Abstract
이 논문은 XGBoost와 새로운 딥 러닝 모델들을 다양한 데이터셋에서 비교하여, 어떤 모델이 tabular data에 더 적합한지 탐구한다.
- XGBoost가 딥 러닝 모델들보다 대부분의 데이터셋에서 더 뛰어난 성능을 보임.
- 특히, 딥 러닝 모델들을 제안한 논문들에서 사용된 데이터셋에서도 XGBoost가 더 우수함.
- XGBoost는 딥 러닝 모델들보다 튜닝이 훨씬 적게 필요함.
- XGBoost와 딥 러닝 모델들을 조합한 앙상블 모델이 단독으로 사용하는 XGBoost보다 더 나은 성능을 보임.
Introduction
문제점:
- 탭형 데이터에 딥 뉴럴 네트워크를 적용할 때 지역성 부족, 데이터 희소성, 혼합 특징 타입, 데이터셋 구조에 대한 사전 지식 부족 등의 문제가 있음.
- 딥 뉴럴 네트워크는 "블랙 박스" 접근법으로 투명성이 부족함.
현재 상황:
- No Free Lunch에 따라 모든 문제에 항상 더 나은 모델은 없음.
- GBDT 알고리즘 (XGBoost)이 실제 탭형 데이터 문제에 권장되는 옵션임
연구:
- 최근 제안된 딥 모델들이 탭형 데이터 문제에 추천될 만한지 아래 두가지 질문을 중점으로 연구 진행 1) 모델들이 더 정확한가? 2) 훈련과 하이퍼파라미터 검색 시간이 얼마나 걸리는가?
Background
전통적인 머신러닝 방법
- GBDT: 탭형 데이터 애플리케이션에서 우수한 성능으로 지배적인 방법.
- 원리: GBDT는 약한 학습기를 통해 예측을 수행하며, 각 단계에서 잔차 학습
XGBoost 모델
- 확장 가능한 그래디언트 부스팅 트리 알고리즘.
- 잔차를 기반으로 새로운 모델을 생성하고, 손실을 최소화하기 위해 그래디언트 디센트 알고리즘 사용.
DeepNeural Models for Tabular Data
최근 여러 연구에서 탭형 데이터에 딥 러닝을 적용하여 성능을 개선하고자 새로운 뉴럴 아키텍처를 도입함.
- Differentiable trees: 결정 트리를 분화 가능하게 만들어 딥 뉴럴 네트워크로 통합. → NODE, Hazimeh
- Attention-based models: 어텐션 모듈을 사용하여 탭형 데이터의 특징 간 또는 데이터 포인트 간 상호작용 → TabNet, Arik and Pfister
- 정규화 방법: 각 뉴럴 가중치에 대한 정규화 강도를 학습
- 곱셈 상호작용 모델링: MLP 모델에 특징 곱셈을 통합
- 1D-CNN: 탭형 데이터에서 1D 컨볼루션을 사용한 모델
Model Ensemble
앙상블 학습은 여러 모델의 예측을 결합하여 성능을 향상시키는 방법.
유형:
- 랜덤화 기반: 랜덤 포레스트처럼 각 앙상블 멤버가 다른 초기 파라미터와 훈련 데이터를 가짐.
- 부스팅 기반: 순차적으로 앙상블 베이스 학습기를 맞추는 접근법.
방법:
- 배깅: 무작위로 선택된 훈련 데이터 하위 집합을 사용하여 결정 트리를 결
- 부스팅: 각 학습 반복 후 훈련 샘플의 가중치를 업데이트하고, 가중치 투표를 사용하여 분류 결과 결합.
- 스태킹: 신경망의 출력을 선형 회귀로 결합.
Comparing the Models
평가 요소: 성능, 효율성, 최적화 시간
모델 평가:
- 딥 모델, XGBoost, 앙상블 모델을 다양한 데이터셋에서 평가.
- 딥 모델과 전통적인 모델(XGBoost, SVM, CatBoost) 간의 조합 비교.
Experimental Setup
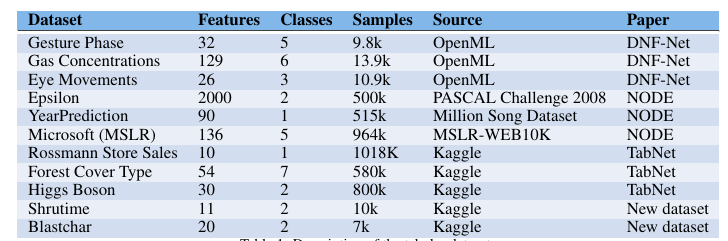
Data-sets Description
- 11개의 탭형 데이터셋 사용.
- 각 데이터셋은 원래 논문에서 사용된 방식대로 전처리 및 훈련.
- 데이터 표준화: 평균 0, 분산 1로 맞춤.
Implementation Details
The Optimization Process
-
Bayesian 최적화를 사용한 HyperOpt로 하이퍼파라미터 선택. 각 데이터셋에서 1000단계 최적화.
-
각 모델에 대해 6-9개의 주요 하이퍼파라미터 최적화.
Metrics and evaluation
-
이진 분류: 교차 엔트로피 손실 보고.
-
회귀: 평균 제곱근 오차(RMSE) 보고.
Statistical significance test
- 프리드먼 테스트 사용하여 성능 차이가 통계적으로 유의미한지 평가
Training
- 손실 최소화: 분류 데이터셋의 경우 교차 엔트로피 손실, 회귀 데이터셋의 경우 평균 제곱 오차 최소화.
- 원본 모델: 해당 모델이 발표된 논문에서 사용된 데이터셋.
- 딥 모델 구현: Adam 최적화 알고리즘 사용
Results
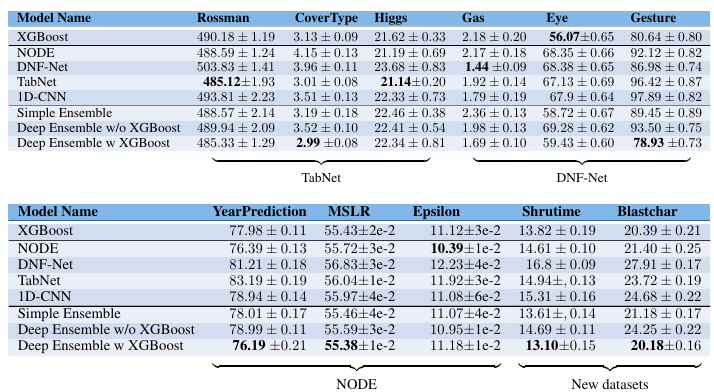
Do the deep models generalize well to other datasets?
-
대부분의 경우, 딥 모델은 원래 논문에 포함된 데이터셋보다 다른 데이터셋에서 성능이 저조함.
-
XGBoost는 대부분의 딥 모델보다 우수한 성능을 보임.
-
딥 모델은 일관되게 다른 모델보다 우수하지 않음.
-
딥 모델과 XGBoost를 결합한 앙상블이 대부분의 경우 더 나은 성능을 보임.
Do we need both XGBoost and deep net works?
-
전통적인 모델의 앙상블은 딥 모델과 XGBoost의 앙상블보다 성능이 떨어짐
-
딥 모델만으로는 좋은 결과를 얻지 못함.
Subset of models
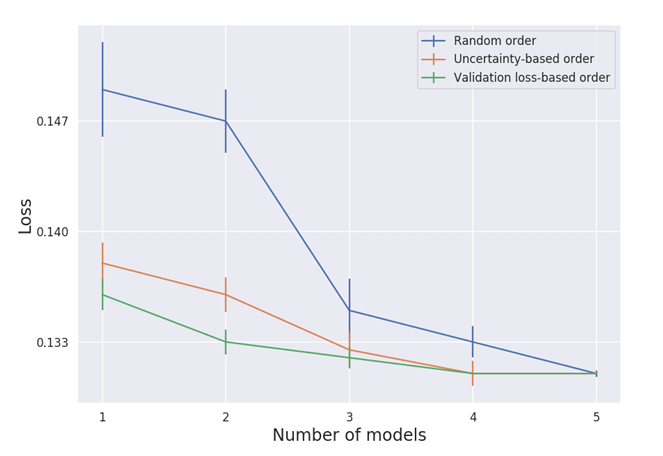
방법
- 검증 손실 기반으로 서브셋 선택.
- 예제별 불확실성 기반으로 서브셋 선택.
- 무작위 순서로 서브셋 선택.
결과: 검증 손실을 기반으로 한 모델 선택이 가장 우수. 무작위 선택이 가장 저조.
How difficult is the optimization?
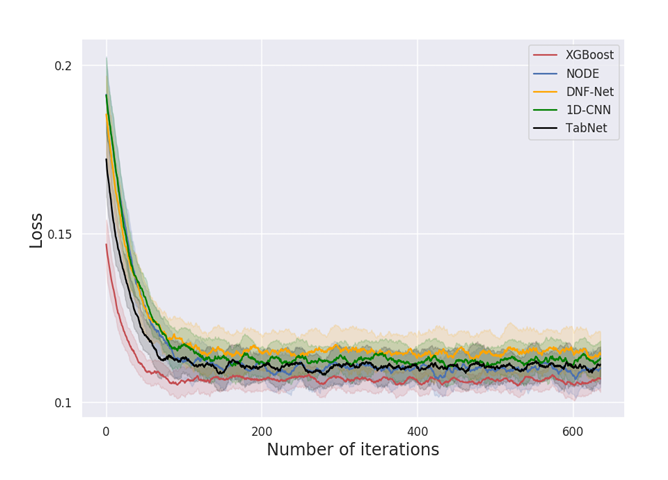
- 모델 훈련과 최적화에 걸리는 총 시간 비교.
- XGBoost가 딥 모델보다 훨씬 빠르게 최적화됨.
- 하이퍼파라미터 최적화 반복 횟수로 모델의 견고성 평가.
- 결과: XGBoost가 더 적은 반복 횟수로 좋은 성능에 도달, 딥 모델보다 더 빠르게 수렴
Discussion and Conclusions
이 연구에서는 딥 모델들이 탭형 데이터셋에서 XGBoost보다 성능이 떨어짐을 확인했다. 딥 모델들은 원래 논문에 포함되지 않은 데이터셋에서 특히 약한 성능을 보였으나 딥 모델과 XGBoost를 결합한 앙상블은 개별 모델보다 더 나은 성능을 보였다. 실용적으로는, 시간 제약이 있는 경우 XGBoost가 가장 좋은 결과를 내고 최적화하기 쉬우며, 최고의 성능을 위해서는 딥 모델과의 앙상블이 필요할 수 있다
