Abstract
텍스트를 입력하여 실제 이미지를 수정하는 예시

텍스트를 기반으로 한 복잡한 이미지 편집을 실제 이미지에 적용하는 방법을 도입한다. 한 이미지 내에서 여러 객체의 자세나 구성을 변경할 수 있다. 단일 입력 이미지와 대상 텍스트만 필요로 하며, 실제 이미지에서 작동하며 추가 입력이 필요하지 않다. 이를 통해 다양한 입력을 통해 고품질의 복잡한 의미적 이미지 편집을 단일 통합된 프레임워크 내에서 실현한다.
Introduction
현재 주요 텍스트 기반 이미지 편집 방법들은 특정 편집 세트에만 제한되거나 특정 도메인의 이미지에만 작동하거나 합성 생성된 이미지에만 작동한다. 혹은입력 이미지 외에 보조 입력이 필요하다는 단점을 가지고 있다.
위의 문제를 해결하기 위해 의미적 이미지 편집 방법을 제안한다. 입력 이미지를 편집할 때 사용할 단일 텍스트 프롬프트만 제공되면, 실제 고해상도 이미지에 정교한 non-rigid 편집을 할 수 있다. 결과 이미지 출력은 대상 텍스트와 잘 일치하면서도 원본 이미지의 전반적인 배경, 구조 및 구성을 보존한다. Imagic은 고해상도 이미지에 정교한 조작을 적용하는 텍스트 기반 의미적 편집을 하며 스타일 변경, 색상 변경 및 객체 추가를 포함한 다양한 편집도 가능하다.
이를 위해 높은 품질의 이미지 합성이 가능한 텍스트 대 이미지 확산 모델을 활용한다. 자연어 프롬프트를 통해 텍스트와 잘 일치하는 이미지를 생성하는 이 모델을 통해 새 이미지를 합성하는 대신 실제 이미지를 편집한다.
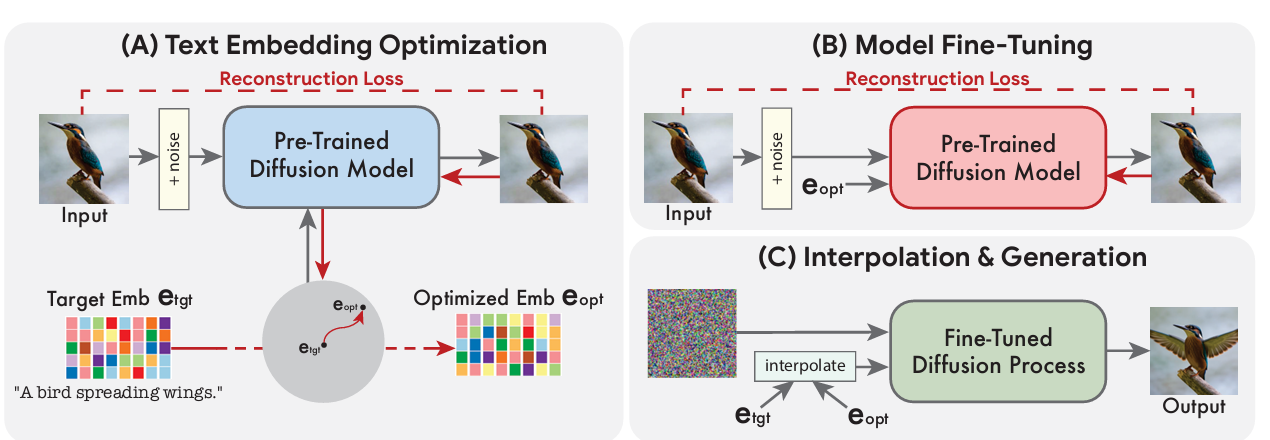
1) 텍스트 임베딩을 최적화하여 입력 이미지와 유사한 이미지를 생성
2) 사전 훈련된 생성 확산 모델을 세밀하게 조정하여 입력 이미지를 재구성
3) 대상 텍스트 임베딩과 최적화된 텍스트 임베딩 사이를 선형 보간하여 입력 이미지와 대상 텍스트를 모두 결합한 표현을 생성 → 이 표현은 생성 확산 프로세스로 전달되어 최종 편집된 이미지 출력
-
Imagic: 단일 실제 입력 이미지에서 복잡한 non-rigid 편집을 허용하는 첫 번째 텍스트 기반 의미적 이미지 편집 기술
-
두 텍스트 임베딩 시퀀스 간 의미 있는 선형 보간을 시연하며, 텍스트 대 이미지 확산 모델을 합성한다.
-
TEdBench: 다양한 텍스트 기반 이미지 편집 방법을 비교할 수 있는 새로운 복잡한 이미지 편집 벤치마크
Related Work
사전 훈련된 생성적 적대 신경망(GANs)의 잠재 공간을 활용하여 다양한 이미지 조작을 수행하는 연구들이 많이 이루어졌다. 이런 조작을 실제 이미지에 적용하는 여러 기술이 제안되었는데, 최적화 기반 방법, 인코더 기반 방법, 입력별 모델 조정 방법 등이 있다.
GAN 외에도 이미지 편집을 위해 다른 심층 학습 기반 시스템을 활용하는데 전역적인 편집에 한정된 SDEdit과 DDIB, 텍스트 및 이미지를 이용하여 이미지를 합성하는 방법 등이 있다.
이 논문에서는 단일 실제 이미지에 작동하며 이미지를 높은 fidelity로 유지하고 자유 형식의 자연어 텍스트 프롬프트를 기반으로 non-rigid 편집을 적용하는 첫 번째 텍스트 기반 의미적 이미지 편집 도구를 제공한다.
Imagic: Diffusion-Based Real Image Editing
Preliminaries
확산 모델의 핵심 아이디어는 무작위로 샘플링된 잡음 이미지를 초기화한 후, 제어된 방식으로 반복적으로 세밀하게 수정하여 사실적인 이미지를 합성하는 것이다. 각 중간 샘플은 뉴럴 네트워크에 의해 현재 샘플에 적용된 후 무작위 가우시안 잡음 변형을 거친다. 이 네트워크는 노이즈 제거 목표로 훈련되며, 원하는 대상 분포와 높은 fidelity를 갖는 학습된 이미지 분포를 만들어낸다.
이 방법은 조건부 분포를 학습하는 데 일반화될 수 있으며, 조건부 입력으로 노이즈 제거 네트워크를 조건으로 설정함으로써 조건부 분포에서 샘플링할 수 있다. 이를 통해 사용자는 원하는 장면을 설명하는 텍스트 프롬프트만 사용하여 실제적인 고해상도 이미지를 생성할 수 있다. 먼저 생성적 확산 프로세스를 사용하여 저해상도 이미지를 합성한 다음, 추가 보조 모델을 사용하여 고해상도 이미지로 변환된다.
Our Method
입력 이미지 x와 원하는 편집을 설명하는 텍스트가 주어졌을 때, 주어진 텍스트를 만족시키면서 입력 이미지 x의 최대한 많은 세부 정보를 보존하면서 이미지를 편집하는 것이 목표이다.
이를 위해 우리는 확산 모델의 텍스트 임베딩 레이어를 활용하여 의미적 조작을 한다. GAN방식과 유사하게, 먼저 생성 프로세스를 통해 주어진 이미지와 유사한 이미지를 생성하는 표현을 찾고 생성 모델을 세밀하게 조정하여 입력 이미지를 재구성하고, 잠재적 표현을 조작하여 편집 결과를 얻는다.
- 주어진 이미지와 대상 텍스트 임베딩 근처에서 가장 잘 맞는 텍스트 임베딩을 최적화
- 주어진 이미지와 더 잘 일치하도록 확산 모델을 세밀하게 조정
- 최적화된 임베딩과 대상 텍스트 임베딩 사이를 선형 보간하여 입력 이미지와 대상 텍스트의 정렬을 모두 달성하는 지점을 찾는다.
-
Text embedding optimization
텍스트는 텍스트 인코더를 통해 전달되어 해당하는 텍스트 임베딩 etgt가 생성된다. 이후, 생성적 확산 모델 fθ의 매개변수를 고정하고, 대상 텍스트 임베딩 etgt를 노이즈 제거 확산 목적 함수로 최적화한다. 이는 대상 텍스트에 가장 가까운 입력 이미지와 일치하는 텍스트 임베딩을 생성한다
초기 대상 텍스트 임베딩과 가까운 위치에 있기 위해 상대적으로 적은 단계 동안 이 과정을 실행한다. 이 근접성은 임베딩 공간에서 의미 있는 선형 보간을 가능하게 하며, 먼 임베딩에 대해서는 선형적인 동작을 나타내지 않는다.
-
Model fine-tuning
최적화된 임베딩은 생성적 확산 프로세스를 통과할 때 항상 입력 이미지 x로 정확하게 이어지지 않기 때문에 모델 파라미터 θ를 최적화하여 입력 이미지 x와 일치하도록 모델을 조정하고, 동시에 최적화된 임베딩을 고정시킨다. 입력 이미지 x의 고주파 세부 정보를 보존하기 위해 보조 확산 모델도 fine-tuning한다.
-
Text embedding interpolation
생성적 확산 모델이 최적화된 임베딩에서 입력 이미지 x를 완벽하게 재생성하도록 훈련되었으므로, 목표 텍스트 임베딩 etgt 방향으로 진행하도록 편집을 한다. 이 단계는 etgt와 eopt 사이의 단순한 선형 보간으로 아래는 원하는 편집된 이미지를 나타내는 임베딩이다.
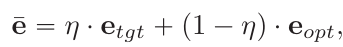
이후 fine-tuned 모델을 조건으로 사용하여 기본 생성적 확산 프로세스를 적용한다. 이 과정은 저해상도 편집된 이미지를 출력하며, 이후 보조 모델을 사용하여 목표 텍스트를 기반으로 이미지를 고해상도로 변환한다.
Implementation Details
이 프레임워크는 다양한 생성 모델과 결합할 수 있으며, Imagen와 Stable Diffusion과 같은 최신 텍스트 대 이미지 생성 모델을 사용하여 시연했다.
Imagen은 텍스트 조건에 따라 이미지를 생성하는 강력한 체계로, 여러 단계의 모델을 결합하여 구성된다. Imagen의 일부인 64x64 확산 모델을 사용하여 텍스트 임베딩을 최적화하고, 이를 조건으로 사용하여 입력 이미지를 세세하게 조정한다. 동시에, 원본 이미지와 대상 텍스트 임베딩을 사용하여 상세한 초해상도 모델을 세세하게 조정하여 원본 이미지의 고주파 세부 정보를 보존한다. 이러한 최적화 과정은 이미지 당 약 8분이 소요되며, 최종 결과물은 고해상도로 편집된 이미지이다.
그 다음 텍스트 임베딩을 보간한다. 세세한 조정 과정을 거친 덕분에, η가 0이면 원본 이미지가 생성되고, η가 증가함에 따라 이미지가 대상 텍스트와 일치하기 시작한다. 이후, Imagen와 함께 제공된 하이퍼파라미터를 사용하여 이미지를 생성한다. 이 모델은 사전 훈련된 오토인코더의 잠재 공간에서 작동하며, 단일 Tesla A100 GPU에서 7분이 소요된다.
Experiments
Qualitative Evaluation
다양한 도메인의 실제 이미지에 방법을 적용했습니다. 간단한 텍스트 프롬프트를 사용하여 스타일, 외관, 색상, 자세, 구도 등 다양한 편집 범주를 설명했다. 최적화 후, 각 편집을 8개의 무작위 시드로 생성하고 최상의 결과를 선택했다. Imagic은 다양한 이미지와 텍스트에 대해 다양한 편집을 적용할 수 있었다. 또한, Imagen과 Stable Diffusion을 사용하여 Imagic을 구현했습니다. Stable Diffusion을 사용하는 Imagic은 부드러운 의미론적 보간 특성을 나타냈다.

동일 이미지에 대한 다양한 대상 텍스트 프롬프트

서로 다른 임의 시드를 사용하여 동일한 편집에 대한 여러 옵션

최적화된 텍스트 임베딩과 대상 텍스트 임베딩 사이를 원활하게 보간할 수 있으므로 η 증가함에 따라 필요한 텍스트에 맞게 입력 이미지를 편집 가능
Comparisons

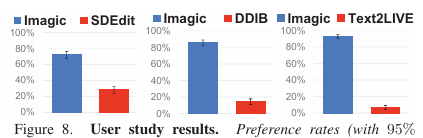
Imagic은 Text2LIVE, DDIB 및 SDEdit과 비교하여 단일 입력 실제 이미지를 기반으로 텍스트 프롬프트에 따라 편집하는 기술들과 비교된다.
다른 방법들과 비교하여 Imagic은 높은 fidelity를 유지하면서 원하는 편집을 잘 수행한다. 특히 개가 앉는 등의 복잡한 비유연한 편집을 수행할 때 이전 기술을 크게 능가한다.
TEdBench and User Study
텍스트 기반 이미지 편집 방법이 비교적 최근에 등장한 것으로, Imagic은 복잡한 비유연한 편집을 적용한 첫 번째 방법이다. 이에 따라 이러한 비유연한 편집을 평가하기 위한 표준 벤치마크가 없어, TEdBench (Textual Editing Benchmark)라는 새로운 데이터 세트를 도입했다. 이를 통해 Imagic의 성능을 평가하기 위해 Amazon Mechanical Turk를 활용하여 대규모의 사용자 인식 평가를 수행했고 결과적으로 Imagic은 다른 기준선에 비해 선호도가 높았다.
Ablation Study
Fine-tuning and optimization
64x64 사전 훈련된 확산 모델과 미세조정된 모델을 사용하여 각각의 η 값에 대한 이미지를 생성하여 결과를 비교한다. 미세조정을 통해 입력 이미지의 세부 정보를 보존하며, 이는 중간 값의 η에 대해 의미 있는 보간을 가능하게 한다.

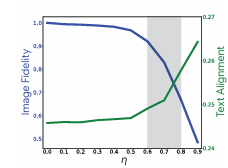
Interpolation intensity
η 값이 0.6~0.8인 경우에 가장 만족스러운 결과를 얻을 수 있다. 그러나 CLIP 점수와 LPIPS 점수는 각 입력 이미지-텍스트 쌍마다 다르게 측정되므로 실제로는 자동으로 η를 선택하거나 편집 방법의 성능을 평가하는 데 적합하지 않다.
Limitations
두 가지 실패 사례는 원하는 편집이 너무 미묘하게 적용되거나 외적 이미지 세부 사항에 영향을 미치는 경우이다.
미세한 조절로는 문제를 해결하기 어려울 때가 있고, 이러한 한계를 극복하기 위해 텍스트 임베딩이나 확산 모델을 다르게 최적화하는 방법을 고려할 수 있다. 사전 훈련된 모델의 제한과 편향을 상속하므로 원치 않는 artifact가 발생할 수 있고 최적화가 느리기 때문에 사용자 지향 애플리케이션에 직접 적용하는 데 어려움이 있을 수 있다.

Conclusions and Future Work
Imagic이라는 새로운 이미지 편집 방법을 제안한다. 이는 단일 이미지와 원하는 편집을 설명하는 간단한 텍스트 프롬프트를 받아들이고, 이미지의 최대한 많은 세부 정보를 보존하면서 이 편집을 적용한다.
이를 위해, 사전 훈련된 텍스트-이미지 확산 모델을 사용하여 입력 이미지를 나타내는 텍스트 임베딩을 찾는다. 그런 다음, 이미지를 더 잘 맞게 하기 위해 확산 모델을 세밀하게 조정하고, 마지막으로 이미지를 나타내는 임베딩과 대상 텍스트 임베딩 사이를 선형으로 보간하여 이들의 의미 있는 조합을 얻는다. 이를 통해 보간된 임베딩을 사용하여 편된 이미지를 제공할 수 있다.
이를 통해 단순한 스타일이나 색상 변경뿐만 아니라 객체의 자세나 기하학적 구성을 변경하는 등의 복잡한 편집도 가능하다. 미래 연구 방향으로는 입력 이미지와 정체성 보존에 대한 충실도를 향상시키는 것과, 매개 변수 η에 대한 민감도를 개선하는 것을 고려해야 한다. 사회적으로는 기존의 텍스트 기반 생성 모델의 사회적 편견에 노출될 수 있으며, 이를 완화하기 위해 식별 기술 개발이 필요할 수 있다.
