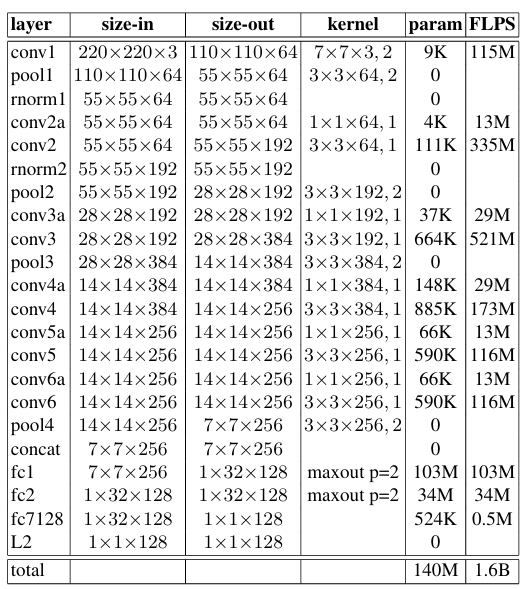
두 가지 주요 카테고리
- Zeiler & Fergus 아키텍처의 표준 합성곱 레이어 사이에 1x1 합성곱 레이어를 추가하여 깊이 22개의 모델을 형성
- GoogLeNet 스타일의 인셉션 모델을 기반으로, 매개변수와 FLOPS 측면에서 더 경량화되어 있으며, 일부 모델은 모바일 폰에서 실행 가능한 크기로 축소되어 있음
4 Datasets and Evaluation
4개의 데이터 세트에 대해 방법을 평가한다. 한 쌍의 두 얼굴이미지가 주어지면 L2 distance 임계값을 통해 same and different 분류를 결정한다.
4.1 Hold-out Test Set
훈련 세트와 유사한 분포를 가지지만 다른 사람의 이미지를 포함하는 약 백만 장의 이미지로 구성되어 있다. 평가를 위해 이를 다섯 개의 다른 세트로 분할하고, 각 세트에서 10만 x 10만 개의 이미지 쌍에 대한 FAR 및 VAL 비율을 계산하여 표준 오차를 보고한다.
4.2 Personal Photos
훈련 세트와 유사한 분포를 가진 깨끗한 라벨이 확인된 약 1만 2천 장의 이미지로 구성되어 있다. 모든 이미지 쌍에 대해 FAR 및 VAL 비율을 계산한다.
4.3 Academic Datasets
LFW와 Youtube Faces DB로 구성되어 있다. LFW는 얼굴 검증을 위한 표준 학술적 테스트 세트이며, Youtube Faces DB는 비디오 쌍을 사용한 새로운 데이터셋이다.
5 Experiments
5.1. Computation Accuracy Trade-off
특정 모델의 정확도와 FLOPS 사이에 상관관계가 있다. 계산량이 높을수록 정확도가 높아진다.
5.2.Effect of CNN Model
전통적인 Zeiler & Fergus 기반 아키텍처와 Inception 기반 모델을 선택하여 비교했을 때 최종적으로 두 아키텍처의 최상위 모델이 유사한 성능을 보이지만, Inception 기반 모델 중 일부는 FLOPS와 모델 크기를 크게 줄이면서도 좋은 성능을 유지한다.
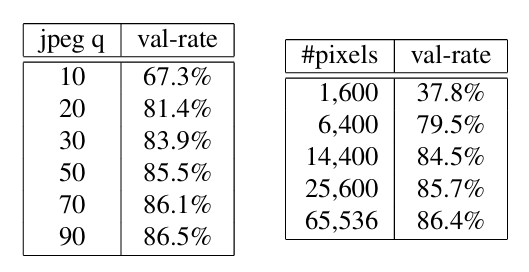
5.3. Sensitivity to Image Quality
다양한 품질의 이미지에서도 모델은 잘 작동한다.
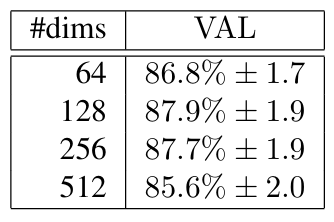
5.4. Embedding Dimensionality
128 차원의 임베딩을 선택하였으며, 이는 작은 차원과 비교하여 적어도 동등한 성능을 보인다.
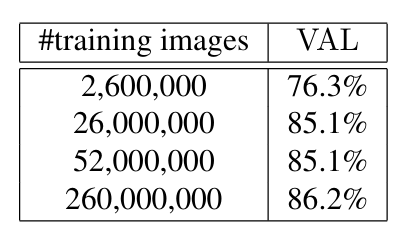
5.5. Amount of Training Data
대규모 훈련 데이터를 사용하면 개인 사진 테스트 세트에서 정확도를 크게 향상시킨다. 수백만 개의 이미지를 사용하는 경우 오차가 상대적으로 60% 감소한다.
5.6. Performance on LFW
LFW에서 우리 모델은 고정된 중앙 자르기를 사용하여 98.87%의 정확도를 가지며 추가 얼굴 정렬을 사용하면 표준 오차평균이 99.63%이다.
5.7. Performance on Youtube Faces DB
비디오의 첫 100프레임을 사용하여 얼굴 유사도의 평균을 계산하면 95.12%의 정확도를 가진다
5.8. Face Clustering
개인 사진을 사람별로 그룹화하는 데 사용되며 뛰어난 성능을 가진다

6 Summary
얼굴 검증을 위해 유클리드 공간에 임베딩을 직접 학습하는 FaceNet을 제공한다. end to end 학습을 통해 설정을 단순화하고 관련된 손실을 직접 최적화하여 성능을 향상시킨다. 또한 최소한의 정렬만으로도 성능을 향상시킬 수 있다.
7 Harmonic Embedding
조화 임베딩: 서로 다른 모델(v1 및 v2)에 의해 생성된 일련의 임베딩으로, 호환성을 가진다. 이는 업그레이드 경로를 단순화하고, 호환성을 통해 원활한 전환을 보장한다.
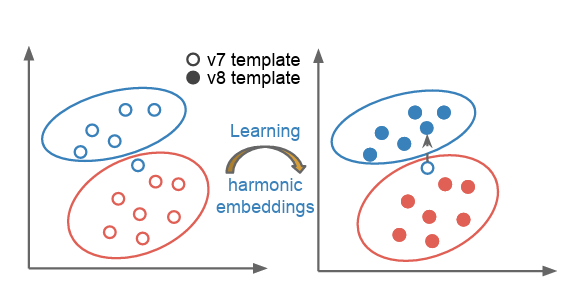
정확도가 떨어지는 임베딩에 대한 호환성을 유지하면서 검증 정확도를 향상시킬 수 있는 방법에 대한 가능한 해석 스케치
