https://arxiv.org/abs/1905.08233
Abstract

이 논문은 타겟의 이미지에서 face landmark를 따와 소스의 이미지에 입히는 talking head model을 만드는 과정 (face reenactment)에 대해 설명하고 있다.
최근 많은 연구들에서 convolution network를 통해 talking head model을 생성했다. 컨벌루션 신경망을 통해 만들기 위해서는 하나의 이미지를 위해 대규모의 데이터셋을 훈련시켜야 한다.
본 논문에서는 이를 보완하기 위해 few-shot learning을 갖춘 시스템을 제안한다. 이 시스템은 대규모의 동영상에서 meta-learning을 수행 후 generator와 discriminator로 구성된 adversarial training을 통해 처음 보는 데이터에 대해서 개인별 특화된 방식으로 파라미터를 초기화하여 단 몇 장의 이미지를 통해 빠르게 학습할 수 있다.
Introduction
특정 개인의 talking head model을 생성하는 문제를 다루는데 이는 개인의 얼굴의 랜드마크를 기반으로 비디오 시퀀스에 합성할 수 있다.
도전 과제
- 사람 머리의 복잡성: 얼굴뿐만 아니라 입 안쪽, 머리카락, 옷까지 포함한 복잡한 포토메트릭, 기하학적, 운동학적 요소를 깔끔하게 모델링해야 한다.
- 인간 시각 시스템의 민감성: 인간의 시각 시스템은 작은 오류에도 민감하여, 비현실적인 모델링 결과는 불쾌한 골짜기 효과(Uncanny Valley)를 초래한다.
기존의 방법 및 한계
- 프레임 워핑 기법 (warping based system)은 학습하는 방식이 아니라 한 장의 이미지만으로도 talking model을 만들 수 있지만 한정된 움직임, 머리 회전, 시야 차단 문제를 해결하는 데 제한적이다.
- 대립적 학습(Adversarial Training)을 사용하는 깊은 컨벌루션 신경망(ConvNets)은 더 현실적인 결과를 제공하지만, 많은 양의 데이터와 긴 훈련 시간이 필요하다. (5분 정도 길이의 영상을 학습해야 하며, 여러 인물을 재연하기 위해 각각의 모델을 다 따로 학습시켜야 한다.)
제안된 방법
몇 장의 사진(few-shot learning) 또는 단일 사진(one-shot learning)으로 말하는 머리 모델을 생성할 수 있는 시스템을 제안한다.
이는 규모 동영상 데이터셋에서 메타 학습(meta-learning)을 통해 다양한 사람들의 얼굴 랜드마크를 실제처럼 보이는 개인화된 사진으로 변환하는 방법을 학습한다. 이후 소수의 사진으로도 새로운 사람의 얼굴 랜드마크를 학습하여 현실적이고 개인화된 이미지를 빠르게 생성할 수 있다.
실험 및 결과
alternative neural talking head model과 비교하여 성능을 평가하고 다양한 포즈를 처리할 수 있으며, 같은 사람의 비디오 시퀀스에서 추출한 랜드마크를 사용하여 비디오를 합성하거나 다른 사람의 랜드마크를 사용한 퍼펫팅(puppeteering)을 시연한다.
Related work
기존 연구
인간 얼굴의 외관을 통계적으로 모델링하는 연구들이 많다. 고전적인 기술과 최근의 딥러닝을 사용하여 훌륭한 결과를 얻었다.
얼굴 모델링과 말하는 머리 모델링은 관련이 있지만, 말하는 머리 모델링은 머리카락, 목, 입 안쪽, 어깨 및 상의 등 비얼굴 부분도 모델링해야 하므로 더 복잡하다.
얼굴 모델링 결과를 머리 비디오에 합성하는 방식은 머리 회전을 완전히 제어할 수 없으므로 완전한 말하는 머리 시스템을 만들 수 없다.
시스템 설계
제안된 시스템은 이미지 생성 중 Adversarial Training과 Conditional Discriminators를 사용한다.
메타 학습 단계에서는 대규모 조건부 생성 작업에 유용한 적응형 인스턴스 정규화(Adaptive Instance Normalization) 메커니즘을 사용하며 콘텐츠 스타일 분해(Content-Style Decomposition)를 사용한다.
model-agnostic meta-learner (MAML)을 사용하여 새로운 클래스의 이미지 분류기를 학습할 수 있도록 초기 상태를 얻는다.
기술 통합
기존 연구
여러 연구에서 대립적 학습과 메타 학습을 결합하여, 메타 학습 단계에서 보지 못한 클래스의 추가 예제를 생성하는 데 중점을 두었다.
제안된 방법
본 연구에서는 메타 학습 프레임워크에 대립적 미세 조정(Adversarial Fine-tuning)을 도입하여 이미지 생성 모델을 학습한다.
Methods
3.1 Architecture and Notation
메타 학습 단계
전제 조건
- 각각 다른 사람들의 말하고 있는 머리가 포함된 M개의 비디오 시퀀스가 필요함
- 학습 과정 및 테스트 시 모든 프레임에 대한 얼굴 랜드마크 위치가 제공된다고 가정
- 랜드마크는 특정 색상으로 연결된 선분을 사용하여 3채널 이미지로 변환된다.
네트워크 구성
메타 학습 단계에서 세 가지 네트워크가 훈련된다:
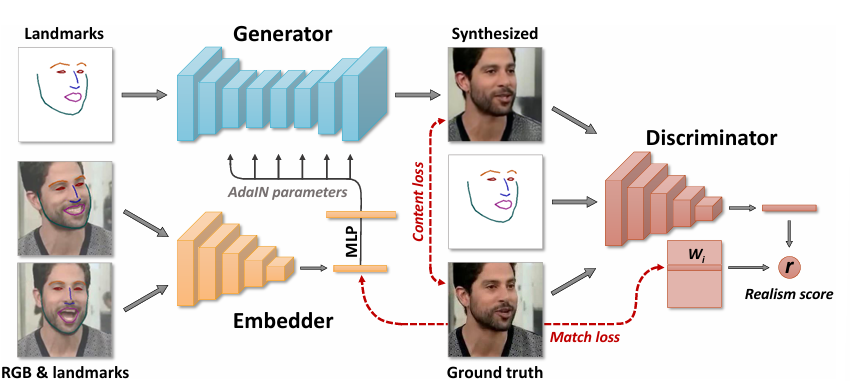
- Embedder (임베더)
- 입력: 비디오 프레임 xi(s)와 해당 랜드마크 이미지 yi(s)
- 출력: N차원 벡터 ei(s)
- 목적: 포즈와 표정에 불변한 비디오 특정 정보(예: 사람의 신원)를 포함하는 벡터를 학습
- Generator (생성기)
- 입력: 랜드마크 이미지 yi(t)와 예측된 비디오 임베딩 ei
- 출력: 합성된 비디오 프레임 x^i(t)
- 목적: 생성된 프레임과 실제 프레임 간의 유사성을 극대화
- 파라미터: 사람-일반 파라미터 ψ와 사람-특정 파라미터 ψi
- 𝜓𝑖는 임베딩 벡터 ei로부터 훈련 가능한 투영 행렬 P을 사용하여 예측
- Discriminator (판별기)
- 입력: 비디오 프레임 xi(t), 랜드마크 이미지 yi(t), 학습 시퀀스 인덱스 i
- 출력: 현실감 점수 r
- 목적: 입력 프레임 xi(t)가 실제 프레임인지, 그리고 입력 포즈 yi(t)와 일치하는지를 판단
- 파라미터: 학습 가능한 파라미터 θ, W, w0, b
- ConvNet 부분 V(xi(t),yi(t);θ)은 입력 프레임과 랜드마크 이미지를 N차원 벡터로 매핑
- 이 벡터와 W, w0, b를 사용하여 현실감 점수 r을 예측
3.2 Meta-learning stage
메타 학습 단계
훈련 방법
- 모든 네트워크의 파라미터는 대립적 방식으로 훈련됩니다. 이는 K-shot 학습(K=8)을 시뮬레이션하여 수행된다.
- 각 에피소드에서 무작위로 학습 비디오 시퀀스 i와 그 시퀀스에서 단일 프레임 t를 선택한다. 추가로 같은 시퀀스에서 K개의 프레임 s1,s2,...,sK를 무작위로 선택한다.
- 추가 프레임들로부터 예측된 임베딩을 평균하여 i번째 비디오 임베딩 ei를 계산한다:
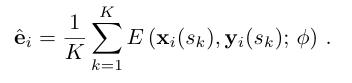
재구성 및 최적화
-
예측된 임베딩 ei를 바탕으로 t번째 프레임의 재구성 x^i(t)를 생성한다:
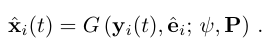
-
임베더와 생성기의 파라미터는 다음 목적 함수를 최소화하도록 최적화된다:
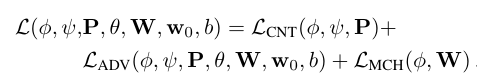
목적 함수 구성
- 컨텐츠 손실 𝐿𝐶𝑁𝑇
- 실제 이미지 xi(t)와 재구성된 이미지 x^i(t) 간의 거리 측정. VGG19와 VGGFace 네트워크의 특성을 사용하여 지각 유사성을 측정한다.
- 대립적 손실 𝐿𝐴𝐷𝑉
- 판별기에서 계산된 현실감 점수를 극대화하며, 판별기를 사용하여 계산된 특성 일치 항목도 포함한다. 이는 훈련의 안정성을 도움.
- 대립적 손실은 다음과 같이 계산된다:
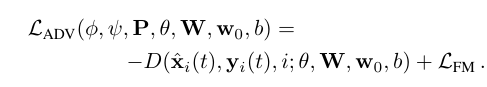
- 임베딩 매치 손실 𝐿𝑀𝐶𝐻
- 임베더에서 계산된 임베딩과 판별기의 임베딩 Wi 간의 유사성을 높여준다.
판별기 업데이트
- 판별기의 파라미터 θ,W,w0,b는 다음 힌지 손실을 최소화하여 업데이트:
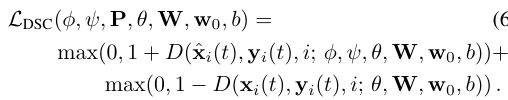
- 이는 가짜 예제 x^i(t)와 실제 예제 xi(t)의 현실감을 비교하여, 각각의 점수를 -1 이하와 +1 이상으로 조정한다.
훈련 절차
- 훈련은 임베더와 생성기의 파라미터를 최적화하는 단계와 판별기의 파라미터를 최적화하는 단계를 교대로 진행했다
3.3. Few-shot learning by fine-tuning
메타 학습이 수렴된 후
- 시스템은 메타 학습 단계에서 보지 못한 새로운 사람의 말하는 머리 시퀀스를 학습 가능하다.
- few shot 학습 방식으로 훈련이 진행되며, T개의 훈련 이미지와 해당 랜드마크 이미지가 주어진다.
- 새로운 말하는 머리 시퀀스의 임베딩 eNEW는 메타 학습 단계에서 학습된 임베더를 사용하여 다음과 같이 계산된다:
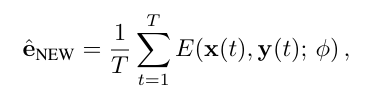
새로운 프레임 생성
- 생성기를 사용하여 새로운 랜드마크 이미지에 대응하는 프레임을 생성
Fine-tuning
- 파인 튜닝은 단일 비디오 시퀀스와 적은 수의 프레임을 사용하여 메타 학습의 간소화된 버전으로 진행됨
Fine-tuning 과정
- 생성기
- 입력: 랜드마크 이미지 y(t)와 임베딩 eNEW
- 출력: 합성된 프레임 x^(t)
- 사람-특정 생성기 파라미터 ψ′는 직접 최적화됩니다. 초기화는 ψ′=PeNEW로 설정
- 판별기
- 입력: 비디오 프레임 x(t)와 랜드마크 이미지 y(t)
- 출력: 현실감 점수 r
- ConvNet 부분 V(x(t),y(t);θ)와 바이어스 b는 메타 학습 단계의 결과로 초기화
- 새로운 개인에 대한 w는 w0와 eNEW의 합으로 초기화
최적화 목표
- 생성기의 파라미터 ψ와 ψ′는 다음 목적을 최소화하도록 최적화:
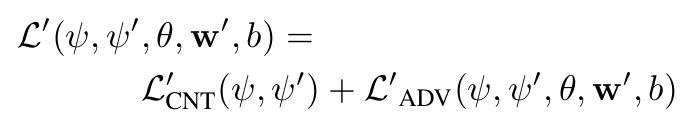
- 판별기의 파라미터 θ,w,b는 힌지 손실을 최소화하여 최적화:
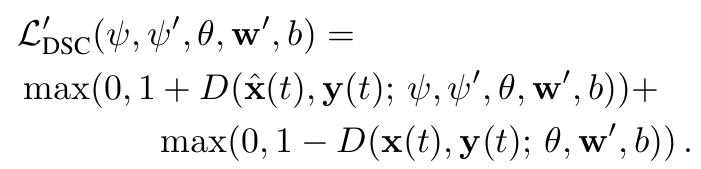
결과
- 대부분의 경우, 파인 튜닝된 생성기는 훈련 시퀀스에 더 잘 맞는 결과를 제공한다.
- 메타 학습 단계에서 모든 파라미터의 초기화가 중요하다. 실험을 통해 이러한 초기화가 현실적인 말하는 머리 모델을 생성하는 데 필수적임을 보여준다.
3.4 Implementation details
생성기 네트워크(G)
- Johnson et al.의 이미지-이미지 변환 아키텍처를 기반으로 하되, 다운샘플링과 업샘플링 레이어를 residual blocks으로 대체했다. 배치 정규화(batch normalization) 대신 인스턴스 정규화(instance normalization)를 사용한다.
- 사람-특정 파라미터 ψi는 적응형 인스턴스 정규화(adaptive instance normalization) 기법을 따라 인스턴스 정규화 레이어의 아핀 계수로 사용된다.
- 랜드마크 이미지를 인코딩하는 다운샘플링 블록에는 일반 인스턴스 정규화 레이어를 사용한다.
임베더 네트워크(E) 및 판별기 네트워크(V)
- 임베더와 판별기 네트워크는 유사한 네트워크를 사용하며, 잔차 다운샘플링 블록으로 구성된다. 판별기는 마지막에 4x4 공간 해상도에서 작동하는 추가 residual blocks 이 있다.
- 두 네트워크 모두에서 벡터화된 출력을 얻기 위해 공간 차원에 대해 global sum pooling과 ReLU를 사용한다.
정규화 기법
- 모든 컨볼루션 및 완전 연결 층에 대해 스펙트럼 정규화(spectral normalization)를 사용한다.
- self-attention blocks을 사용하며, 이는 네트워크의 다운샘플링 부분에서는 32x32 해상도에서, 생성기의 업샘플링 부분에서는 64x64 해상도에서 삽입된다.
손실 함수
- 𝐿𝐶𝑁𝑇: 실제 및 가짜 이미지에 대해 VGG19와 VGGFace 레이어의 활성화 사이의 L1 손실을 평가한다. 이 손실은 각각 1.5x10^-1와 2.5x10^-2의 가중치로 합산된다.
- 𝐿𝐹𝑀: 판별기 네트워크의 각 잔차 블록 후의 활성화를 사용하며, 가중치는 10으로 설정된다.
- 𝐿𝑀𝐶𝐻: 가중치는 10으로 설정된다.
네트워크 구성 및 최적화
- 컨볼루션 레이어의 최소 채널 수는 64, 최대 채널 수는 512로 설정되며,임베딩 벡터의 크기도 512이다.
- 임베더는 1,500만 개의 파라미터, 생성기는 3,800만 개의 파라미터, 판별기의 컨볼루션 부분은 2,000만 개의 파라미터를 가진다.
- Adam 최적화기를 사용하며, 임베더와 생성기의 학습률은 5x10^-5, 판별기의 학습률은 2x10^-4로 설정된다. 업데이트는 생성기 한 번에 대해 판별기를 두 번 수행.
Experiments
데이터셋
- 두 개의 말하는 머리 비디오 데이터셋을 사용하여 정량적/정성적 평가를 수행:
- VoxCeleb1: 256p 비디오, 1 fps
- VoxCeleb2: 224p 비디오, 25 fps (VoxCeleb1보다 약 10배 많은 비디오를 포함)
평가 지표
- 정량적 평가:
- few shot 학습 세트의 크기 T로 모델을 파인 튜닝하고, 메타 학습 또는 사전 학습 단계에서 보지 못한 사람에 대해 평가를 수행한다.
- 평가 시, 동일한 시퀀스의 홀드아웃 부분(테스트에 사용되지 않은 부분)에서 성능을 측정
- VoxCeleb 테스트 세트에서 50개의 비디오와 각 비디오에서 32개의 홀드아웃 프레임을 균일하게 샘플링하여 평가한다.
- 평가 메트릭스:
- Frechet-inception distance (FID): 지각적 현실감을 측정하며, 낮을수록 좋음
- Structured Similarity (SSIM): 원본 이미지와의 저수준 유사성을 측정하며, 높을수록 좋음
- Cosine Similarity (CSIM): 얼굴 인식 임베딩 벡터 간의 코사인 유사성을 사용하여 identity 불일치를 측정하며, 높을수록 좋습니다.
- USER: 사용자 연구를 통해 측정한 사용자 정확도(성공률)로, 낮을수록 좋습음
- 사용자 연구:
- 세 개의 비디오 시퀀스에서 동일한 사람의 이미지를 보여주고, 그 중 두 개는 실제 이미지이고 하나는 비교 방법 중 하나에 의해 생성된 가짜 이미지일 때, 사용자는 가짜 이미지를 찾아내야 하는 상황
- 사용자는 두 개의 실제 이미지로부터 identity를 추론하고, 생성된 이미지가 완벽하게 현실적이어도 identity 불일치를 발견할 수 있다.
- 사용자 정확도(성공률)를 평가 메트릭으로 사용한다. 이때 사용자가 임의로 추측해야 할 때의 정확도는 1/3이다.
Methods
- 비교 모델:
- VoxCeleb1 데이터셋에서 두 시스템(X2Face, Pix2pixHD)과 제안된 모델을 비교
- X2Face: 저자들이 제공한 사전 훈련된 모델과 가중치를 사용
- Pix2pixHD: 전체 데이터셋에서 제안된 시스템과 동일한 반복 횟수로 사전 훈련함
- X2Face는 워핑 기반 방법의 강력한 기준점으로, Pix2pixHD는 직접 합성 방법의 기준점으로 선택했다
- few shot학습에서 프레임 수 T를 변화시키며 모델을 평가한다. X2Face는 훈련 프레임을 통해 초기화되고, Pix2pixHD와 제안된 모델은 40 에폭 동안 추가로 파인튜닝한다
Comparison results
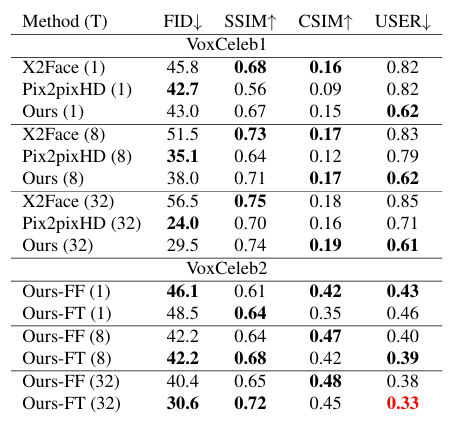
다양한 방법(X2Face, Pix2pixHD, Ours)의 성능을 비교하며, 각 방법은 few shot 학습 설정 (1, 8, 32 프레임)에서 평가되었고, VoxCeleb1 데이터셋과 VoxCeleb2 데이터셋에서 각각의 메트릭 값을 보여주고 있다.
특히, 제안된 방법은 VoxCeleb1 데이터셋에서는 FID와 USER 메트릭에서 좋은 성능을 보이며, VoxCeleb2 데이터셋에서는 USER 메트릭에서 특히 좋은 성능을 보인다. 이는 제안된 방법이 사용자 연구에서 더 높은 현실감과 identity 보존을 제공함을 의미한다

VoxCeleb1 dataset에서의 비교 중 논문의 방법이 가장 성능이 좋다.
- 평가 시나리오:
- 1, 8, 32 프레임을 사용하여 모델을 평가했다.
- 테스트 세트는 50개의 테스트 비디오 시퀀스마다 32개의 홀드아웃 프레임으로 구성된다.
- 사용자 연구를 위해, 동일한 사람의 다른 비디오 시퀀스에서 두 프레임을 무작위로 샘플링하여 가짜 프레임과 함께 triplets로 사용했다.
- 결과 분석:
- X2Face와 Pix2pixHD가 두 가지 유사성 지표(SSIM, FID)에서 제안된 방법보다 일관되게 더 높은 성능을 보인다.
- SSIM이 높은 이유는 X2Face가 최적화 동안 L2 손실을 사용하기 때문이다.
- Pix2pixHD는 FID를 최적화하지만, identity 보존 손실이 없어 identity 불일치가 크다
- 이 메트릭스들은 인간의 지각과 잘 맞지 않으며, 두 방법 모두 uncanny valley가 나타난다
- 사용자 연구는 제안된 방법이 더 높은 현실감과 개인화를 제공함을 보여준다
Large-scale results
- VoxCeleb2 데이터셋:

두 가지 변형 모델(FF, FT)을 훈련
-
FF (Feed-Forward): 임베딩 매치 손실 LMCH 없이 150 에폭 동안 훈련, 미세 조정 없이 사용.
-
FT (Fine-Tuning): LMCH를 사용하여 75 에폭 동안 훈련, 미세 조정 가능.
-
두 모델 모두 VoxCeleb1에서 훈련된 모델에 비해 훨씬 높은 성능을 달성한다.
-
FT 모델은 T=32 설정에서 사용자 연구 정확도의 하한값인 0.33에 도달하여 완벽한 점수를 달성했다
Puppeteering results
- 퍼펫팅:

- one shot 설정으로 훈련된 모델을 사용하여 VoxCeleb2 데이터셋의 테스트 비디오의 포즈를 평가했다.
- 원본 이미지와 생성된 이미지 간의 CSIM 메트릭을 사용하여 유사한 랜드마크 기하학을 가진 사람을 찾아 퍼펫팅에 사용한다.
Conclusion
프레임워크 개요
- 제안된 프레임워크는 대립적 생성 모델을 메타 학습하여 깊은 생성기 네트워크 형태의 매우 현실적인 가상 말하는 머리를 훈련한다.
- 새로운 모델을 만들기 위해서는 단 몇 장의 사진(최소 한 장)만 필요하다.
- 32장의 이미지로 훈련된 모델은 사용자 연구에서 완벽한 현실감과 개인화 점수를 달성했다
한계점
- 표정 표현: 현재 랜드마크 세트는 시선을 표현하지 못하는 등 표정 표현에 한계가 있다.
- 랜드마크 적응 부족: 다른 사람의 랜드마크를 사용하면 불일치가 발생한다. 따라서 이러한 불일치를 피하려면 랜드마크 적응이 필요하다.
