Abstract
Transformers-based 방법이 Image Deraining (이미지에서 빗줄기 제거)에서 좋은 성능을 보인다. 하지만 기존의 Transformer 모델은 Query와 Key의 토큰이 다를 경우 이미지 복원에 방해가 될 수 있다.
이를 해결하기 위해 DRSformer가 제안되었는데, 이는 가장 유용한 self-attention 값을 쿼리마다 알맞게 유지하여 더 나은 feature를 집계하도록 한다. 또한, 이미지 추론을 위한 더 나은 피처를 생성하기 위해 mixed-scale feed-forward network를 도입하고, CNN 연산자의 로컬 콘텍스트를 결합하는 하이브리드 피처를 학습하기 위한 experts feature compensator를 도입한다.
Introduction
- 이미지에서 빗줄기 제거 문제:
- 최근에 등장한 저수준 비전 문제로, 비오는 날 촬영된 이미지로부터 깨끗한 이미지를 복원하는 것이 목표이다.
- 깨끗한 이미지와 비 자국이 알려지지 않은 역문제로, 통계적 특성에 기반한 다양한 사전 확률을 적용하는 초기 방법들은 한계가 있음.
- 학습 기반 방법의 등장:
- 학습 기반 방법은 CNN 아키텍처를 활용하며, 전통적인 알고리즘에 비해 선호되지만, CNN의 특성으로 인해 장거리 비로 인한 손상을 효과적으로 처리하는 능력이 제한됨.
- CNN과 Transformer의 결합:
- 이미지에서 빗줄기 제거에서 Transformer가 사용되지만 지역적인 이미지 세부 정보를 제대로 모델링하지 못하는 한계가 있어, CNN과 Transformer를 결합한 방법이 제안되고 있음.
- Sparse Transformer 아키텍처:
- Sparse Transformer 아키텍처인 DRSformer를 제안함.
- 이는 self-attention 값의 선택을 통해 더 나은 feature aggregation을 가능하게 함.
- TKSA & MSFN:
- TKSA: 가장 유용한 self-attention 값을 유지하기 위한 학습 가능한 top-k 선택 연산자임.
- MSFN: multi-scale feature를 탐색하여 이미지 복원을 개선함.
- MEFC:
- MEFC: 데이터와 콘텐츠의 희소성을 함께 탐색하여 빗줄기 제거의 성능을 향상시킴.
Related Work
- Single image deraining: 기존의 방법들은 손으로 만든 이미지 선행 조건을 사용했으나 이는 경험적인 관찰에 의존하기 때문에 명확한 이미지 특성을 모델링하는 데 한계가 있다. 최근에는 CNN 기반의 프레임워크가 개발되었으며, 이는 이미지 빗줄기 제거에서 괜찮은 복원 성능을 보여준다.
- Sparse representation: 심층 신경망의 숨겨진 표현의 희소성이 이미지 빗줄기 제거와 같은 낮은 수준의 시각 문제를 다루는 데 중요한 역할을 한다. 이 논문에서는 콘텐츠 기반 희소성을 위해 self-attention의 근사값을 도입한다.
- Top-k selection: Top-k selection은 NLP에서 제안한 것으로, 효율적인 top-k 유용한 채널 선택 연산자를 설계하여 가장 관련성 높은 정보를 선택한다.
Overall Pipeline
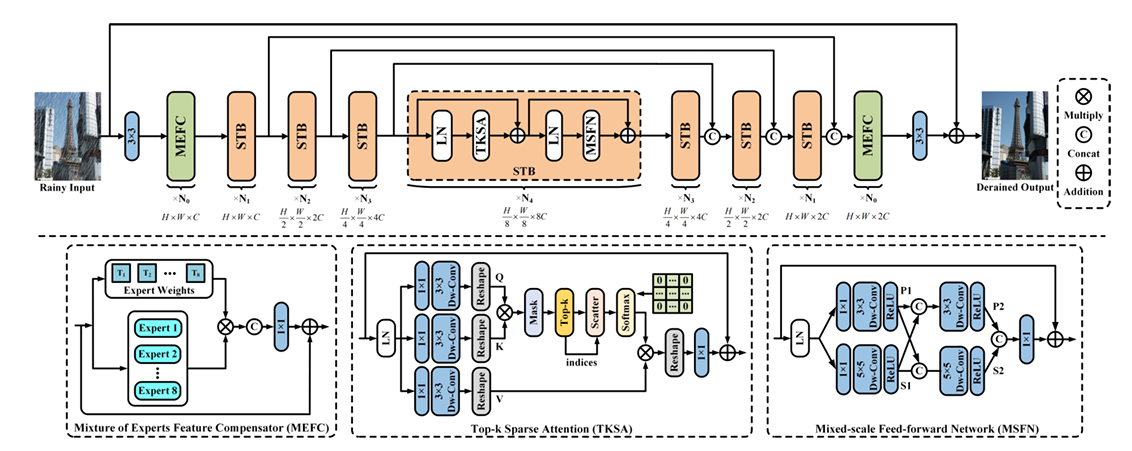
DRSformer는 hierarchical encoder-decoder 프레임워크를 기반으로 하며, 특징 희소성을 달성하기 위해 TKSA와 MSFN을 도입한다.
비의 영향을 받은 이미지를 입력으로 받고, image patch embedding을 통해 처리한다. 네트워크 backbone에서는 STB를 통해 feature를 추출하고, 각 레벨의 인코더-디코더 파이프라인이 특정한 공간 해상도와 채널 차원을 다룬다.
TSKA를 통해 feature sparsity를 달성하고, MSFN을 통해 multi-scale local 정보를 풍부하게 한다. 학습의 초기 및 최종 단게에선 MEFC로 추가적인 feature 정제를 한다. 이러한 과정을 통해 비의 영향을 효과적으로 처리하여 높은 품질으 ㅣ임지를 생산한다.
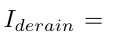
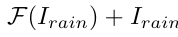
최종 재생산된 결과는 위의 공식에 의해 구해진다.
Sparse Transformer Block (STB)
표준 Transformer의 밀집한 self-attention 대신에 SparseTransformer block (STB)은 특정한 정보만을 고려한다. 이를 통해 관련 없는 정보의 개입을 피하고 특정 정보에만 집중할 수 있다.
STB의 인코딩 절차

Top-k sparse attention (TKSA)
표준 Transformer의 밀집한 self-attention 대신에 도입된 매커니즘으로, 주어진 쿼리, 키, 값에 대한 유사도를 계산하는 과정에서 특정 정보만을 고려한다. 이를 통해 관련 없는 정보의 개입을 피하고, 상위 k개의 중요한 요소를 유지하여 특징 상호 작용 과정에서 효율적으로 작동한다.
Dynamic Selection이 attention을 dense → sparse로 만드는 과정
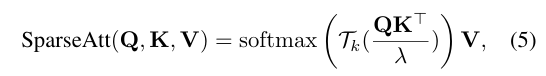
Mixed-scale feed-forward network (MSFN)
여러 규모의 특징을 활용하여 지역 정보를 향상시키는 매커니즘이다. 이전 연구들은 단일 규모의 깊이별 컨볼루션을 도입하여 지역성을 향상시켰지만, MSFN은 여러 다른 규모의 컨볼루션 브랜치를 도입하여 다양한 규모의 정보를 추출하여 빗줄기 제거에 더 효과적으로 활용합니다.
the entire feature fusion procedure of the developed MSFN
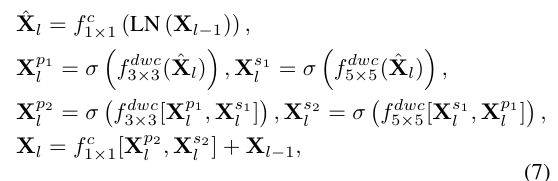
Mixture of Experts Feature Compensator (MEFC)
MEFC는 DRSformer에 희소성을 통합하기 위해 도입되었다.
다양한 희소 CNN 연산을 병렬 레이어로 선택하여 전문가로 구성한다. 이들은 3 × 3의 수용 영역을 갖는 평균 풀링, 커널 크기가 1 × 1, 3 × 3, 5 × 5, 7 × 7인 분리 가능한 컨볼루션 레이어 및 커널 크기가 3 × 3, 5 × 5, 7 × 7인 팽창된 컨볼루션 레이어를 포함한다.
피쳐 맵 입력시, channel wise average를 적용하여 C-dimensional channel descriptor Zc 생성
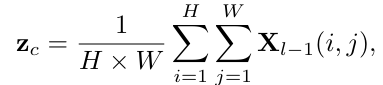
self-attention을 사용하여 다양한 표현의 중요성을 적응적으로 선택합니다. 각 전문가의 계수 벡터는 학습 가능한 가중치 행렬에 할당되고, 입력 및 출력의 크기를 변경하지 않기 위해 각 전문가에 의해 계산된 입력 피쳐 맵을 zero pad한다. 이로 인해 MEFC는 다양한 모습의 빗줄기를 상황에 맞게 제거할 수 있다.
The output of the l-th MEFC
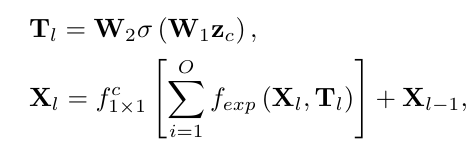
Experiments and Analysis
Comparisons with the state-of-the-arts
합성 데이터셋: DRSformer가 다른 모든 영상 복원 방법보다 성능이 좋다. 특히 PSNR에서 우수한 결과를 보인다. 이는 이전의 CNN 기반 모델들과 비교하여 더욱 명확한 향상을 보인다. 또한, 다양한 빗줄기를 적절하게 처리할 수 있는 능력을 보이며, 시각적 품질 비교를 통해 이를 확인할 수 있음.
실제 세계 데이터셋: DRSformer가 다른 모델들과 비교하여 우수한 성능을 보인다. 심지어 실제 비가 오는 이미지에서도 높은 품질을 제공하며, 이는 실제 비 영상에서도 잘 일반화될 수 있다.
Ablation Studies
- Top-k selection의 Effectiveness: 이미지 구조의 픽셀 의존적 특성을 효과적으로 활용하고 보다 정밀한 고주파 세부 정보를 생성 가능하다.

- 숫자 k의 Effectiveness: 최적의 k 선택은 희소도 비율의 경계를 결정한다.
- MSFN의 Effectiveness: 다양한 스케일에서 로컬 특성 추출 및 퓨전을 추가하여 성능을 향상시킨다.
- MEFC의 Effectiveness: 보조 데이터 희소성 덕분에 추가적인 성능 향상 제공한다.
Conclusion
DRSformer는 효과적인 Sparse Transformer 네트워크로 image derainig을 해결하기 위해 개발되었다. 전통적인 Transformer의 self-attention에 비해 top-k sparse attention을 도입하여 self-attention 값을 유지하고 더 나은 feature aggregation을 가능하게 했다. 이를 위해 MSFN과 MEFC를 도입하여 피쳐를 aggregate하고, 모델의 세부사항을 보존했다.
