arxiv.org/pdf/2307.04725
Abstract
AnimateDiff라는 프레임워크와 MotionLoRA라는 기법에 관한 논문이다. AnimateDiff는 개인화된 텍스트-이미지 모델에 동적인 움직임을 추가하는 새로운 방법이다.
한 번 훈련된 후 다양한 개인화된 텍스트-이미지 모델에 쉽게 통합될 수 있는 동작 모듈로 실제 비디오에서 동작의 선행 사항을 학습하여 전이 가능한 동작 지식을 얻는다. 한 번 훈련되면, 개인화된 텍스트-이미지 모델에 삽입되어 애니메이션 생성기를 생성할 수 있다.
MotionLoRA는 AnimateDiff를 위해 도입된 fine tuning 기술로, 사전 훈련된 동작 모듈이 새로운 동작 패턴에 적응할 수 있도록 한다.
Introduction
AnimateDiff는 개인화된 Text-to-image 모델을 애니메이션 생성기로 직접 변환하는 효과적인 파이프라인이다.
핵심은 비디오 데이터셋에서 합리적인 동작 선행 사항을 학습하는 plug and play 동작 모듈을 훈련하는 것으로 AnimateDiff의 동작 모듈 훈련은 세 단계로 구성된다.
- 도메인 어댑터를 기본 T2I에 미세 조정하여 대상 비디오 데이터셋의 시각적 분포와 일치시킨다.
- 도메인 어댑터와 기본 T2I를 함께 확장하고 동작 모델링을 위해 새로 초기화된 동작 모듈을 도입하여 비디오에서 이 모듈을 최적화한다.
- MotionLoRA 단계에서는 소수의 참조 비디오와 훈련 반복을 사용하여 사전 훈련된 동작 모듈을 특정 동작 패턴에 맞게 fine tuning한다. 적은 비용으로도 사전 훈련 시 특정 효과를 위해 동작 모듈을 미세 조정이 가능하다.
다양한 개인화된 T2I 모델을 이용하여 AnimateDiff와 MotionLoRA의 성능을 평가하는데 2D 만화부터 사실적인 사진에 이르기까지 다양한 도메인을 포괄한다.
실험 결과를 요약하면
(1) AnimateDiff는 특정 미세 조정 없이 개인화된 T2I의 애니메이션 생성 능력을 가능하게 하는 실용적인 파이프라인을 제시한다
(2) Transformer 구조가 동작 선행 사항을 모델링하는 데 충분함을 검증한다
(3) 새로운 동작 패턴에 사전 훈련된 동작 모듈을 적응시키기 위한 경량 미세 조정 기술인 MotionLoRA를 제안한다.
(4) 대표적인 커뮤니티 모델들을 이용해 종합적으로 평가하며 기존 작업과의 호환성을 보여준다.
Related Work
Text-to-image diffusion models
- GLIDE: 텍스트 조건을 도입하고 분류기 가이드를 통합함
- DALL-E2: CLIP 공동 특징 공간을 활용하여 텍스트-이미지 정렬을 개선함
- Imagen: 대규모 언어 모델과 계단식 아키텍처를 도입하여 사실적인 결과 달성
- Latent Diffusion Model: 자동 인코더의 잠재 공간으로 확산 과정을 이동시킴
- eDiff-I: 다양한 생성 단계에 특화된 확산 모델 앙상블을 사용함
Personalizing T2I models
기본 T2I에 참조 이미지를 사용하여 개념이나 스타일을 도입하는 방법
⇒ 전체 모델을 미세 조정하여 전반적인 품질을 크게 향상시킬 수 있지만, 참조 이미지 세트가 작을 경우 catastrophic forgetting을 유발할 수 있음
대안 방법
- DreamBooth: 보존 손실을 사용하여 전체 네트워크를 미세 조정하고 소수의 이미지만을 사용
- Textual Inversion: 각 새로운 개념에 대한 토큰 임베딩을 최적화
- Low-Rank Adaptation (LoRA): 기본 T2I에 추가 LoRA 계층을 도입하고 가중치 residuals만 최적화하여 위의 미세 조정 과정을 용이하게 함
Animating personalized T2Is
- Text2Cinemagraph: 흐름 예측을 통해 영화적 이미지를 생성하는 방법을 제안
- Align-Your-Latents: 일반 비디오 생성기의 고정된 이미지 계층을 개인화
- Tune-a-Video: 단일 비디오에서 소수의 매개변수를 미세 조정
- Text2Video-Zero: 미리 정의된 affine matrix를 통해 잠재적 래핑을 통해 훈련이 없는 방법을 도입
Preliminary
Stable Diffusion
이 논문에서 사용된 기본 T2I 모델로, 오픈 소스이며 많은 고품질의 개인화된 T2I 모델을 평가할 수 있는 잘 개발된 커뮤니티를 가지고 있다. SD는 사전 훈련된 자동 인코더의 잠재 공간에서 확산 과정을 수행하며, 이미지를 인코딩하고 잡음을 추가한 후, 이를 역전시켜 잡음을 예측하는 네트워크를 통해 학습된다.
Low-Rank Adaptation, LoRA
큰 모델의 미세 조정을 가속화하는 접근 방식으로, 모든 모델 매개변수를 재훈련하는 대신 순위 분해 행렬 쌍을 추가하고 이 새롭게 도입된 가중치만 최적화한다. 이는 훈련 가능한 매개변수를 제한하고 원래 가중치를 고정시켜 catastrophic forgetting을 덜 유발할 수 있다. LoRA는 주로 attention 계층에만 적용되어 모델 미세 조정의 비용과 저장 공간을 줄인다.
AnimateDiff
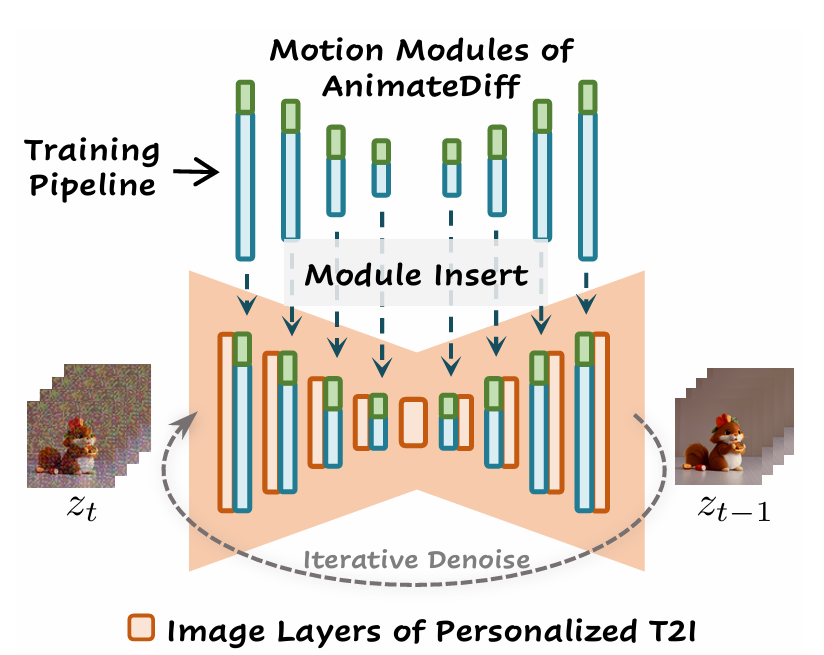
비디오 데이터에서 이동 가능한 동작 선행 사항을 학습하여 특정 미세 조정 없이 개인화된 T2I에 적용한다.
추론 시에는 동작 모듈(파란색)과 선택적인 MotionLoRA(녹색)를 개인화된 T2I에 직접 삽입하여 애니메이션 생성기를 구성하고, 이후 반복적인 노이즈 제거 과정을 통해 애니메이션을 생성한다. 이를 위해 AnimateDiff의 도메인 어댑터, 동작 모듈, MotionLoRA를 훈련한다.
1) 도메인 어댑터: 훈련 중에만 사용되어 기본 T2I 사전 훈련 데이터와 비디오 훈련 데이터 간의 시각적 분포 격차로 인한 부정적인 영향을 완화함
2) 동작 모듈: 동작 선행 사항을 학습하는 데 사용됨
3) MotionLoRA: 일반 애니메이션의 경우 선택적으로 사전 훈련된 동작 모듈을 새로운 동작 패턴에 적응시키기 위해 사용됨
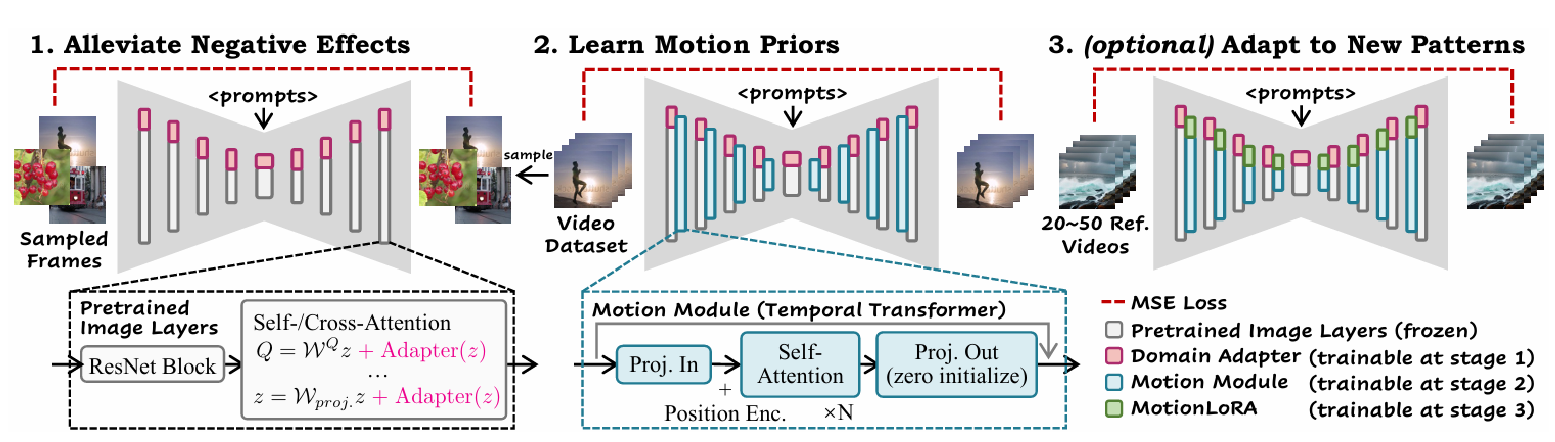
1. 도메인 어댑터를 통한 훈련 데이터의 부정적인 영향 완화
공개적으로 이용 가능한 비디오 훈련 데이터셋의 시각적 품질이 이미지 데이터셋에 비해 낮은 문제가 있다. 이러한 품질 차이는 기본 T2I를 훈련시킨 고품질 이미지 데이터셋과 우리가 동작 선행 사항을 학습하기 위해 사용하는 대상 비디오 데이터셋 간의 품질 격차를 발생시킨다. 이러한 격차는 원시 비디오 데이터에 직접 훈련될 때 애니메이션 생성 파이프라인의 품질을 제한할 수 있다.
동작 모듈의 일부로 학습하는 것을 피하고 기본 T2I의 지식을 보존하기 위해, 도메인 정보를 별도의 네트워크인 도메인 어댑터에 맞춘다. 추론 시에 도메인 어댑터를 제거하는 방법은 도메인 간격으로 인한 부정적인 영향을 줄이는 데 도움이 된다. LoRA를 사용하여 도메인 어댑터 계층을 구현하고 기본 T2I의 자기주의/교차주의 계층에 삽입한다.
2. 동작 모듈로 동작 사전 학습
시간 차원을 따라 동작 역학을 모델링하기 위해 2차원 확산 모델을 3차원 비디오 데이터를 다룰 수 있도록 확장하고 시간 축을 따라 효율적인 정보 교환을 가능하게 하는 모듈을 설계해야 한다.
네트워크 확장: 기본 T2I 모델의 사전 훈련된 이미지 레이어는 고품질의 내용 선행 사항을 포착한다. 이미지 레이어가 비디오 프레임을 독립적으로 처리하도록 하기 위해 모델을 수정하여 5D 비디오 텐서를 입력으로 받는다.
내부 피처 맵이 이미지 레이어를 통과할 때, 시간 축 f는 배치 축 b으로 재구성되어 네트워크가 각 프레임을 독립적으로 처리하도록 한 후, 피처 맵을 이미지 레이어 후에 다시 5D 텐서로 재구성한다.
모듈 설계: AnimateDiff에서는 동작 모듈 설계로 트랜스포머 아키텍처를 채택하여 "시간 트랜스포머"로 부르며, 시간 축을 따라 작동하도록 수정했다.
시간 트랜스포머는 시간 축을 따라 여러 자기주의 블록으로 구성되며, 사인 위치 인코딩을 사용하여 각 프레임의 위치를 인코딩한다. 모듈의 입력은 공간 차원이 배치 축과 병합된 재구성된 피처 맵으로, 시간 축을 따라 벡터 시퀀스로 간주된다. 벡터들은 투영되어 여러 자기주의 블록을 통과하며, 현재 프레임 생성에 다른 프레임의 정보를 통합할 수 있게 한다.
3. Motion LoRA로 새로운 모션 패턴에 적응
사전 훈련된 동작 모듈은 일반적인 동작 선행 사항을 포착하지만, 새로운 동작 패턴에 적응할 때는 소수의 참조 비디오와 제한된 훈련 반복으로 인해 문제가 발생한다. 이는 특정 효과를 위해 동작 모듈을 미세 조정하고자 하지만 비싼 사전 훈련 비용을 감당할 수 없는 사용자에게 필요한데 이를 해결하기 위해 AnimateDiff의 MotionLoRA가 도입되었다.
MotionLoRA는 동작 개인화를 위한 효율적인 미세 조정 접근법으로 동작 모듈의 아키텍처와 참조 비디오의 제한된 수를 고려하여, 확장된 모델의 자기주의 계층에 LoRA 계층을 추가하고 이를 새로운 동작 패턴의 참조 비디오에서 훈련한다.
여러 종류의 샷과 데이터 증강을 통해 참조 비디오를 얻는다. 낮은 순위 속성으로 인해 MotionLoRA는 구성 능력도 갖추고 있어, 개별적으로 훈련된 MotionLoRA 모델들을 결합하여 추론 시에 구성된 동작 효과를 달성할 수 있다.
4. AnimateDiff in practice
AnimateDiff는 세 개의 주요 훈련 구성 요소로 동작 선행 사항을 학습한다. 최종 목표는 확장된 모델은 노이즈가 처리된 잠재 코드와 텍스트 프롬프트를 입력받아 추가된 노이즈를 예측하는 것이다.
추론 시, 개인화된 T2I 모델은 동작 모듈과 필요에 따라 MotionLoRA를 포함시켜 애니메이션을 생성한다. 도메인 어댑터는 모델에 주입되어 스칼라 값의 조정을 통해 기여도를 조절한다. 이 모든 과정은 시각적 내용의 변화를 시간에 따라 포착하여 애니메이션의 동작 동역학을 구현하는 데 중점을 둔다.
Experiments
Qualitative Results
T2I는 특정 "트리거 단어"에만 반응하기 때문에, 일반적인 텍스트 프롬프트 대신 모델 홈페이지를 참조하여 평가 프롬프트를 구성했다. 아래의 각 샘플은 독특한 개인화된 T2I이다.

기존에 개인화된 T2I를 애니메이션화하기 위해 특별히 설계된 기존 방법이 없기 때문에, 우리는 이 작업에 적용할 수 있는 두 개의 최근 비디오 생성 작업인 Text2Video-Zero와 Tune-a-Video의 이미지와 비교했다.

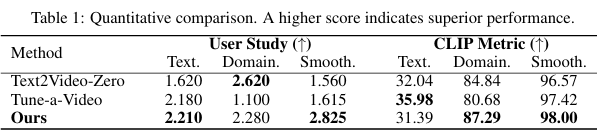
Quantitative Comparison
Ablative Study
Domain adapter

어댑터의 스케일이 감소함에 따라 시각적 품질이 향상되며 학습된 시각적 내용 분포가 감소하고 있음. → 도메인 어댑터가 동작 모듈이 시각적 분포 격차를 학습하는 것을 완화함으로써 AnimateDiff의 시각적 품질을 향상시킴
Motion module design
시간 트랜스포머의 동작 모듈 디자인을 전체 컨볼루션과 비교했을 때 컨볼루셔널 모션 모듈은 모든 프레임을 동일하게 정렬하지만 모션을 통합하지 않는다.
Efficiency of Motion LoRA
첫 두 사진은 MotionLoRA가 작은 매개변수로 새로운 카메라 동작을 학습할 수 있으며 좋은 품질을 유지함을 보여준다.
오른쪽 세 사진은 참조 비디오의 수가 많이 제한될 때(예: N=5), 품질이 현저하게 저하되어 MotionLoRA가 공유된 동작 패턴을 학습하는 데 어려움을 겪고 참조 비디오에서 텍스처 정보를 포착하는 것에 의존함을 보여준다.

Controllable Generation

AnimateDiff는 시각적 내용과 동작 선행 사항을 분리하여 학습함으로써 기존의 컨텐츠 제어 방식을 적용할 수 있게 한다.
이는 무작위 노이즈에서 애니메이션을 생성하며, 미세한 동작 세부사항과 높은 시각적 품질을 제공한다.
Conclusion
AnimateDiff는 실용적인 파이프라인으로 이는 개인화된 텍스트-이미지(T2I) 모델을 품질 저하나 사전 학습된 도메인 지식의 손실 없이 한 번에 애니메이션 생성으로 직접 전환한다.
이를 위해 AnimateDiff는 의미 있는 동작 선행 사항을 학습하면서 시각적 품질 저하를 완화하고 MotionLoRA라는 경량 미세 조정 기술을 통해 동작 개인화를 가능하게 하는 세 가지 구성 요소 모듈을 설계했다. 훈련된 후, 동작 모듈은 다른 개인화된 T2I에 통합되어 개인화된 도메인에 맞게 자연스럽고 일관된 동작의 애니메이션 이미지를 생성할 수 있다.
