https://arxiv.org/abs/1705.07874
Abstract
사용자가 복잡한 모델들의 예측을 해석하는 것을 돕기 위해 통합 프레임워크인 SHAP(SHapley Additive exPlanations)를 제시한다. SHAP는 각 기능에 특정 예측에 대한 중요도 값을 할당하여 이전 접근 방식보다 향상된 계산 성능 및 인간 직관과의 더 나은 일관성을 보여주는 새로운 방법이다.
1. Introduction
예측 모델의 출력을 올바르게 해석하는 능력은 매우 중요하다.
모델 출력의 정확성과 해석 가능성 간의 균형을 고려하여 다양한 방법이 제시되었다. 하지만 여전히 이런 방법들이 어떻게 관련되어있고, 어떤 방법이 더 선호되는지에 대한 이해는 부족하다.
따라서 모델 예측을 해석하기 위한 새로운 통합된 접근 방식을 제시한다. 이는 세 가지의 결과를 이끌어낼 수 있다.
-
explanation model: 모델 예측에 대한 설명을 모델 자체로 보는 관점
⇒ 현재 6개의 방법을 통합하는 additive feature attribution methods를 정의할 수 있음.
-
고유한 솔루션을 보장하는 게임 이론의 결과가 additive feature attribution methods에 적용됨을 보여줌.
다양한 방법들이 근사화하는 중요도의 통합된 척도로 SHAP을 제안함.
-
새로운 SHAP 값 추정 방법이 인간의 직관에 더 잘 부합하고 기존의 다른 방법들보다 더 효과적으로 구별함. /
2. Addictive Feature Attribution Methods
복잡한 모델은 이해하기 어렵기 때문에 해당 모델을 해석 (설명) 가능하도록 근사치로 정의한다.
f: 예측 모델 g: 설명 모델

2.1 LIME
LIME 방법은 예측을 바탕으로 모델을 국소적으로 근사하여 개별 모델 예측을 해석한다.
LIME은 해석 가능한 입력을 사용하며, 다른 유형의 입력에 대해 다른 매핑을 사용합니다. 설명 모델의 신뢰성은 local kernel 과 손실 함수를 사용하여 보장된다. 복잡성을 최소화하기 위해 퍄널티가 부여된 선형 회귀 (2)를 사용한다.
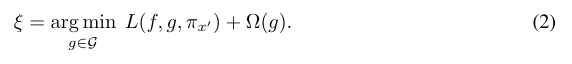
2.2 DeepLIFT
DeepLIFT는 딥러닝을 위한 재귀적 예측 방법으로 , 각 입력 xi에 대해 원래 값이 아닌 참조 값으로 설정될 때의 영향을 나타내는 C xi yi 값을 할당한다. (1: 원래 값 사용, 0: 참조 값 사용)
2.3 Layer-Wise Relevance Propagation
이는 심층 신경망의 예측 값을 해석하며, 모든 뉴런의 reference activation이 0으로 고정된 DeepLIFT와 동일하다.
위의 세 가지 방법은 협력 게임 이론의 고전 방정식을 사용하여 모델 예측에 대한 설명을 계산한다.
2.4 Classic Shapley Value Estimation
Shapley 회귀 값은 다중공선성이 있는 선형 모델의 특성 중요도를 나타내며, 특성을 포함하거나 제외할 때 모델 예측에 미치는 영향을 계산한다.
F: 모든 입력값, S: F의 서브셋, fs: 모델
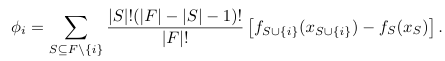
Shapley 샘플링 값은 모든 모델을 설명하고 변수를 제거하는 효과를 통합하여 모델을 다시 훈련할 필요 없이도 작동한다. Quantitative input influence는 Shapley 값에 대한 샘플링 근사치를 제안한다.
3 SimpleProperties Uniquely Determine Additive Feature Attributions
additive feature attribution methods의 특징은 아래 세가지 속성에 대해 하나의 고유한 솔루션을 가지고 있다는 것이다.
특성 1 Local Accuracy
원래 모델 f를 근사할 때, 설명 모델 g에 단순화된 입력값에 대한 출력값과 일치해야한다.
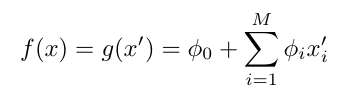
특성 2 Missingness
입력을 단순화할 때, 입력에서 누락된 기능이 영향을 미치지 않아야 한다.
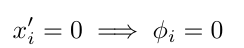
특성 3 Consistency
모델이 변경되어 일부 단순화된 입력이 증가하거나 유지되는 경우 해당 입력의 속성이 감소되면 안된다.
4 SHAP(SHapley Additive exPlanation) Values
기능 중요도의 통합된 척도로 SHAP값을 제안한다.
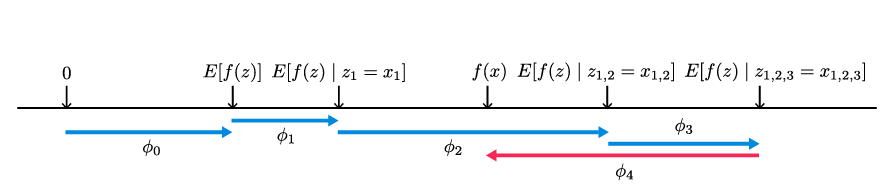
이 값들은 각 특성이 조건에 따라 모델 예측에 미치는 변화를 나타내며, SHAP 값은 기본 값에서 현재 출력까지의 이동을 설명한다. SHAP 값은 모든 가능한 순서에서 특성을 추가하여 평균화된다.
SHAP 값은 모델 예측을 설명하는 유일한 additive feature importance measure를 제공하며, 조건부 기대값을 사용하여 단순화된 입력을 정의한다. SHAP 값의 정확한 계산은 어렵지만, 여러 Addictive Feature Attribution 방법들을 결합하여 근사할 수 있다. 이 방법에는 Shapley 샘플링 값과 Kernel SHAP이 포함되며, 모델 유형에 따라 다른 근사치 방법이 사용된다.

4.1 Model-Agnostic Approximations
조건부 기대값을 근사할 때 특성 독립성을 가정하면 SHAP 값은 Shapley 샘플링 값 방법이나 Quantitative Input Influence 방법을 사용하여 직접 추정할 수 있다. 이러한 방법은 전통적인 Shapley 값 방정식의 샘플링 근사화를 수행하며 각 특성 기여에 대해 별도의 샘플링 추정을 수행한다. 입력이 적을 경우에 대해 계산하기에 합리적이지만 Kernel SHAP 방법은 원래 모델의 평가 횟수를 줄여 유사한 근사 정확도를 제공한다.
Kernel SHAP
Kernel SHAP는 선형 LIME과 Shapley 값의 결합으로, 선형 LIME은 지역적으로 f를 선형 모델로 근사하며, 이는 지역적 정확성, 누락 및 일관성을 만족하는 Shapley 값이 유일한 해임을 뜻한다. 그러나 실제로 선형 LIME의 매개 변수 선택은 Shapley 값을 복원하지 못하고 지역적 정확성 및 일관성을 위배한다. 이를 방지하기 위해 식 2의 매개 변수를 경험적으로 선택하는 대신 Shapley 값을 복원하는 방법을 제안한다.
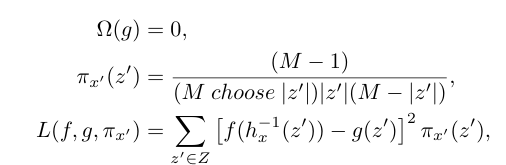
4.2 Model-Specific Approximations
Kernel SHAP은 모델에 구애받지 않는 SHAP값 추정의 샘플 효율성을 개선하지만 특정 모델 유형에 대해 제한함으로써 모델 별로 더 빠른 근사 방법을 개발할 수 있다.
Linear SHAP
선형 모델에서는 input feature의 독립성을 가정하면 SHAP값은 모델의 가중치 계수에서 직접 근사 가능하다.
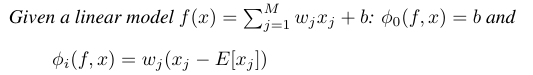
Low-Order SHAP
조건부 기대값의 근삿값을 선택하면 작은 값의 M에 효율적이다.
MaxSHAP
Shapley 값의 순열 공식을 사용하여 각 입력이 다른 모든 입력에 비해 최대값을 증가시킬 확률을 계산할 수 있다.
Deep SHAP(DeepLIFT + Shapley values)
Deep SHAP은 딥 네트워크의 구성적 특성을 활용하여 SHAP 값의 계산 성능을 향상시키는 방법으로, Shapley 값과 DeepLIFT 간의 연결을 통해 발견되었다.
DeepLIFT는 input feature가 서로 독립적이고 딥 모델이 선형일 때 SHAP 값을 근사한다. Deep SHAP는 작은 네트워크 구성 요소에 대한 SHAP 값을 결합하여 전체 네트워크에 대한 SHAP 값을 생성하고, 이를 통해 전체 모델의 값에 대해 빠르게 근사치를 얻어낸다. Deep SHAP은 구성 요소를 선형화하는 데 경험적으로 선택한 방법 대신 각 구성 요소에 대한 SHAP 값을 활용하여 효과적으로 선형화한다.
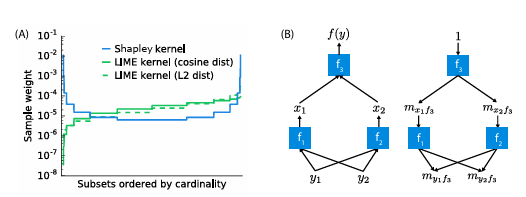
(A) Shapley kernel weighting의 효과
(B) 구성 요소의 Shapley 값에 대한 분석 솔루션을 통해 전체 모델에 대한 빠른 근사치 생성
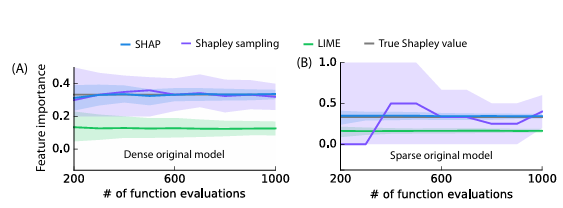
3가지 additive feature attribution 방법들 간의 비교
5 Computational and User Study Experiments
- 계산 효율성: Kernal SHAP은 Shapley값과 가중 선형 회귀와의 연결을 통해 원래 모델의 평가 횟수를 줄여 더 정확한 추정치가 생성된다.
- 인관 직관과의 일관성: LIME, DeepLIFT 및 SHAP를 실험해봤을 때, SHAP에서의 가장 높은 일관성을 보였다.
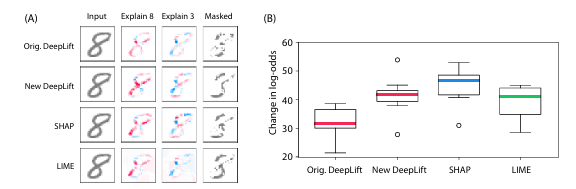
DeepLIFT의 SHAP 값에 가까운 추정치의 향상된 성능을 보여준다.
6 Conclusion
모델 출력의 정확성과 해석 가능성 간의 균형을 고려하며 예측을 해석하는 데 도움이 되는 방법으로 SHAP이 나왔다.
SHAP은 additive feature importance methods의 클래스를 식별하고 이 클래스에 원하는 원하는 속성을 준수하는 각각의 고유한 솔루션이 있음을 보여준다.
