
K-Nearest Neighbor
대표적인 지도학습 알고리즘 중 하나
KNN (K-최근접 이웃)
- K-최근접 이웃은 지정한 K의 수만큼 근접한 데이터의 정보를 기반으로, 새로운 데이터의 종속 변수(y값, 타깃)을 예측하는 알고리즘이다.
문제 설정
현재 동그라미, 세모, 네모 데이터가 존재한다.
새로운 데이터가 추가됐을 때, 동그라미, 네모, 세모 중 어느 클래스에 속하는지 예측(분류)해보자.
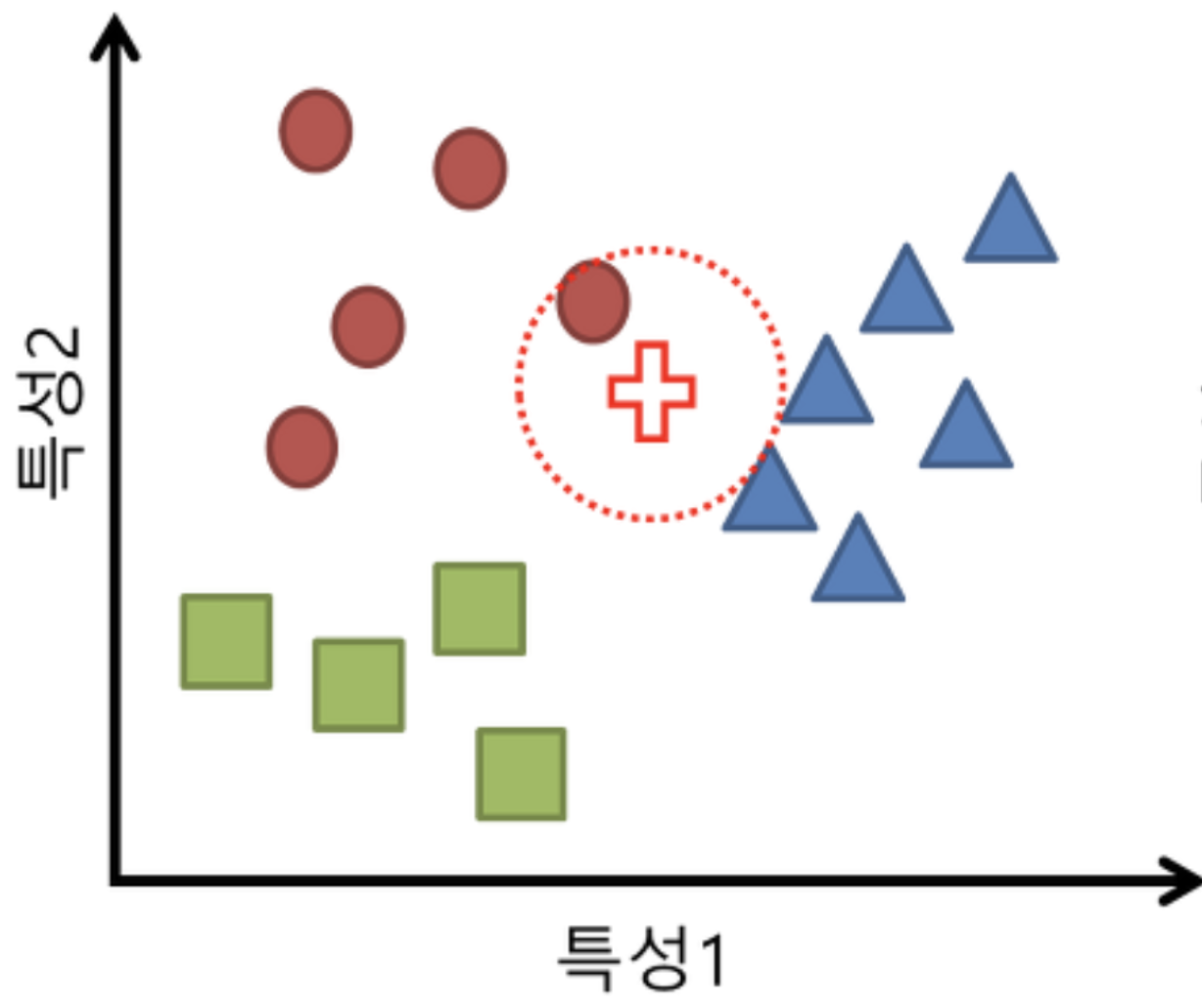
- 십자가 데이터가 테스트 데이터로 들어왔다.
십자가는 동그라미, 세모, 네모 중 어느 클래스에 속할까?
파라미터 K (KNN에서 K)
K-NN은 지정한 K의 수만큼 근접한 데이터의 정보를 기반으로, 새로운 데이터의 종속 변수(y값, 타깃)을 예측하는 알고리즘이라고 했다.
- 즉 하이퍼 파라미터인 K를 개발자가 지정해주어야한다.
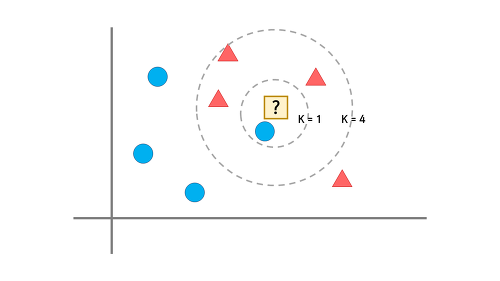
K가 무엇일까?
K의 의미는 새로운 샘플 데이터로 부터 가장 가까운 데이터들 몇개를 이용할 것인지이다.
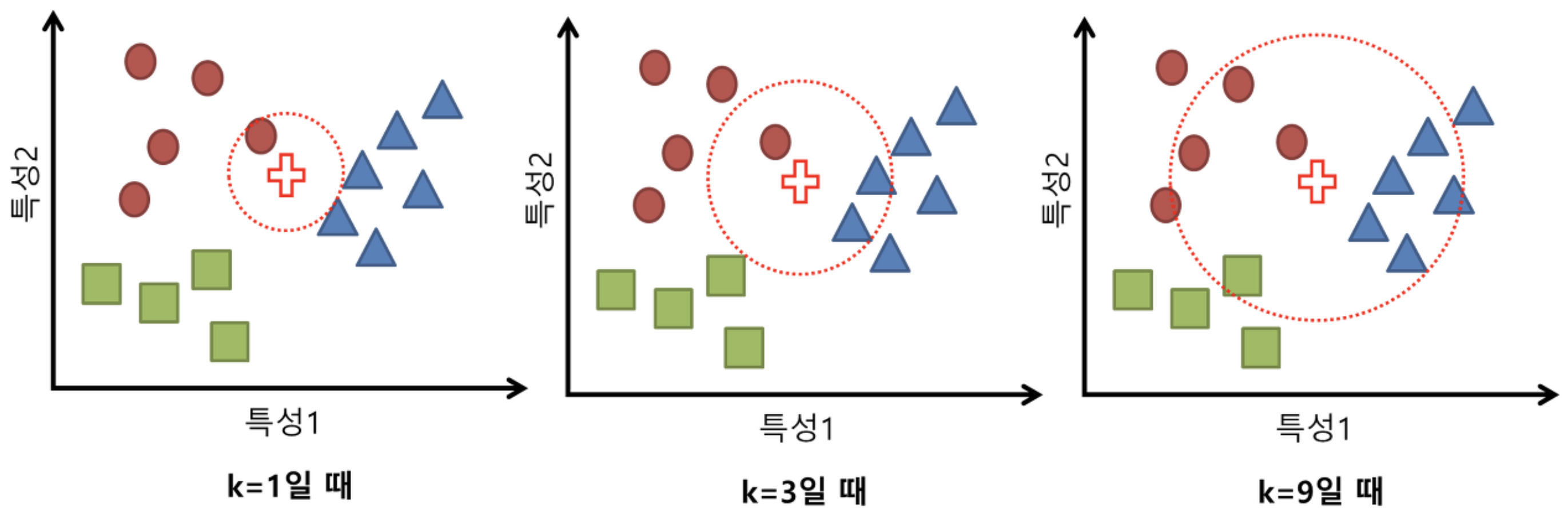
- K가 1이면 테스트 데이터로부터 가장 가까운 훈련 데이터 1개만을 이용한다는 것이고,
k가 2이면 2개의 데이터
k가 9이면 9개의 데이터를 기반으로 예측한다는 것이다.
(위 그림 참고)
테스트 데이터의 클래스를 예측하기 위해서, K의 개수 가장 가까운 훈련 데이터의 클래스 수를 세고, 가장 많이 나온 클래스가 테스트 데이터의 종속변수 Y가 된다.
가장 가까운 K개 만큼의 훈련 데이터를 이용한다고 했다.
Test 데이터로부터 어떤 Train 데이터가 가장 가까운지 판단할까?
거리 계산
Test 데이터의 Label을 예측하기 위해서, 가장 가까운 K개 만큼의 Test 데이터와 Train 데이터 사이의 거리를 계산해야한다.
1. 유클리디언 거리
유클리디언 거리 (Euclidean Distance)
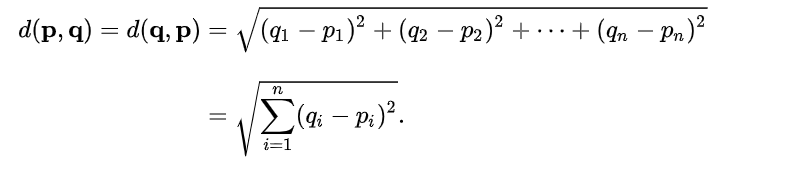
거리를 측정할때 대표적으로 가장 많이 사용되는 방법이다.
점과 점 사이의 거리를 측정할 때 이용된다. (최단 직선 거리)
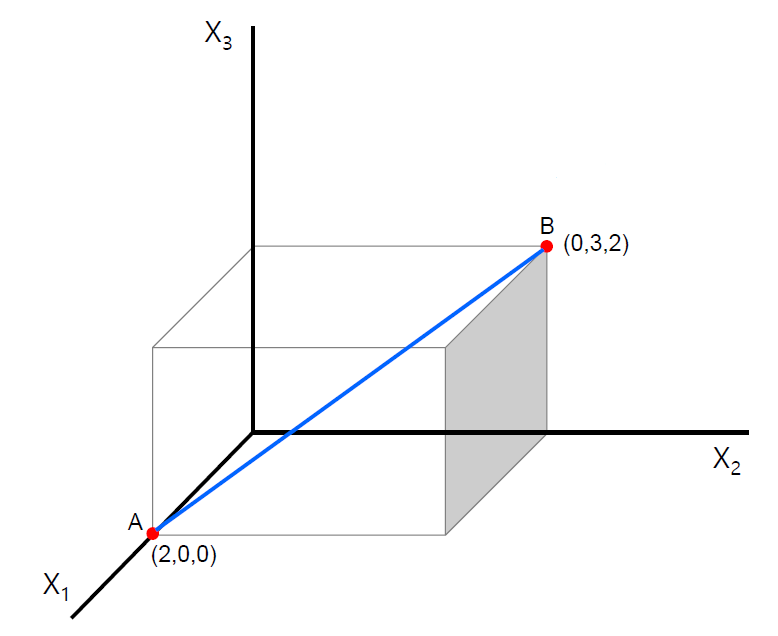
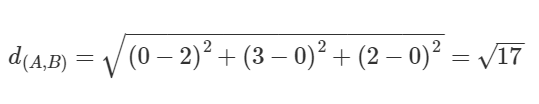
- 두 점의 좌표 차의 제곱합을 루트 씌운 것과 같다.
2. 맨하탄 거리
다음 그림을 보면 4가지 경로로 길을 갔다.
초록색이 유클리디언 거리로 구한 최단 직선거리이다.
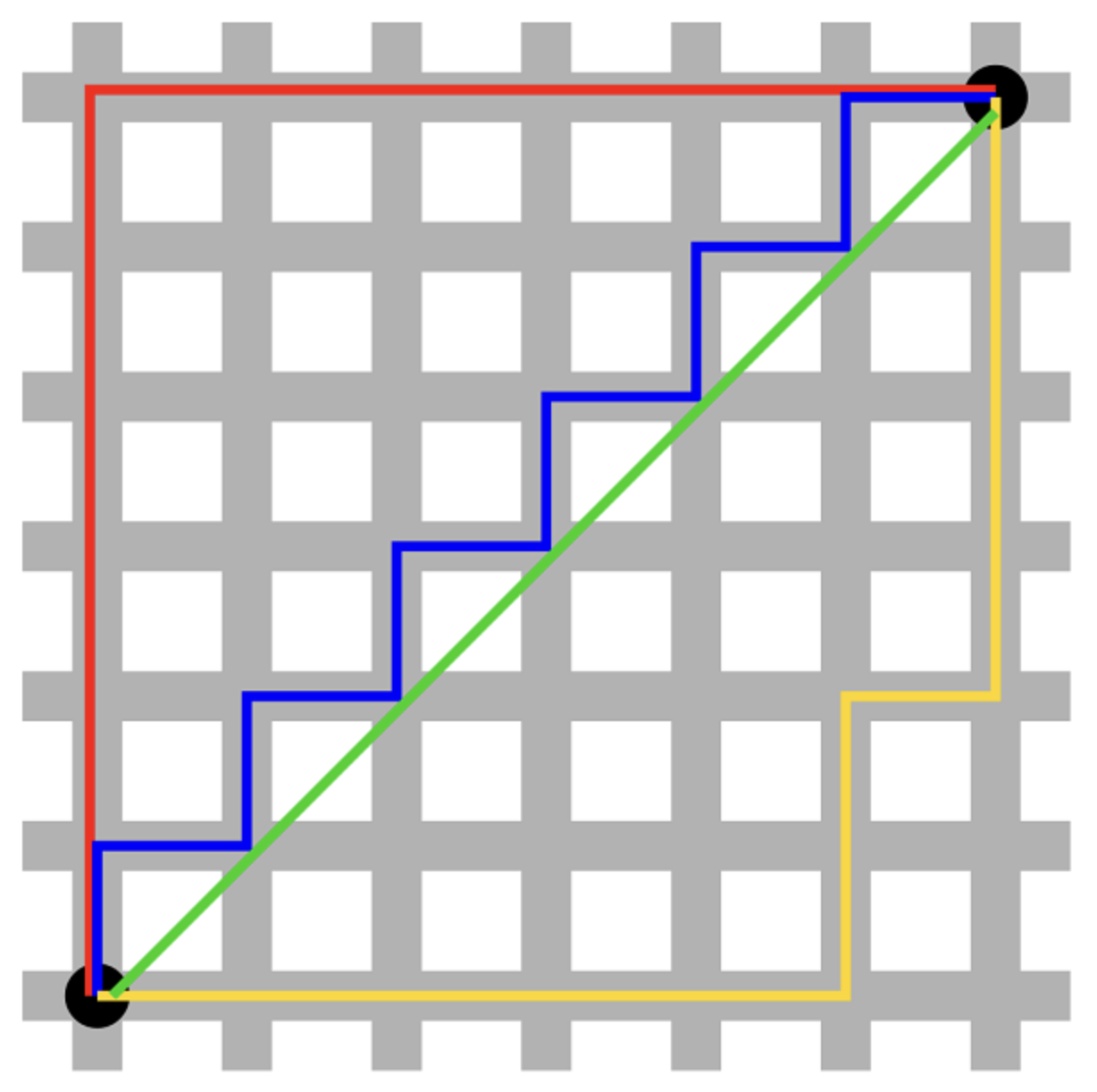
그럼 초록색을 제외하고 무슨색 선이 최단 거리일까?
파란색 선이 초록과 가장 인접해 있기 때문에 최단거리 처럼 보이지만,
-> 정답은 빨,파,노란색 모두 동일한 거리라는 것이다.
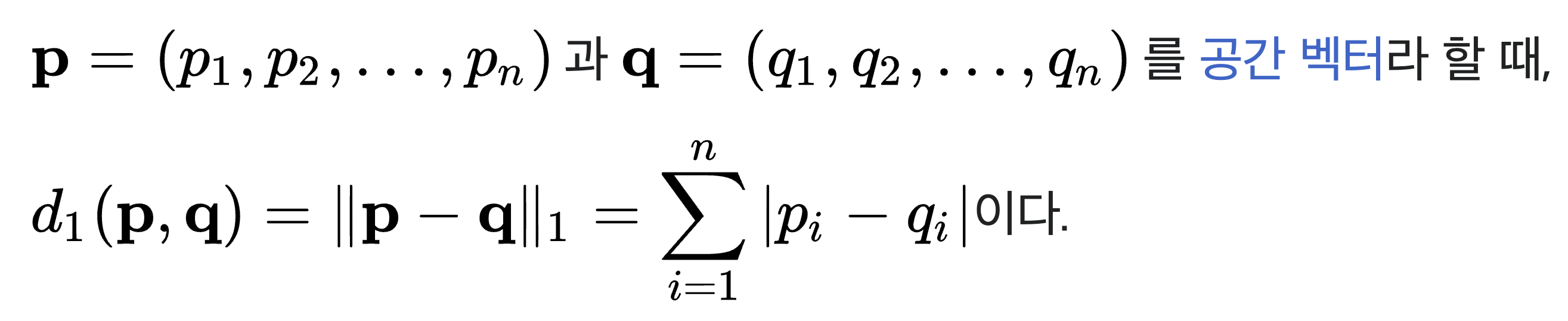
맨하탄 거리식에 의하면 x축, y축 각각 지나간 거리는 모두 같기 때문에 총 거리도 같다는 것이다.
최적의 K (GridSearchCV를 통한 최적의 K 값)
K개를 지정하고 거리를 구했으니, 이제 예측을 할 수 있다.
하지만 KNN은 K값에 따라서 예측 결과에 큰 영향을 미치므로, 적절한 K값을 잘 선택해야한다.
K 값이 너무 작으면?
너무 적은 수의 데이터의 값만 참고하기 때문에, 이상치에 민감하다.
세세한 데이터 하나하나에 Fitting되기 때문에 오버피팅 되었다고 볼 수도 있다.
K값이 너무 크면?
많은 데이터를 참고하기 때문에, 이상치에 덜 민감하다.
하지만 너무 많은 데이터를 참고해서 언더피팅이 일어날 수 있다.
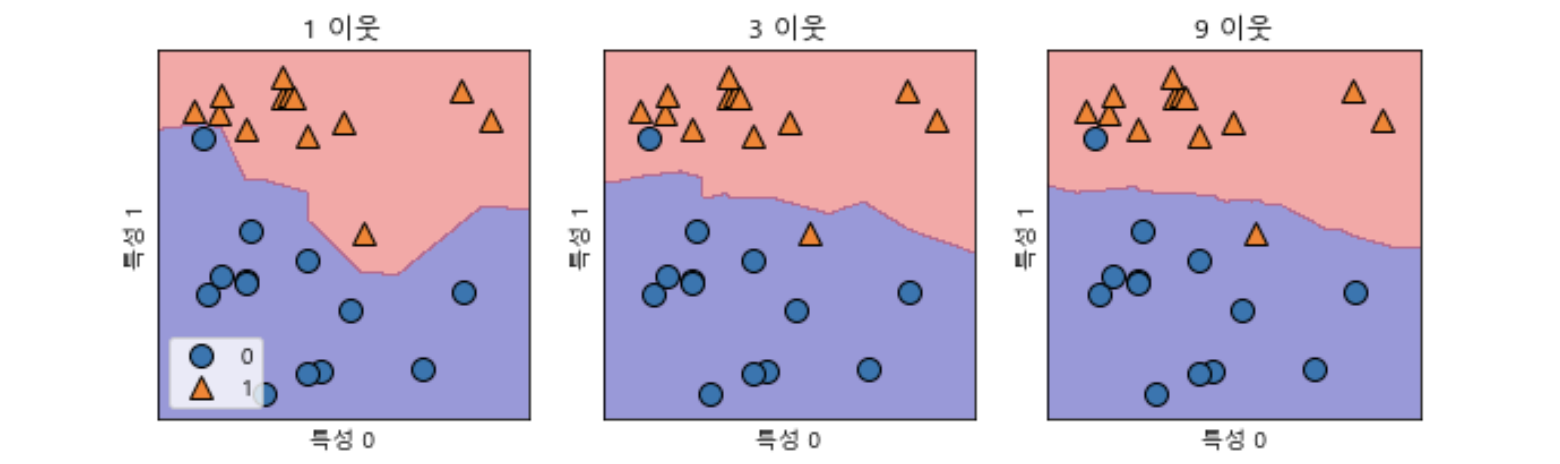
K가 커질수록 더 완만한 Decision Boundary가 형성된다.
최적을 k를 찾기 위한 GridsearchCV
그리드 서치 교차검증을 통해 Validation data에서 가장 높은 성능을 내는 파라미터 K값을 찾을 수 있다.
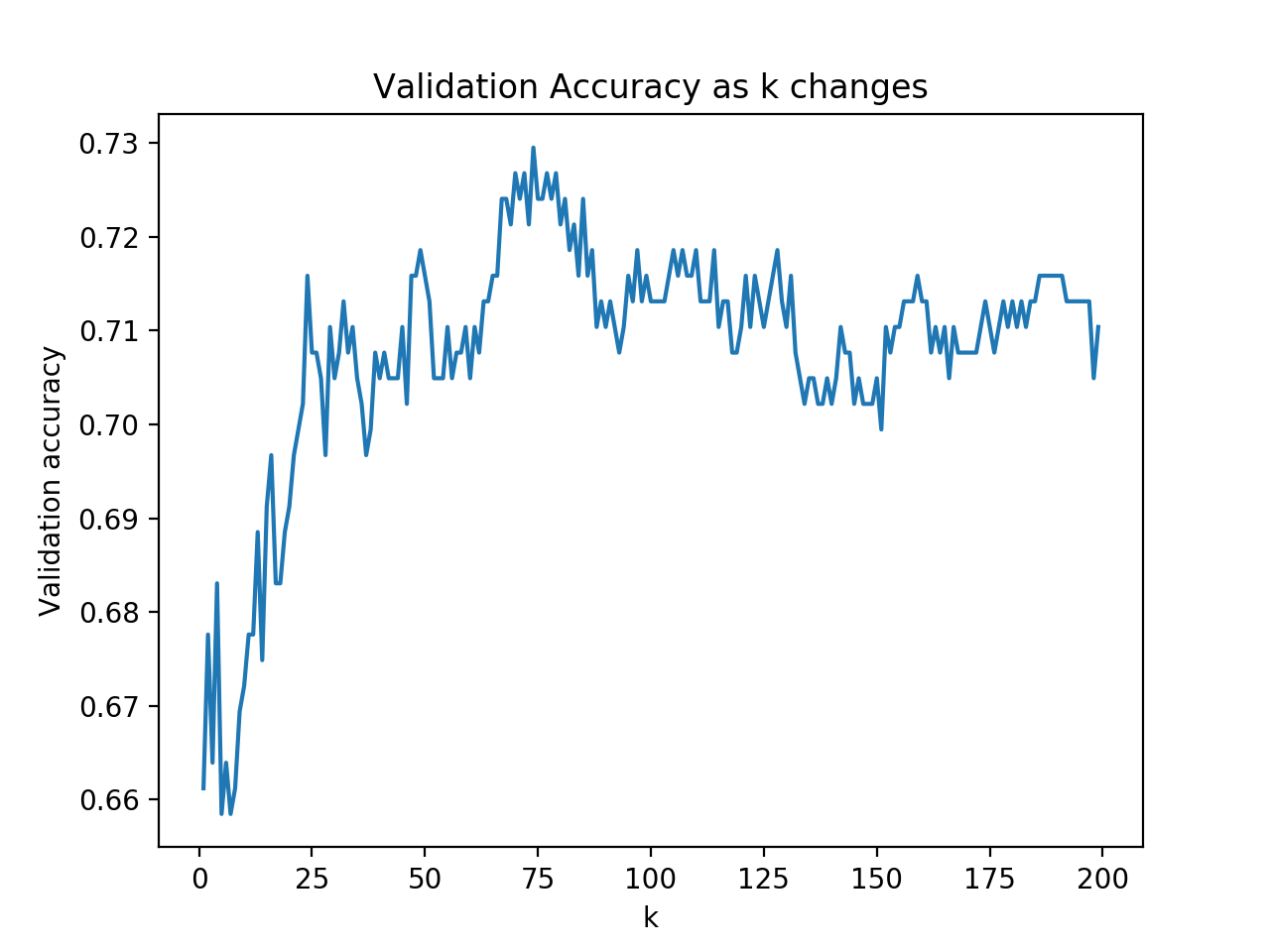
K에 따른 validation 정확도를 나타낸 것이다.
위 그래프에서는,
- k가 1~10 정도 일때는 Underfitting으로 정확도가 65% 정도로 낮을 것을 볼 수 있다.
- K가 100을 넘어가면 Overfitting되어 정확도가 70% 정도로 떨어진다.
- k가 75정도일 때, ACC가 73% 정도로 가장 높으니 적절한 k값이라고 볼 수 있다.
모델 기반 학습 vs 인스턴스 기반 학습
Model based learning

- 분류/ 예측 모델을 만들고 Test 데이터를 넣어 예측을 진행한다.
- 모델을 미리 학습시켜야한다.
Instance based learning

- 모델을 미리 학습시키는 것이 아닌, 예측 진행 시점에 Train 데이터(인스턴스)를 참고하여 연산 후 예측한다.
KNN 특징
- 모델 기반 학습을 하지 않고, 인스턴스 기반 학습을 통해 예측을 하기 때문에, 모델을 만들지 않는다.
- 학습 데이터의 차원과 K 값이 예측 결과에 영향을 많이 미친다.
- 지도 학습 알고리즘이다. (정답 레이블을 가지고 학습)
이미지 출처
https://gomguard.tistory.com/51
https://eunsukimme.github.io/ml/2019/10/20/KNN-classification/
