Background
제로샷 학습
- 별도의 추가 학습이나 파인튜닝 없이 모델이 새로운 데이터나 작업에서 적절히 작동할 수 있는 방법
- 학습 데이터에 포함되지 않은 개념이나 작업에서도 모델이 일반화함
→ 예: DALL-E가 "크리스마스 스웨터를 입은 고슴도치"를 텍스트로 입력받고 이미지 생성하는 능력
Transformer 모델
- 어텐션 매커니즘을 통해 입력 데이터의 모든 부분을 동시에 처리하며 입력의 중요도를 계산하여 학습
- 멀티 헤드 어텐션을 통해 여러 관점에서 데이터를 분석하여 학습 성능 높임
→ DALL-E에서는 텍스트와 이미지를 동시에 처리해서 두 데이터 간의 관계 학습
Autoregressive (자동 회귀 방식) Transformer
- Autoregressive: 모델이 데이터를 순차적으로 생성하는 방식
- 이전에 생성된 데이터를 기반으로 다음 데이터를 예측하며, 출력이 누적되어 최종 결과 생성
→ DALL-E는 텍스트와 이미지를 하나의 시퀀스로 결합하여 순차적으로 생성
(ex) “A red apple on a table”: 모델이 텍스트 처리 → 이미지의 첫 번째 토큰, 두 번째 토큰을 순차적으로 생성해서 최종 이미지 완성
MS-COCO 데이터 셋
- 이미지와 이에 대한 설명(텍스트)을 포함한 대규모 데이터셋
- 80개 이상의 객체 클래스와 다양한 배경/상황(context)을 포함하여, 텍스트-이미지 학습 및 평가에 자주 사용됨
dVAE (Discrete Variational Autoencoder)
- VAE의 변형으로 연속적인 잠재 공간 대신 이산적인 잠재 공간 사용
- 텍스트나 이미지같은 데이터를 토큰 (이산 표현)으로 변환하기 위해 사용됨
- Encoder: 입력 데이터를 받아 잠재벡터 z로 변환
- VAE: z가 연속적 분포, dVAE: z가 코드북 내의 이산적인 코드로 매핑됨
- 코드북: 고정된 크기와 개수를 가짐, 학습 과정에서 모델이 가장 적합한 코드 선택
- Decoder: 이산적인 코드로부터 원래 데이터를 복원
- VAE와 유사한 방식으로 작동하지만, 입력으로 연속적 벡터가 아닌 코드북의 코드가 사용됨
- 손실함수
- 복원 손실 (Reconstruction Loss): 입력 데이터를 복원하는 과정에서의 차이를 최소화
- KL 발산: 잠재 분포 q(z|x) 와 사전 분포 p(z) 간의 차이를 최소화
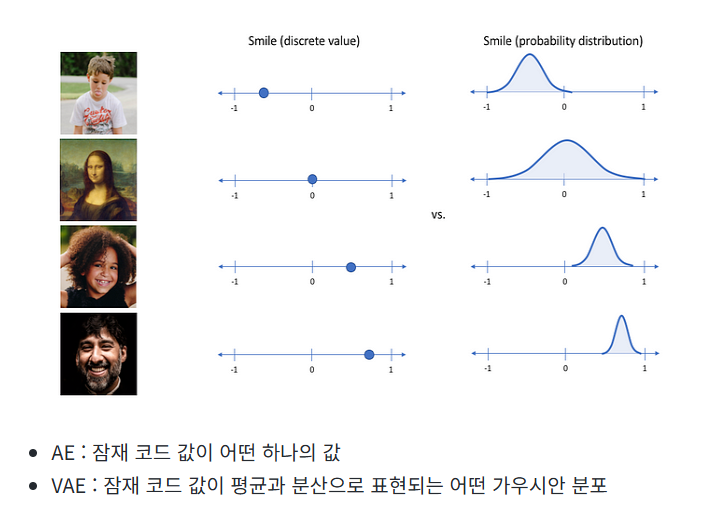
VAE (Variational Autoencoder)
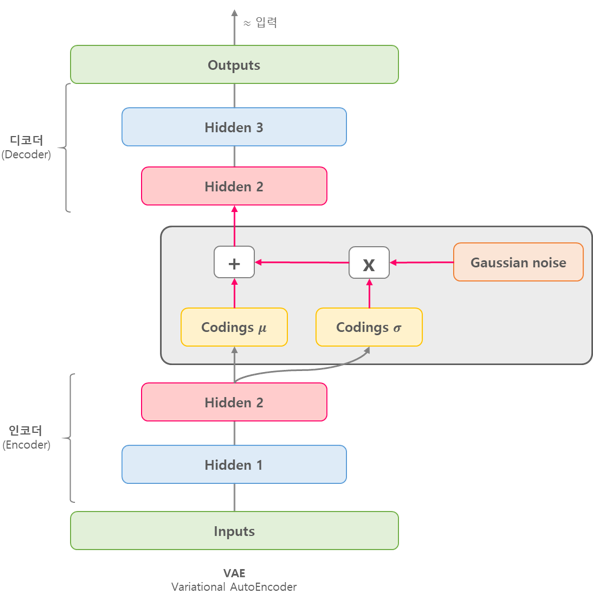
- Input image X를 잘 설명하는 feature를 추출하여 Latent vector z에 담아 X와 유사하지만 완전히 새로운 데이터 생성
- latent z는 각 feature의 평균과 분산 값을 나타냄
- 추출된 잠재 코드의 값을 하나의 숫자로 나타내는 것이 아니라, 가우시안 확률 분포에 기반한 확률값 으로 나타냄
BPE-인코딩
- BPE(Byte Pair Encoding): 텍스트 데이터를 압축 및 표현하기 위해 사용
- 텍스트를 가장 자주 등장하는 문자 쌍부터 순차적으로 병합하여 토큰화
KL 다이버전스 (Kullback-Leibler Divergence)
- 두 확률 분포 간 차이를 측정하는 방법
- DKL(P||Q): 분포 P와 Q 간의 차이를 나타냄
- 모델 학습에서 실제 데이터 분포와 모델이 예측한 분포 간의 차이를 최소화하는 데 사용됨
Per-Resblock Gradient Scaling 기법
- Resblock(Residual Block)마다 기울기를 조정하여 학습 안정성을 높이는 기법
- 혼합 정밀도 학습(Mixed-Precision Training)에서 언더플로우(Underflow) 문제를 방지
PowerSGD
- 분산 학습에서 사용되는 효율적인 통신 비용 절감 기법
- 매우 큰 그래디언트 전송해야하는 경우에 사용됨
- 매개변수 업데이트할 때 그래디언트 행렬을 압축
- 행렬 분해 기법 (저랭크 근사)를 사용해 그래디언트를 더 작은 크기의 표현으로 변환
- 저랭크 근사: 그래디언트 행렬을 두 개의 작은 행렬 P와 Q로 근사
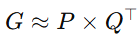
ELB(Evidence Lower Bound) 최적화 방식
- 확률 모델의 학습 과정에서 사용되는 방법
- Variational Autoencoder(VAE)나 dVAE와 같은 모델에서 데이터를 효율적으로 표현하기 위해 사용됨
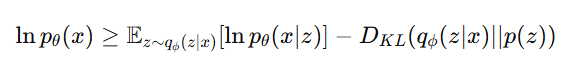
- x: 입력 데이터 (예: 이미지)
- z: 잠재 변수(latent variable) 또는 이미지 토큰
- qϕ(z∣x): 인코더(encoder)가 계산한 z의 분포 (실제 데이터에서 계산된 분포)
- pθ(x∣z): 디코더(decoder)가 계산한 x의 분포 (모델이 학습한 분포)
- p(z): z에 대한 사전 분포(prior distribution, 보통 정규분포)
- D_KL: KL 다이버전스(로, 두 분포 간의 차이를 측정
Abstract
- DALL-E는 텍스트를 입력을 받아 이미지를 생성하는 모델
- 기존의 텍스트-이미지 생성 방식과 달리 Transformer를 활용해 텍스트와 이미지를 결합하여 학습함
- 사전 훈련된 라벨 없이 제로샷 방식으로도 높은 성능을 보임
Introduction
- 텍스트-이미지 변환 기술은 이미지 캡션을 조건으로 생성 모델을 학습하거나 GAN을 통해 이미지 품질을 개선하는 등 발전해왔음 → 이런 방법들은 학습 데이터에 의존적, 새로운 범주의 일반화에서 한계를 보임
- Autoregressive Transformer를 통해 기존의 제약을 극복하고자 함
- 2억 5천만 개의 텍스트-이미지 쌍으로 학습, 120억개의 파라미터를 통해 텍스트로 고품질 이미지 생성 가능
- 학습 과정에서 라벨을 사용하지 않고 MS-COCO와 같은 데이터셋에서 제로샷 방식으로 높은 성능을 보임
- 모델은 단순한 텍스트 기반 이미지 생성 뿐만 아니라 이미지-이미지 번역도 가능 → 단일 대규모 생성 모델 (DALL-E)로 여러 개의 시각적 작업 수행 가능
Method
2단계 학습 과정
-
1단계: 이미지 데이터 압축 (dVAE 사용)
- dVAE를 사용해서 256x256 이미지를 32x32 이미지 토큰 그리드로 압축
- 각 토큰은 8192개의 고유 값 가짐
- 이 과정을 통해 트랜스포머의 맥락 크기 192배 감소시키며 시각적 품질 저하 최소화
-
2단계: 트랜스포머를 사용한 텍스트와 이미지 통합 학습
- 텍스트와 이미지 토큰을 하나로 결합
- 텍스트: 최대 256개의 BPE-인코딩된 토큰 사용
- 이미지: 32x32 토큰 (1024개) 사용
- 텍스트와 이미지의 결합 분포를 자동회귀방식으로 학습
- 텍스트와 이미지 토큰을 하나로 결합
-
수학적 최적화 (ELB를 최대화하는 방법으로 모델 학습)
-
조인트 분포
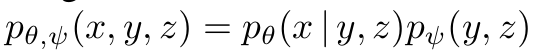
- 이미지 (x)와 캡션 (y), dVAE로 인코딩된 이미지 토큰 (z)의 조인트 분포 학습
- pθ(x|y,z): 텍스트와 이미지 토큰을 조건으로 이미지 x 생성하는 분포
- pψ(y,z): 텍스트와 이미지 토큰의 결합 분포
-
ELB (Evidence Lower Bound) 최대화
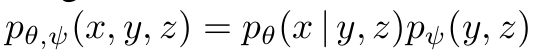
- lnpθ (x|y,z): 텍스트와 이미지 토큰을 조건으로 이미지 생성하는 확률 로그 값 → 모델이 실제 데이터를 얼마나 잘 재현하는지 나타냄
- D_KL(qϕ (y,z∣x), pψ (y,z)): dVAE 인코더에서 생성된 분포 (qϕ)와 모델 분포 (pψ) 간의 차이 측정 → 이 값을 최소화하여 dVAE로 생성된 이미지 토큰과 트랜스포머 모델의 학습 분포 일치하도록 만듦
-
2.1 Stage One: Learning the Visual Codebook (시각적 코드북 학습)
- 고해상도 이미지를 효율적으로 처리하기 위해 dVAE를 사용해 이미지를 32x32 토큰으로 압축 → 텍스트와 이미지를 결합 학습하기 위해 사전 처리 단계
- ELB를 최적화하여 이미지 압축 및 복원
- Gumbel-Softmax Relaxation을 사용해 학습 안정성 향상
- KL 다이버전스 가중치를 증가시켜 압축 품질과 코드북 사용 효율성을 높임
2.2 Stage Two: Learning the Prior (사전 분포 학습)
- 텍스트와 이미지 토큰의 결합 분포를 학습해 자연어 텍스트로부터 이미지 생성하는 능력 강화
- 텍스트: 최대 256개의 BPE 토큰으로 변환 (어휘 크기: 16,384).
- 이미지: 32x32(총 1024개) 이미지 토큰으로 변환 (어휘 크기: 8192).
- 텍스트와 이미지 토큰을 하나의 데이터 스트림으로 결합한 후 120억 개 파라미터를 가진 트랜스포머로 학습.
- 트랜스포머는 64개의 self-attention 레이어를 통해 텍스트와 이미지 간 관계를 학습
2.3 Data Collection (데이터 수집)
- 대규모 모델 학습을 위해 적합한 텍스트-이미지 데이터셋 구축
- 약 2억 5천만 개의 텍스트-이미지 쌍을 인터넷에서 수집
2.4 Mixed-Precision Training (혼합 정밀도 학습)
- 메모리 사용량을 줄이고 학습 속도를 높이기 위해 16비트 정밀도를 활용
- Per-Resblock Gradient Scaling 기법을 사용해 16비트 연산에서 발생할 수 있는 언더플로우(값이 너무 작아 0으로 처리되는 문제)를 방지
- Resblock에서 기울기를 스케일링하여 기울기 크기 유지
- 활성화 및 기울기를 32비트로 저장하여 안정성을 높임
- Adam 옵티마이저와 정교한 체크포인트 전략으로 120억 개 파라미터 모델의 안정적 학습 달성
- Per-Resblock Gradient Scaling 기법 설명하는 다이어그램
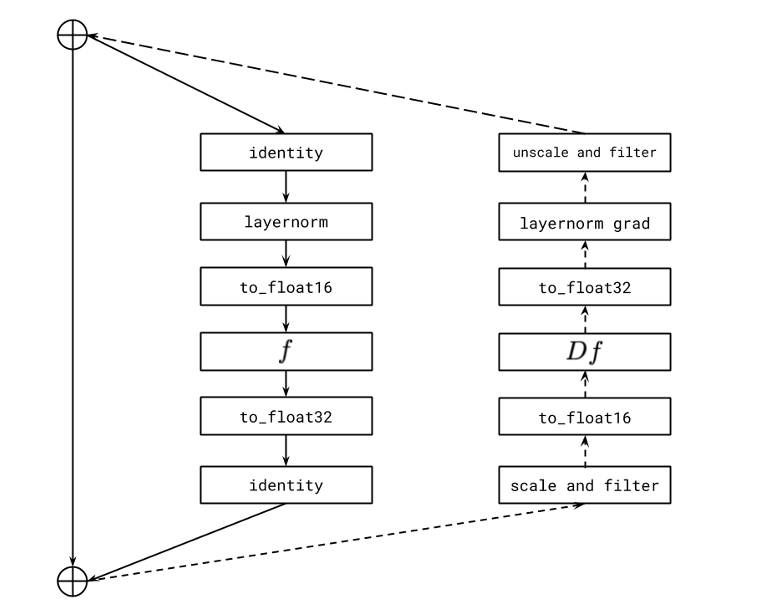
- 실선: Resblock의 Forward Propagation
- Identity: 입력을 그대로 전달
- LayerNorm: 데이터의 평균과 분산 정규화
- to_float16 / to_float32: 연산 중 일부를 16비트 정밀도로 처리 & 특정 단계에서는 안정성을 위해 다시 32비트로 변환 → 오버플로우나 언더플로우 방지를 위해 32비트 정밀도 사용
- 점선: Backward Propagation
- 기울기 계산 및 업데이트하는 과정
- scale and filter: 각 resblock의 출력 기울기 스케일링하여 안정성 보장 & 비정상적인 값 0으로 설정해서 학습 오류 방지
- unscale and filter: 다음 resblock으로 전달하기 전에 스케일링된 기울기 복원 → 언더플로우, 오버플로우 방지를 위해 스케일링 → 스케일링된 상태로 남아있으면 잘못된 방향으로 모델 업데이트되므로 복원해야 함
- 실선: Resblock의 Forward Propagation
2.5 Distributed Optimization (분산 최적화)
- 대규모 모델 학습의 계산 부담을 줄이기 위해 GPU 간 분산 처리를 최적화
- 각 GPU가 모델의 일부 파라미터를 저장하고, 필요할 때만 데이터를 공유
- PowerSGD를 사용해 기울기 전송 비용을 줄이고 통신 효율성을 향상 → 최대 85%의 데이터 압축률 달성
- GPU간의 통신 패턴
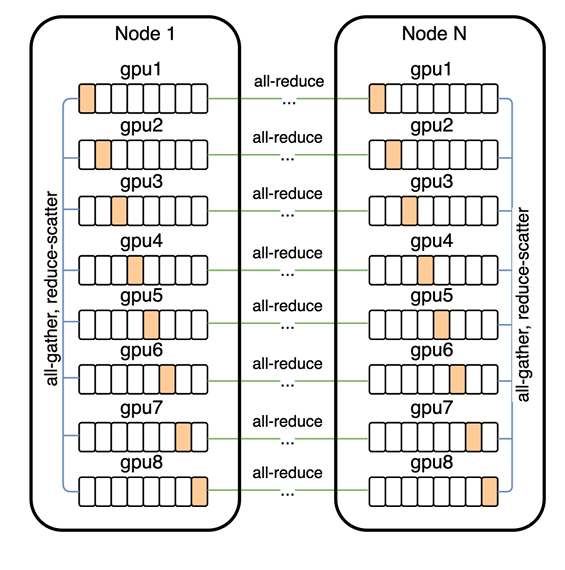
- 파라미터 분할: 하나의 GPU에 모두 저장되지 않고, 8개의 GPU로 나누어 각 GPU에 일부만 저장 → 메모리 사용량 줄임
- Prefetch: 현재 Resblock (Residual Block)의 활성화 값을 계산하는 동안 다음 Resblock에 필요한 파라미터를 all-gather를 통해 미리 가져옴
- Backward Propagation: 역전파로 이전 Resblock의 활성화 및 기울기 계산을 수행하는 동안, 필요한 파라미터를 다시 All-Gather 연산을 통해 가져옴
- All-Gather: 모든 GPU가 필요한 파라미터 조각을 다른 GPU로부터 모아 전체 파라미터를 복원
- Reduce-Scatter 연산을 통해 기울기 값은 각 GPU에 나눠 저장됨
- 모든 GPU가 계산한 기울기를 평균하여 해당 GPU에 해당하는 조각만 남기고 나머지는 제거
2.6 Sample Generation (샘플 생성)
- 텍스트를 기반으로 고품질 이미지를 생성하는 모델의 능력 평가
- MS-COCO와 같은 데이터셋에서 제로샷(Zero-Shot) 성능 평가
전체 흐름
- dVAE를 사용해 이미지 압축하고 효율적으로 토큰화
- 텍스트와 이미지 토큰의 결합 분포를 트랜스포머로 학습
- 대규모 텍스트-이미지 데이터셋을 구축해 모델의 학습 범위 확장
- 혼합 정밀도를 학습하여 계산 효율성을 극대화하며 안정성 유지
- 분산 최적화하여 대규모 GPU 클러스터를 통해 학습 속도 높이고 통신 비용을 줄임
- 샘플 생성하여 학습된 모델의 실제 성능을 테스트하고 평가함
최종 정리
1. 연구 목표
- 텍스트와 이미지를 통합적으로 학습하여 텍스트로부터 이미지를 생성할 수 있는 모델 개발.
- 제로샷(Zero-Shot) 학습:
- 별도의 추가 학습 없이 새로운 작업에서도 우수한 성능을 발휘하도록 설계.
- 고품질 이미지 생성:
- 고해상도 이미지(256x256)를 생성하며 텍스트에서 설명한 내용이 정확히 반영된 이미지를 출력.
2. 주요 기여
- 대규모 텍스트-이미지 데이터 활용:
- 약 2억 5천만 개의 텍스트-이미지 쌍을 수집하여 모델을 학습.
- Conceptual Captions, YFCC100M 등 다양한 데이터셋을 활용.
- 트랜스포머 기반 모델:
- 120억 개의 파라미터를 가진 오토리그레시브 트랜스포머를 사용.
- 텍스트와 이미지를 하나의 데이터 스트림으로 결합하여 학습.
- dVAE를 통한 이미지 압축:
- 고해상도 이미지를 32x32의 토큰으로 압축하여 학습 효율을 극대화.
- 제로샷 성능:
- 별도의 라벨 없이 MS-COCO 등 다양한 데이터셋에서 탁월한 성능 발휘.
3. 모델 구조 및 학습 방법
1단계: 이미지 압축 (dVAE 사용)
- 목적: 고해상도 이미지를 32x32 토큰으로 압축하여 모델 학습을 효율화.
- 방법:
- dVAE를 사용해 이미지를 토큰으로 변환.
- ELB(Evidence Lower Bound)를 최대화하여 압축 과정에서 시각적 품질 유지.
- 8192개의 고유 값을 가진 토큰으로 압축.
2단계: 텍스트와 이미지 결합 학습
- 텍스트:
- 입력 텍스트를 256개의 BPE 토큰으로 변환(어휘 크기 16,384).
- 이미지:
- dVAE를 통해 생성된 32x32(총 1024개)의 이미지 토큰 사용(어휘 크기 8192).
- 결합 학습:
- 텍스트와 이미지를 하나의 데이터 스트림으로 결합해 학습.
- 트랜스포머 모델(120억 개 파라미터)을 사용하여 텍스트-이미지 간 관계를 학습.
4. 최적화 기법
- 혼합 정밀도 학습(Mixed-Precision Training):
- 16비트 연산을 활용하여 메모리 사용량을 줄이고 학습 속도 향상.
- Per-Resblock Gradient Scaling을 사용해 언더플로우 문제를 해결.
- 분산 학습(Distributed Training):
- GPU 간 All-Gather 및 Reduce-Scatter 통신 패턴을 사용해 메모리와 계산 효율을 극대화.
- 각 GPU에 모델의 파라미터를 분할 저장하고 필요한 데이터만 통신.
5. 성능 및 결과
- 제로샷 이미지 생성:
- MS-COCO에서 추가 학습 없이도 기존 모델(GAN 기반) 대비 90% 이상 선호되는 결과.
- 텍스트에서 설명한 내용을 정확히 반영한 이미지 생성.
- 텍스트-이미지 매칭:
- 텍스트 설명과 이미지가 얼마나 잘 맞는지 평가했을 때, 기존 모델 대비 뛰어난 성능.
- 다양한 응용 사례:
- 상상력을 요구하는 새로운 개념(예: "크리스마스 스웨터를 입은 아기 고슴도치")을 텍스트로 표현해도 정확한 이미지를 생성.
